나이브 베이즈 (Naive Bayes)
이 글은 2018~2019년에 작성한 R 기반 강의 노트를 옮긴 것입니다. 코드 일부는 현재 패키지 버전과 다를 수 있습니다.
이번 포스팅에서는 분류모형 두 번째 소개로 나이브 베이즈 (Naive Bayes)에 대해서 알아보겠습니다. 나이브 베이즈는 베이즈 정리를 이용한 알고리즘입니다. 베이즈 정리는 조건부 확률을 활용한 것이죠. 일단 조건부 확률과 베이즈 정리에 대해서 간단하게 살펴보겠습니다.
조건부 확률 (Conditional Probability)
조건부 확률은 어떤 사건 A가 일어났을 때 B가 일어날 확률을 의미합니다. 사건 B가 발생활 확률은 사건 A의 영향을 받아 변하는데 이를 조건부 확률이라고 합니다.[1] 조건부 확률을 수식으로 표현하면 아래와 같습니다.
\[P(B|A) = \frac {P(A \cap B)} {P(A)}\]만약 사건 A와 사건 B가 서로 독립이라고 하면 두 확률의 곱은 교집합(곱사건)일 확률과 같습니다.
\[P(A) \times P(B) = P(A \cap B)\]예를 들어, 주사위를 던지는 게임을 한다고 가정했을 때 2의 배수가 나올 확률은 1/2이고, 3의 배수가 나올 확률은 1/3입니다. 그리고 이 두 사건의 교집합의 원소는 6밖에 없으므로 확률은 1/6이 됩니다. 이렇게 간단한 예를 통해 두 사건이 독립이라는 것이 어떤 의미인지 알 수 있습니다.
따라서 두 사건이 독립일 때 조건부 확률을 이용하면 다음과 같은 관계가 성립됩니다.
\[P(A|B) = \frac {P(A \cap B)} {P(B)} = \frac {P(A) \times P(B)} {P(B)} = P(A)\] \[P(B|A) = \frac {P(A \cap B)} {P(A)} = \frac {P(A) \times P(B)} {P(A)} = P(B)\]베이즈 정리 (Bayes’ Theorem)
베이즈 정리는 두 확률변수의 사전확률과 사후확률 사이의 관계를 나타내는 정리입니다.[2] 사건 A와 B의 곱사건일 확률은 조건부 확률을 이용하여 아래와 같이 두 개의 식으로 표현할 수 있습니다.
\[P(A \cap B) = P(A) \times P(B|A)\] \[P(A \cap B) = P(B) \times P(A|B)\]두 식의 우항이 서로 같다는 것을 이용한 것이 베이즈 정리입니다.
\[P(A) \times P(B|A) = P(B) \times P(A|B)\] \[\therefore P(A|B) = \frac{P(A) \times P(B|A)} {P(B)}\] \[\begin{cases} P(A|B): \text{B일 때, A의 사후확률 (Posterior Probability)} \\ P(A): \text{A의 사전확률 (Prior Probability, Evidence)} \\ P(B|A): \text{A일 때, B의 가능도 (Likelihood)} \\ P(B): \text{정규화 상수 (Normalized Constant)} \\ \end{cases}\]베이즈 정리를 처음 공부할 때 생소한 용어 때문에 막히는 경우가 있는 것 같습니다. (제가 그랬거든요. 후후) 익숙해질 때까지 반복해서 노출시킨다 생각하고 4가지 용어에 대해서 살펴보겠습니다.
- 사후확률은 우리가 알고자 하는 확률입니다. 사건 B가 일어났을 때 A일 조건부 확률이죠.
- 사전확률은 우리가 (경험적으로) 이미 알고 있는 확률입니다.
- 가능도는 표본으로부터 모수를 추정하는 것인데, 여기에서는 B가 주어졌을 때 A일 가능도를 의미합니다. (A와 B의 순서에 주의하세요!)
- 정규화 상수는 우항의 분자(사전확률과 가능도의 곱)를 전체집합이 아닌 부분집합 B로 압축하는 것을 의미합니다.
수식과 글로는 이해하기 어려우니 그림을 통해 베이즈 정리를 이해해보도록 하죠.
 [3]
[3]
위 그림에서 큰 직사각형을 전체집합이라고 하면, 전체집합은 A1, A2, A3, … , An이라는 n개의 부분집합의 합인 것을 알 수 있습니다. 그리고 역시 부분집합인 B가 여러 개의 A에 걸쳐 있다고 할 때, 예컨데 전체집합에서 A2일 확률과 집합 B에 속하면서 A2일 사후확률은 서로 다를 것입니다.
영화로 예를 들어보죠. 영화의 장르를 전체집합이라고 할 때, 액션(A1), 드라마(A2), 로맨스(A3), 코미디(A4) 등 n개의 부분집합으로 이루어져 있을 것입니다. 이런 가정 하에서 어떤 영화평을 읽었는데 만약 그 영화평에서 ‘사랑’이라는 단어가 사용되었다면, 그 영화의 장르는 ‘액션’에 가까울까요? 아니면 ‘로맨스’에 가까울까요?
상식적으로는 ‘로맨스’에 가깝겠죠? 베이즈 정리를 활용하면 ‘액션’일 사후확률과 ‘로맨스’일 사후확률을 계산할 수 있습니다. 영화평이 쓰여진 전체 영화 목록을 다 가져와서 장르별로 개수를 세면 각 장르별 사전확률을 알 수 있습니다. 그리고 각 장르별로 영화평에 쓰여진 단어(이 예시에서는 ‘사랑’)별 조건부 확률도 알 수 있습니다. 정규화 상수는 전체 영화평에서 ‘사랑’이라는 단어가 사용된 확률이 되겠죠. 이 세 가지를 가지고 영화평에서 ‘사랑’이라는 단어가 사용되었을 때 각 장르별 사후확률을 계산할 수 있는 것입니다.
다시 그림으로 돌아가서, 우리는 앞에서 A1의 장르를 ‘액션’이라고 가정했는데 전체 영화 장르 중에서 ‘액션’은 분명히 있습니다. 그렇죠? 그런데, 영화평에서 ‘사랑’이라는 단어가 사용(사건 B)되었을 때, A1과 B가 겹치는 부분이 없습니다. ‘사랑’이라는 단어가 영화평에 쓰였을 때 ‘액션’ 영화일 사후확률이 0이라는 것이죠.
베이즈 정리에 대해서 조금 더 가까워지셨나요? 잘 전달되었다면 다행이겠으나 그렇지 않다면 제가 설명을 제대로 못 한 것이니 너무 답답해하지 마시고, 다른 좋은 자료를 찾아 구글의 세계로 잠시 다녀오시지요.
나이브 베이즈 알고리즘
이제 부분집합 B가 여러 개인 베이즈 정리를 살펴볼 때가 왔습니다. 예컨데 영화평에서 ‘사랑’이라는 단어가 몇 번, ‘감동’이라는 단어가 몇 번, 이런 식으로 B가 여러 개일 때 각 장르별 사후확률을 계산한다고 생각하는 것이 타당합니다. 수식으로는 아래와 같이 표현할 수 있습니다. A는 Class의 ‘C’로, B는 입력변수를 의미하는 ‘x’로 바꿔서 표기하겠습니다.
\[P(C_k|x_1, x_2, ⋯, x_p) = P(C_k) P(x_1, x_2, ⋯, x_p|C_k)\]위 식에서 정규화 상수가 빠졌는데요. 그 이유는 입력변수(영화평에 쓰인 단어)들이 주어졌을 때 특정 영화 장르일 사후확률값 그 자체를 아는 것보다 각각의 사후확률의 크기를 비교하는 것으로도 충분하기 때문입니다. 따라서 오른쪽 항의 분모는 상수이고, 모든 식에서 같은 크기로 사용되므로 제외하는 것입니다.
오른쪽 항의 조건부 확률이 꽤 복잡하게 생겼는데요. ‘나이브(Naive)’는 ‘단순한’, ‘순진한’의 뜻으로, 모든 입력변수(특성)이 서로 독립이라고 가정합니다. 사실 말이 안 되는 것이지만, 그렇게 가정하는 것입니다. ‘사랑’과 ‘감동’이 한 영화평에서 서로 독립적으로 발생한다고 생각하지는 않습니다만, 상호작용을 고려하면 수식이 매우매우 복잡해지기 때문에 ‘이 두 가지는 서로 독립이야’라고 하는거죠. 그렇게 하면 아래와 같이 식이 단순해집니다.
\[P(x_1, x_2, \cdots, x_p|C_k) = P(x_1|C_k) \times P(x_2|C_k) \times \cdots \times P(x_p|C_k) = \prod_{i=1}^{p} P(x_i|C_k)\] \[\therefore P(C_k|x_1, x_2, \cdots, x_p) = P(C_k) \prod_{i=1}^{p} P(x_i|C_k)\]나이브 베이즈 예시[4]
아래 표와 같이 5행으로 된 영화평 데이터가 있다고 가정하고, 나이브 베이즈 알고리즘을 활용하여 영화 장르를 분류하는 모형을 만들어보겠습니다.
| 구분 | 장르 | 영화평(단어) |
|---|---|---|
| 1 | 코미디 | 재미있는, 연인, 사랑, 사랑 |
| 2 | 액션 | 빠른, 맹렬한, 총격 |
| 3 | 코미디 | 연인, 날으는, 빠른, 재미있는, 재미있는 |
| 4 | 액션 | 맹렬한, 총격, 총격, 재미있는 |
| 5 | 액션 | 날으는, 빠른, 총격, 사랑 |
이제 ‘재미있는, 맹렬한, 빠른’이라는 세 가지 단어로 구성된 영화평 데이터로 영화 장르를 분류하겠습니다. 각 장르별로 영화평에 적힌 단어수를 세어 정리하면 다음과 같습니다.
- 코미디에 쓰인 단어는 총 9개이며, 그 중 ‘재미있는’ 3개, ‘맹렬한’ 0개, 그리고 ‘빠른’ 1개입니다.
- 액션에 쓰인 단어는 총 11이며, 그 중 ‘재미있는’ 1개, ‘맹렬한’ 2개, 그리고 ‘빠른’ 2개입니다.
위에서 정리한 내용을 가지고, 새로운 영화평이 주어졌을 때 코미디 또는 액션일 사후확률을 계산해보겠습니다.
- 코미디일 사후확률
- 액션일 사후확률
위와 같이 영화평이 주어졌을 때 코미디일 사후확률은 0이고 액션을 사후확률은 0.0018이므로 새로운 영화평은 액션 영화로 분류됩니다.
라플라스 스무딩 (Laplace Smoothing)
위의 예제를 보면 ‘맹렬한’이라는 단어가 코미디 장르에 쓰이지 않았기 때문에 사후확률이 0이 되었습니다. 만약 ‘맹렬한’을 제외하고 2개의 단어로만 계산했다면 어떤 결과가 나왔을까요? 그 때는 ‘코미디’가 더 높은 사후확률값을 갖습니다.
나이브 베이즈 알고리즘은 훈련용 데이터에 포함되지 않은 특성(입력변수)이 추가되면 결과값(사후확률)은 모두 0으로 반환합니다. 이런 문제를 해결하기 위해 라플라스 스무딩 기법을 추가해주어야 합니다. 방법은 어렵지 않습니다. 각 특성별 사후확률을 계산할 때 아래 식과 같이 분자에 모두 +1을, 분모에는 중복을 제거한 단어의 종류(V)의 절대값을 더해줍니다.
\[P(x_i|C_k) = \frac {C_k \text{일 때 } x_i \text{의 개수} + 1} {C_k \text{일 때 } \mathbb {x} \text{의 개수} + |V|}\]분자는 i번째 단어를 의미하고 분모는 전체 단어를 갖는 벡터를 의미합니다. 이번 예제에서 전체 단어의 종류는 [재미있는, 연인, 사랑, 빠른, 맹렬한, 총격, 날으는]으로 모두 7개입니다. 이제 라플라스 스무딩을 활용하여 위의 예제에서 분자에는 +1, 분모에는 +7을 더하여 사후확률을 계산해보겠습니다.
- 코미디일 사후확률 (라플라스 스무딩 적용)
- 액션일 사후확률 (라플라스 스무딩 적용)
‘액션’의 사후확률이 더 높게 나왔으나 ‘코미디’의 사후확률이 더이상 0이 아니라는 것을 알 수 있었습니다.
이 외에도 입력변수의 개수가 많을 경우, 0~1 값을 갖는 확률의 곱은 0으로 수렴하는 문제가 발생합니다. 이런 문제도 라플라스 스무딩을 통해 해결할 수 있습니다.
나이브 베이즈 따라하기
우리는 mlbench 패키지의 내장 데이터인 HouseVotes84를 가지고 나이브 베이즈를 활용한 분류모형을 적합하는 실습을 해보겠습니다. 이 데이터는 1984년에 실시된 16가지 주요 안건에 대한 미의회 투표 기록 데이터로 투표 결과에 따라 민주당원(A Democrat)인지 아니면 공화당원(A Republican)인지를 추정하는 분류모형을 만들 수 있습니다.
데이터를 불러온 후 데이터의 구조를 확인하고 미리보기 합니다.
# 데이터를 불러옵니다.
data(HouseVotes84, package = 'mlbench')
# 데이터의 구조를 확인합니다.
str(object = HouseVotes84)
## 'data.frame': 435 obs. of 17 variables:
## $ Class: Factor w/ 2 levels "democrat","republican": 2 2 1 1 1 1 1 2 2 1 ...
## $ V1 : Factor w/ 2 levels "n","y": 1 1 NA 1 2 1 1 1 1 2 ...
## $ V2 : Factor w/ 2 levels "n","y": 2 2 2 2 2 2 2 2 2 2 ...
## $ V3 : Factor w/ 2 levels "n","y": 1 1 2 2 2 2 1 1 1 2 ...
## $ V4 : Factor w/ 2 levels "n","y": 2 2 NA 1 1 1 2 2 2 1 ...
## $ V5 : Factor w/ 2 levels "n","y": 2 2 2 NA 2 2 2 2 2 1 ...
## $ V6 : Factor w/ 2 levels "n","y": 2 2 2 2 2 2 2 2 2 1 ...
## $ V7 : Factor w/ 2 levels "n","y": 1 1 1 1 1 1 1 1 1 2 ...
## $ V8 : Factor w/ 2 levels "n","y": 1 1 1 1 1 1 1 1 1 2 ...
## $ V9 : Factor w/ 2 levels "n","y": 1 1 1 1 1 1 1 1 1 2 ...
## $ V10 : Factor w/ 2 levels "n","y": 2 1 1 1 1 1 1 1 1 1 ...
## $ V11 : Factor w/ 2 levels "n","y": NA 1 2 2 2 1 1 1 1 1 ...
## $ V12 : Factor w/ 2 levels "n","y": 2 2 1 1 NA 1 1 1 2 1 ...
## $ V13 : Factor w/ 2 levels "n","y": 2 2 2 2 2 2 NA 2 2 1 ...
## $ V14 : Factor w/ 2 levels "n","y": 2 2 2 1 2 2 2 2 2 1 ...
## $ V15 : Factor w/ 2 levels "n","y": 1 1 1 1 2 2 2 NA 1 NA ...
## $ V16 : Factor w/ 2 levels "n","y": 2 NA 1 2 2 2 2 2 2 NA ...
# 미리보기 합니다.
head(x = HouseVotes84, n = 10L)
## Class V1 V2 V3 V4 V5 V6 V7 V8 V9 V10 V11 V12 V13 V14 V15
## 1 republican n y n y y y n n n y <NA> y y y n
## 2 republican n y n y y y n n n n n y y y n
## 3 democrat <NA> y y <NA> y y n n n n y n y y n
## 4 democrat n y y n <NA> y n n n n y n y n n
## 5 democrat y y y n y y n n n n y <NA> y y y
## 6 democrat n y y n y y n n n n n n y y y
## 7 democrat n y n y y y n n n n n n <NA> y y
## 8 republican n y n y y y n n n n n n y y <NA>
## 9 republican n y n y y y n n n n n y y y n
## 10 democrat y y y n n n y y y n n n n n <NA>
## V16
## 1 y
## 2 <NA>
## 3 n
## 4 y
## 5 y
## 6 y
## 7 y
## 8 y
## 9 y
## 10 <NA>
435행, 17열로 된 데이터 프레임입니다. 모든 컬럼이 범주형 벡터입니다. 중간에 NA도 보이는군요. 어디가나 출석하지 않는 국회의원들이 존재하는군요. 데이터 컬럼별 상세 내용은 다음과 같습니다.
- Class: democrat, republican
- V01 (장애아동) : y, n
- V02 (물프로젝트 비용 분담) : y, n
- V03 (예산안 채택) : y, n
- V04 (의료수가 동결) : y, n
- V05 (엘살바도르 원조) : y, n
- V06 (학교내 종교단체) : y, n
- V07 (반위성 조사 금지) : y, n
- V08 (콘트라 반군 원조) : y, n
- V09 (MX 미사일) : y, n
- V10 (이민) : y, n
- V11 (합성연료 감축) : y, n
- V12 (교육비 지출) : y, n
- V13 (슈퍼펀드 청구권) : y, n
- V14 (범죄) : y, n
- V15 (면제 수출) : y, n
- V16 (수출행정법) : y, n
민주당원과 공화당원의 비중, 즉 사전확률은 어떨까요?
# 목표변수의 비중을 확인합니다.
HouseVotes84$Class %>% table() %>% prop.table()
## .
## democrat republican
## 0.6137931 0.3862069
민주당원이 약 61.4%, 공화당원이 약 38.6%입니다. 전체 데이터를 70:30의 비중으로 훈련용 데이터셋과 시험용 데이터셋으로 나누도록 하겠습니다.
# 전체 데이터셋의 70%를 훈련용, 30%를 시험용 데이터로 분리합니다.
# 같은 결과를 얻기 위해 seed를 설정합니다.
set.seed(seed = 1)
# 전체 데이터를 임의로 샘플링하기 위해 다음과 같이 처리합니다.
idx <- sample(x = 2, size = nrow(x = HouseVotes84), prob = c(0.7, 0.3), replace = TRUE)
# idx가 1일 때 trainSet, 2일 때 testSet에 할당합니다.
trainSet <- HouseVotes84[idx == 1, ]
testSet <- HouseVotes84[idx == 2, ]
# 훈련용, 시험용 데이터셋의 목표변수 비중을 확인합니다.
trainSet$Class %>% table() %>% prop.table()
## .
## democrat republican
## 0.6123779 0.3876221
testSet$Class %>% table() %>% prop.table()
## .
## democrat republican
## 0.6171875 0.3828125
훈련용 데이터셋에는 민주당원의 비중이 미세하고 낮고, 시험용 데이터셋에는 미세하게 높지만 전체 데이터와의 차이가 없다고 가정하고 훈련용 데이터셋으로 나이브 베이즈 분류모형을 만드는 실습을 하겠습니다. 먼저 관련 함수에 대해 알아보아야 되겠죠? 나이브 베이즈는 e1071 패키지의 naiveBayes() 함수를 사용합니다. 역시 아주 쉽습니다. 이 함수의 주요 인자는 다음과 같습니다.
x: 입력변수 특성을 할당합니다. 숫자형 행렬이나 범주형/숫자형 벡터로 이루어진 데이터 프레임을 할당하면 됩니다.y: 종속변수를 할당합니다. 범주형 벡터로 할당하면 됩니다.formula: 종속변수와 입력변수 간 관계식을 표기합니다. 데이터 인자에 할당된 종속변수y와 나머지 모든 변수를 입력변수로 할당하려면y ~ .와 같이 표기하면 됩니다.data: 숫자형/범주형 벡터로 이루어진 데이터 프레임을 할당합니다.laplace: 라플라스 스무딩에 사용될 값을 추가합니다. 기본값은 0이며, 앞에서 다룬 예제는 1을 입력한 것과 같습니다.
# 필요 패키지를 불러옵니다.
library(e1071)
라플라스 스무딩을 적용하기 전 분류모형 적합
# 라플라스 스무딩을 적용하기 전 분류모형을 적합합니다.
fitL0 <- naiveBayes(formula = Class ~ ., data = trainSet, laplace = 0)
# fitL0 객체의 속성을 확인합니다.
class(x = fitL0)
## [1] "naiveBayes"
# fitL0 객체의 구조를 확인합니다.
str(object = fitL0)
## List of 4
## $ apriori: 'table' int [1:2(1d)] 188 119
## ..- attr(*, "dimnames")=List of 1
## .. ..$ Y: chr [1:2] "democrat" "republican"
## $ tables :List of 16
## ..$ V1 : 'table' num [1:2, 1:2] 0.389 0.829 0.611 0.171
## .. ..- attr(*, "dimnames")=List of 2
## .. .. ..$ Y : chr [1:2] "democrat" "republican"
## .. .. ..$ V1: chr [1:2] "n" "y"
## ..$ V2 : 'table' num [1:2, 1:2] 0.515 0.505 0.485 0.495
## .. ..- attr(*, "dimnames")=List of 2
## .. .. ..$ Y : chr [1:2] "democrat" "republican"
## .. .. ..$ V2: chr [1:2] "n" "y"
## ..$ V3 : 'table' num [1:2, 1:2] 0.0934 0.8793 0.9066 0.1207
## .. ..- attr(*, "dimnames")=List of 2
## .. .. ..$ Y : chr [1:2] "democrat" "republican"
## .. .. ..$ V3: chr [1:2] "n" "y"
## ..$ V4 : 'table' num [1:2, 1:2] 0.9611 0 0.0389 1
## .. ..- attr(*, "dimnames")=List of 2
## .. .. ..$ Y : chr [1:2] "democrat" "republican"
## .. .. ..$ V4: chr [1:2] "n" "y"
## ..$ V5 : 'table' num [1:2, 1:2] 0.8034 0.0431 0.1966 0.9569
## .. ..- attr(*, "dimnames")=List of 2
## .. .. ..$ Y : chr [1:2] "democrat" "republican"
## .. .. ..$ V5: chr [1:2] "n" "y"
## ..$ V6 : 'table' num [1:2, 1:2] 0.514 0.111 0.486 0.889
## .. ..- attr(*, "dimnames")=List of 2
## .. .. ..$ Y : chr [1:2] "democrat" "republican"
## .. .. ..$ V6: chr [1:2] "n" "y"
## ..$ V7 : 'table' num [1:2, 1:2] 0.215 0.754 0.785 0.246
## .. ..- attr(*, "dimnames")=List of 2
## .. .. ..$ Y : chr [1:2] "democrat" "republican"
## .. .. ..$ V7: chr [1:2] "n" "y"
## ..$ V8 : 'table' num [1:2, 1:2] 0.157 0.855 0.843 0.145
## .. ..- attr(*, "dimnames")=List of 2
## .. .. ..$ Y : chr [1:2] "democrat" "republican"
## .. .. ..$ V8: chr [1:2] "n" "y"
## ..$ V9 : 'table' num [1:2, 1:2] 0.242 0.897 0.758 0.103
## .. ..- attr(*, "dimnames")=List of 2
## .. .. ..$ Y : chr [1:2] "democrat" "republican"
## .. .. ..$ V9: chr [1:2] "n" "y"
## ..$ V10: 'table' num [1:2, 1:2] 0.514 0.457 0.486 0.543
## .. ..- attr(*, "dimnames")=List of 2
## .. .. ..$ Y : chr [1:2] "democrat" "republican"
## .. .. ..$ V10: chr [1:2] "n" "y"
## ..$ V11: 'table' num [1:2, 1:2] 0.466 0.866 0.534 0.134
## .. ..- attr(*, "dimnames")=List of 2
## .. .. ..$ Y : chr [1:2] "democrat" "republican"
## .. .. ..$ V11: chr [1:2] "n" "y"
## ..$ V12: 'table' num [1:2, 1:2] 0.861 0.153 0.139 0.847
## .. ..- attr(*, "dimnames")=List of 2
## .. .. ..$ Y : chr [1:2] "democrat" "republican"
## .. .. ..$ V12: chr [1:2] "n" "y"
## ..$ V13: 'table' num [1:2, 1:2] 0.713 0.14 0.287 0.86
## .. ..- attr(*, "dimnames")=List of 2
## .. .. ..$ Y : chr [1:2] "democrat" "republican"
## .. .. ..$ V13: chr [1:2] "n" "y"
## ..$ V14: 'table' num [1:2, 1:2] 0.6389 0.0263 0.3611 0.9737
## .. ..- attr(*, "dimnames")=List of 2
## .. .. ..$ Y : chr [1:2] "democrat" "republican"
## .. .. ..$ V14: chr [1:2] "n" "y"
## ..$ V15: 'table' num [1:2, 1:2] 0.347 0.882 0.653 0.118
## .. ..- attr(*, "dimnames")=List of 2
## .. .. ..$ Y : chr [1:2] "democrat" "republican"
## .. .. ..$ V15: chr [1:2] "n" "y"
## ..$ V16: 'table' num [1:2, 1:2] 0.0543 0.3137 0.9457 0.6863
## .. ..- attr(*, "dimnames")=List of 2
## .. .. ..$ Y : chr [1:2] "democrat" "republican"
## .. .. ..$ V16: chr [1:2] "n" "y"
## $ levels : chr [1:2] "democrat" "republican"
## $ call : language naiveBayes.default(x = X, y = Y, laplace = laplace)
## - attr(*, "class")= chr "naiveBayes"
나이브 베이즈 분류모형을 적합한 결과 객체는 naiveBayes라는 속성을 가지고 있지만, 실제로는 4개의 원소로 이루어진 리스트형 자료이며, tables 원소에 16개의 입력변수(특성)에 관한 사후확률이 포함되어 있습니다. 이것은 무엇을 의미할까요? 바로 나이브 베이즈 알고리즘에서 오른쪽 항의 조건부 확률을 의미합니다. 우리가 이 분류모형을 통해 알고자 하는 것은 16개 투표 결과로 이 국회의원이 민주당원인지 공화당원인지 여부(사후확률)입니다. 그렇죠? 사전확률은 이미 확인하였고, 방금 출력된 분류모형의 결과가 바로 가능도입니다. 이 중에서 2개만 미리보기 해보겠습니다.
# 모형 적합 결과를 일부 출력합니다.
print(fitL0$tables[1:2])
## $V1
## V1
## Y n y
## democrat 0.3888889 0.6111111
## republican 0.8290598 0.1709402
##
## $V2
## V2
## Y n y
## democrat 0.5147929 0.4852071
## republican 0.5046729 0.4953271
V1 (장애아동) 항목에 대한 사후확률을 살펴보니, 민주당원이라면 y로 투표할 사후확률이 0.6111111인 반면, 공화당원이라면 0.1709402가 됩니다. 그리고 V2 (물프로젝트 비용 부담) 항목의 경우, 민주당원이라면 y로 투표할 사후확률이 0.4852071이고, 공화당원이라면 0.4953271이 되는 것이죠. 앞에서 나이브 베이즈 알고리즘을 설명할 때 가능도를 모두 곱했던 것 기억하시죠? 사전확률에 16가지 가능도를 모두 곱하면 사후확률이 계산되는 것입니다. 확률은 0~1 값을 가지므로 곱을 거듭할수록 숫자가 매우 작아지게 되므로 양변에 로그를 취하면 곱을 합으로 바꿀 수 있어 계산하기 편하게 되는 것이죠. 계산은 컴퓨터가 해주는 것이니 굳이 로그를 취하지 않아도 되겠죠.
그런데 실제로 사후확률이 제대로 계산되었는지 직접구해보겠습니다. table() 함수와 prop.table(margin = 1)를 활용하면 손쉽게 구할 수 있습니다.
# 실제로 V1 항목에 대한 각각의 사후확률이 맞는지 직접 계산해보겠습니다.
table(trainSet$Class, trainSet$V1) %>% prop.table(margin = 1)
##
## n y
## democrat 0.3888889 0.6111111
## republican 0.8290598 0.1709402
똑같은 결과를 얻을 수 있음을 확인했습니다.
다음으로 넘어가서, 방금 적합한 분류모형으로 훈련용 데이터셋 307명의 국회의원에 대한 추정 레이블(predict label)을 구하고, 혼동행렬과 ROC 커브를 통해 분류 성능을 확인해보겠습니다.
# 훈련용 데이터셋으로 분류모형의 추정 레이블을 확인합니다.
trPredL0 <- predict(object = fitL0, newdata = trainSet)
# 미리보기 합니다.
head(x = trPredL0, n = 10L)
## [1] republican republican republican democrat republican republican
## [7] democrat republican republican democrat
## Levels: democrat republican
# 혼동행렬에 필요한 패키지를 불러옵니다.
library(caret)
# 라플라스 스무딩을 적용하지 않은 모형의 혼동행렬 지표들을 확인합니다.
confusionMatrix(data = trPredL0, reference = trainSet$Class)
## Confusion Matrix and Statistics
##
## Reference
## Prediction democrat republican
## democrat 172 9
## republican 16 110
##
## Accuracy : 0.9186
## 95% CI : (0.8821, 0.9466)
## No Information Rate : 0.6124
## P-Value [Acc > NIR] : <2e-16
##
## Kappa : 0.8303
## Mcnemar's Test P-Value : 0.2301
##
## Sensitivity : 0.9149
## Specificity : 0.9244
## Pos Pred Value : 0.9503
## Neg Pred Value : 0.8730
## Prevalence : 0.6124
## Detection Rate : 0.5603
## Detection Prevalence : 0.5896
## Balanced Accuracy : 0.9196
##
## 'Positive' Class : democrat
##
비록 쉬운 예제(Toy Example)이긴 하지만 분류모형 적합 결과가 매우 좋습니다. 일단 positive 범주가 ‘democrat’인 것을 확인한 후 지표를 살펴보니, 민감도가 0.9149이고 특이도가 0.9244입니다. ROC 커브가 왼쪽 상단 모서리에 가깝게 그려질 것 같습니다. 정밀도 역시 0.9503로 매우 높으니 F1 점수도 아주 높게 나올 것 같습니다. 말이 나온 김에 F1 점수를 확인해보죠.
# F1 점수에 필요 패키지를 불러옵니다.
library(MLmetrics)
# 라플라스 스무딩을 적용하지 않은 모형의 추정 레이블과 실제값으로 F1 점수를 확인합니다.
F1_Score(y_pred = trPredL0, y_true = trainSet$Class)
## [1] 0.9322493
예상대로 F1 점수가 0.9322493으로 아주 높은 값이 출력되었습니다. ROC 커브와 AUROC는 어떨까요? 앞으로 자주 쓰일 것 같으니 ROC 커브를 그리고 AUROC를 구하는 사용자 정의 함수를 만들어보겠습니다.
# ROC 커브를 그리고, AUROC를 계산하는 사용자 정의 함수를 만듭니다.
checkROC <- function(prob, real, title = 'ROC 커브') {
# ROC 커브에 필요 패키지를 불러옵니다.
library(ROCR)
# 추정값이 범주형인 경우, 숫자 벡터로 변환합니다.
if(class(x = prob) == 'factor') prob <- as.numeric(x = prob)
# ROC 커브를 그려서 분류 성능을 확인합니다.
predObj <- prediction(predictions = prob,
labels = real)
# prediction 객체를 활용하여 performance 객체를 생성합니다.
perform <- performance(prediction.obj = predObj,
measure = 'tpr',
x.measure = 'fpr')
# 한글이 제대로 출력되도록 설정합니다.
par(family = 'NanumGothic')
# ROC 커브를 그립니다.
plot(x = perform, main = title)
# 왼쪽 아래 모서리에서 오른쪽 위 모서리를 잇는 대각선을 추가합니다.
lines(x = c(0, 1), y = c(0, 1), col = 'red', lty = 2)
# AUROC에 필요 패키지를 불러옵니다.
library(pROC)
# AUROC를 계산하고 ROC 커브 위에 출력합니다.
auroc <- auc(real, prob) %>% round(digits = 4L)
text(x = 0.9, y = 0, labels = str_c('AUROC : ', auroc), col = 'red')
}
라플라스 스무딩 적용하지 않은 모형의 훈련용 데이터셋으로 ROC 커브를 그리고 AUROC를 출력합니다.
# ROC 커브를 그리고 AUROC를 출력합니다.
checkROC(prob = trPredL0,
real = trainSet$Class,
title = 'ROC 커브 - 라플라스 스무딩 적용하지 않은 모형 (훈련셋)')
## Loading required package: gplots
##
## Attaching package: 'gplots'
## The following object is masked from 'package:stats':
##
## lowess
## Type 'citation("pROC")' for a citation.
##
## Attaching package: 'pROC'
## The following objects are masked from 'package:stats':
##
## cov, smooth, var
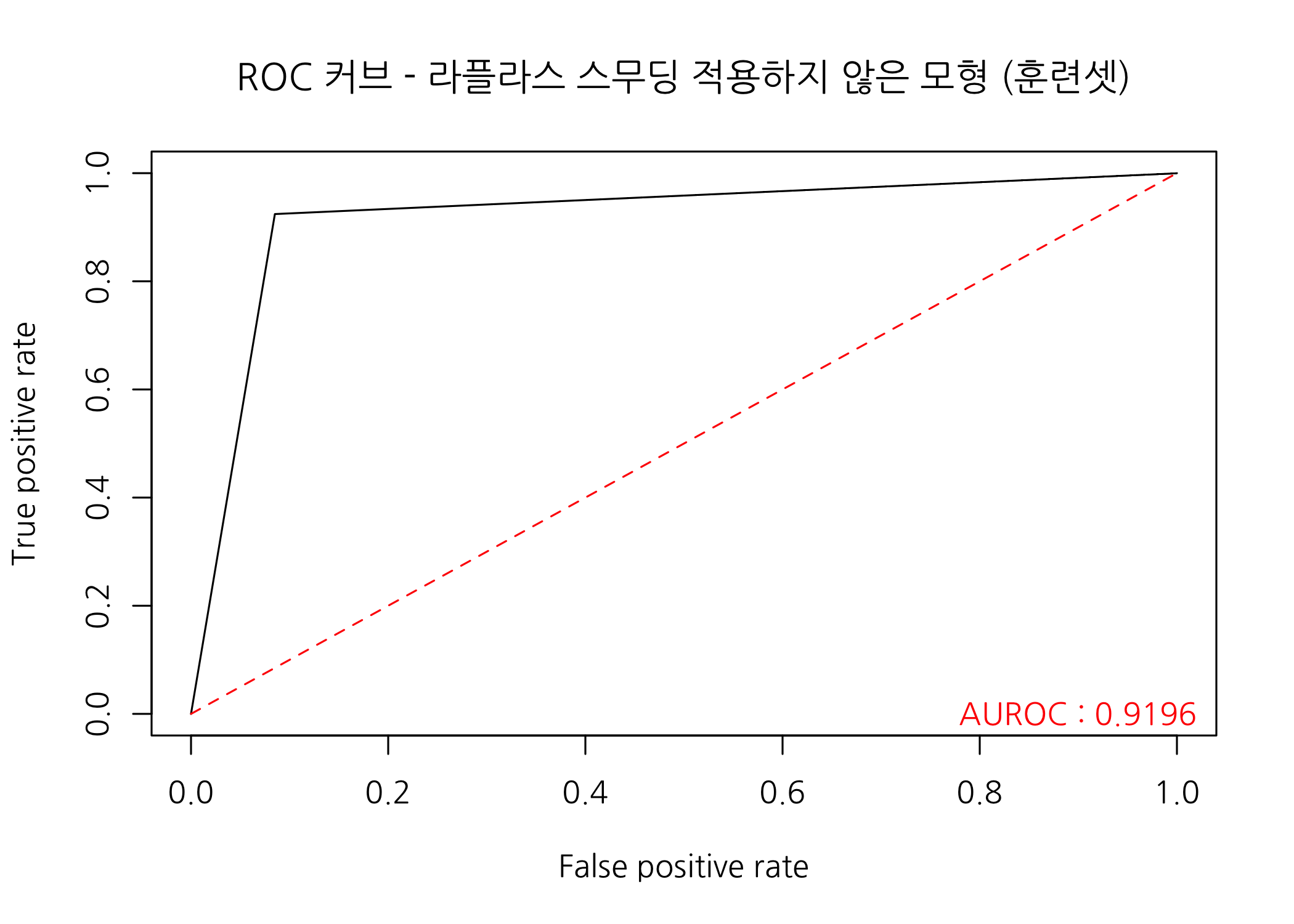
ROC 커브 역시 예상대로 왼쪽 상단 모서리에 가깝게 그려졌고, AUROC도 0.9196이라는 높은 값이 나왔습니다. 그런데 ROC 커브가 여전히 곡선보다는 꺽인 직선 모양이라 그다지 예쁘지는 않습니다. 사후확률의 추정 레이블 대신 연속형 확률값을 사용하면 좀 더 매끈한 곡선처럼 그릴 수 있습니다. AUROC도 더 커질 것이구요.
사후확률 추정값을 각각 구해보겠습니다.
# 분류모형의 사후확률 추정값을 계산합니다.
trProbL0 <- predict(object = fitL0, newdata = trainSet, type = 'raw')
# 새로 생성한 컬럼의 속성을 확인합니다.
class(x = trProbL0)
## [1] "matrix"
# 미리보기 합니다.
head(x = trProbL0, n = 10L)
## democrat republican
## [1,] 0.00000004677796 0.999999953222038940
## [2,] 0.00000002293080 0.999999977069200408
## [3,] 0.00389140408710 0.996108595912898909
## [4,] 0.99627202007395 0.003727979926047030
## [5,] 0.00000275815155 0.999997241848445295
## [6,] 0.00000003160032 0.999999968399682193
## [7,] 0.99999999999491 0.000000000005094578
## [8,] 0.00000038019219 0.999999619807810936
## [9,] 0.00000263425427 0.999997365745727063
## [10,] 0.99999999940778 0.000000000592221585
이제 ROC 커브를 그리고 AUROC를 구해보겠습니다.
# ROC 커브를 그리고 AUROC를 출력합니다.
# [주의] trProdL0이 행렬인 것을 감안하여야 합니다.
checkROC(prob = trProbL0[, 2],
real = trainSet$Class,
title = 'ROC 커브 - 라플라스 스무딩 적용하지 않은 모형 (훈련셋)')
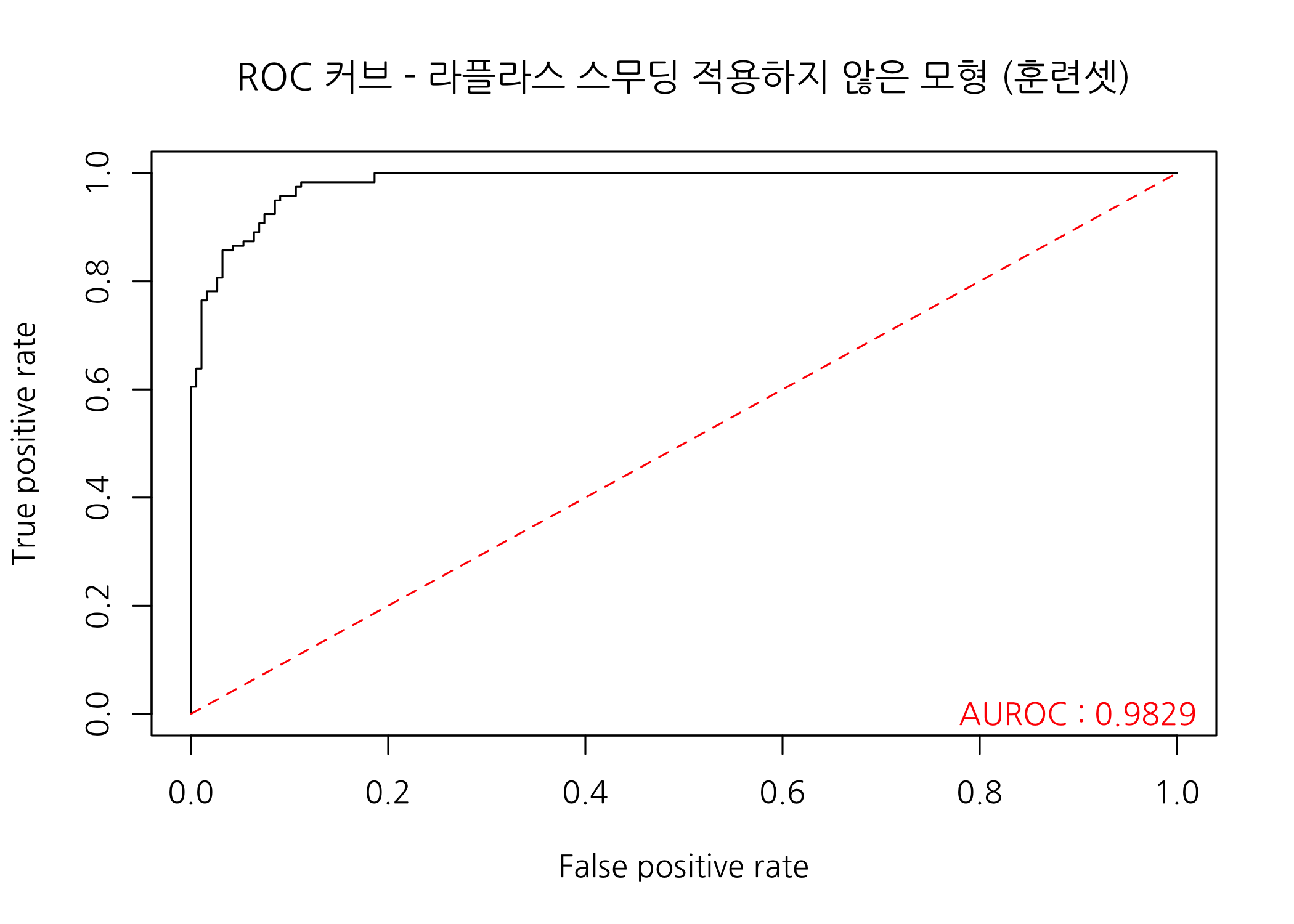
ROC 커브가 더욱 매끄럽게 그려지고, AUROC 또한 0.9829로 최대값인 1에 가까워졌습니다. 시험셋을 적용해보면 어떨까요? 차이가 많이 나면 과적합되었다는 것을 의미합니다.
# 시험용 데이터셋으로 분류모형의 추정 레이블을 확인합니다.
tePredL0 <- predict(object = fitL0, newdata = testSet)
# 라플라스 스무딩을 적용하지 않은 모형의 혼동행렬 지표들을 확인합니다.
confusionMatrix(data = tePredL0, reference = testSet$Class)
## Confusion Matrix and Statistics
##
## Reference
## Prediction democrat republican
## democrat 69 4
## republican 10 45
##
## Accuracy : 0.8906
## 95% CI : (0.8233, 0.9389)
## No Information Rate : 0.6172
## P-Value [Acc > NIR] : 0.000000000004005
##
## Kappa : 0.7738
## Mcnemar's Test P-Value : 0.1814
##
## Sensitivity : 0.8734
## Specificity : 0.9184
## Pos Pred Value : 0.9452
## Neg Pred Value : 0.8182
## Prevalence : 0.6172
## Detection Rate : 0.5391
## Detection Prevalence : 0.5703
## Balanced Accuracy : 0.8959
##
## 'Positive' Class : democrat
##
민감도가 0.8734, 특이도가 0.9184, 정밀도가 0.9452로 훈련용 데이터셋과 큰 차이를 보이지 않습니다.
# 라플라스 스무딩을 적용하지 않은 모형의 추정 레이블과 실제값으로 F1 점수를 확인합니다.
F1_Score(y_pred = tePredL0, y_true = testSet$Class)
## [1] 0.9078947
F1 점수도 0.9078947로 여전히 높게 나왔구요.
# 분류모형의 사후확률 추정값을 계산합니다.
# [주의] 이렇게 하는 경우, trainSet의 probL0 컬럼에는 매트릭스가 할당됩니다.
teProbL0 <- predict(object = fitL0, newdata = testSet, type = 'raw')
# 미리보기 합니다.
head(x = teProbL0, n = 10L)
## democrat republican
## [1,] 0.9997763478535 0.00022365214652916789
## [2,] 0.9638223162090 0.03617768379102025839
## [3,] 0.0000457353687 0.99995426463129177819
## [4,] 0.0000001855101 0.99999981448994379463
## [5,] 0.9999998148987 0.00000018510132781037
## [6,] 0.9999999999900 0.00000000000999376147
## [7,] 0.9999999999999 0.00000000000009037084
## [8,] 0.9999999999886 0.00000000001137084100
## [9,] 0.0199827554190 0.98001724458104821913
## [10,] 0.9999999999993 0.00000000000066888936
# ROC 커브를 그리고 AUROC를 출력합니다.
# [주의] prodL0이 행렬인 것을 감안하여야 합니다.
checkROC(prob = teProbL0[, 2],
real = testSet$Class,
title = 'ROC 커브 - 라플라스 스무딩 적용하지 않은 모형 (시험셋)')
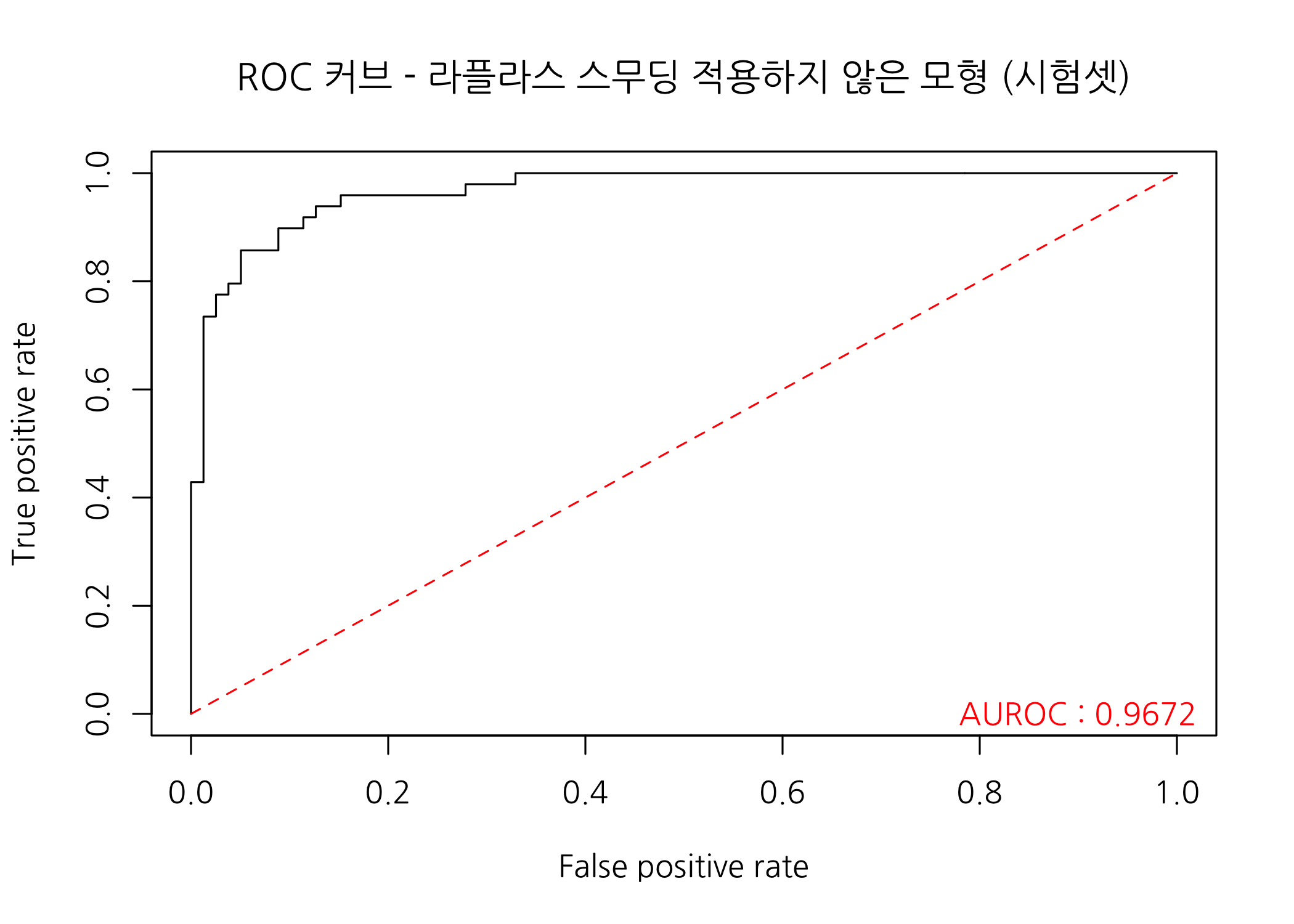
ROC 커브도 매끄럽게 잘 그려졌고, AUROC도 0.9672로 여전히 높게 나왔습니다. 전체적으로 모든 지표에서 조금씩 숫자가 작아지긴 했지만, 큰 차이를 보이지 않는다고 할 수 있습니다.
라플라스 스무딩을 적용한 분류모형 적합
이번에는 라플라스 스무딩 기법을 적용하도록 하겠습니다. naiveBayes() 함수의 laplace 인자에 1을 할당해보겠습니다.
# 라플라스 스무딩을 적용하기 전 분류모형을 적합합니다.
fitL1 <- naiveBayes(formula = Class ~ ., data = trainSet, laplace = 1)
# fitL1 객체의 속성을 확인합니다.
class(x = fitL1)
## [1] "naiveBayes"
# fitL1 객체의 구조를 확인합니다.
str(object = fitL1)
## List of 4
## $ apriori: 'table' int [1:2(1d)] 188 119
## ..- attr(*, "dimnames")=List of 1
## .. ..$ Y: chr [1:2] "democrat" "republican"
## $ tables :List of 16
## ..$ V1 : 'table' num [1:2, 1:2] 0.39 0.824 0.61 0.176
## .. ..- attr(*, "dimnames")=List of 2
## .. .. ..$ Y : chr [1:2] "democrat" "republican"
## .. .. ..$ V1: chr [1:2] "n" "y"
## ..$ V2 : 'table' num [1:2, 1:2] 0.515 0.505 0.485 0.495
## .. ..- attr(*, "dimnames")=List of 2
## .. .. ..$ Y : chr [1:2] "democrat" "republican"
## .. .. ..$ V2: chr [1:2] "n" "y"
## ..$ V3 : 'table' num [1:2, 1:2] 0.0978 0.8729 0.9022 0.1271
## .. ..- attr(*, "dimnames")=List of 2
## .. .. ..$ Y : chr [1:2] "democrat" "republican"
## .. .. ..$ V3: chr [1:2] "n" "y"
## ..$ V4 : 'table' num [1:2, 1:2] 0.95604 0.00847 0.04396 0.99153
## .. ..- attr(*, "dimnames")=List of 2
## .. .. ..$ Y : chr [1:2] "democrat" "republican"
## .. .. ..$ V4: chr [1:2] "n" "y"
## ..$ V5 : 'table' num [1:2, 1:2] 0.8 0.0508 0.2 0.9492
## .. ..- attr(*, "dimnames")=List of 2
## .. .. ..$ Y : chr [1:2] "democrat" "republican"
## .. .. ..$ V5: chr [1:2] "n" "y"
## ..$ V6 : 'table' num [1:2, 1:2] 0.514 0.118 0.486 0.882
## .. ..- attr(*, "dimnames")=List of 2
## .. .. ..$ Y : chr [1:2] "democrat" "republican"
## .. .. ..$ V6: chr [1:2] "n" "y"
## ..$ V7 : 'table' num [1:2, 1:2] 0.219 0.75 0.781 0.25
## .. ..- attr(*, "dimnames")=List of 2
## .. .. ..$ Y : chr [1:2] "democrat" "republican"
## .. .. ..$ V7: chr [1:2] "n" "y"
## ..$ V8 : 'table' num [1:2, 1:2] 0.16 0.848 0.84 0.152
## .. ..- attr(*, "dimnames")=List of 2
## .. .. ..$ Y : chr [1:2] "democrat" "republican"
## .. .. ..$ V8: chr [1:2] "n" "y"
## ..$ V9 : 'table' num [1:2, 1:2] 0.244 0.89 0.756 0.11
## .. ..- attr(*, "dimnames")=List of 2
## .. .. ..$ Y : chr [1:2] "democrat" "republican"
## .. .. ..$ V9: chr [1:2] "n" "y"
## ..$ V10: 'table' num [1:2, 1:2] 0.513 0.458 0.487 0.542
## .. ..- attr(*, "dimnames")=List of 2
## .. .. ..$ Y : chr [1:2] "democrat" "republican"
## .. .. ..$ V10: chr [1:2] "n" "y"
## ..$ V11: 'table' num [1:2, 1:2] 0.467 0.86 0.533 0.14
## .. ..- attr(*, "dimnames")=List of 2
## .. .. ..$ Y : chr [1:2] "democrat" "republican"
## .. .. ..$ V11: chr [1:2] "n" "y"
## ..$ V12: 'table' num [1:2, 1:2] 0.857 0.159 0.143 0.841
## .. ..- attr(*, "dimnames")=List of 2
## .. .. ..$ Y : chr [1:2] "democrat" "republican"
## .. .. ..$ V12: chr [1:2] "n" "y"
## ..$ V13: 'table' num [1:2, 1:2] 0.711 0.147 0.289 0.853
## .. ..- attr(*, "dimnames")=List of 2
## .. .. ..$ Y : chr [1:2] "democrat" "republican"
## .. .. ..$ V13: chr [1:2] "n" "y"
## ..$ V14: 'table' num [1:2, 1:2] 0.6374 0.0345 0.3626 0.9655
## .. ..- attr(*, "dimnames")=List of 2
## .. .. ..$ Y : chr [1:2] "democrat" "republican"
## .. .. ..$ V14: chr [1:2] "n" "y"
## ..$ V15: 'table' num [1:2, 1:2] 0.349 0.875 0.651 0.125
## .. ..- attr(*, "dimnames")=List of 2
## .. .. ..$ Y : chr [1:2] "democrat" "republican"
## .. .. ..$ V15: chr [1:2] "n" "y"
## ..$ V16: 'table' num [1:2, 1:2] 0.0611 0.3173 0.9389 0.6827
## .. ..- attr(*, "dimnames")=List of 2
## .. .. ..$ Y : chr [1:2] "democrat" "republican"
## .. .. ..$ V16: chr [1:2] "n" "y"
## $ levels : chr [1:2] "democrat" "republican"
## $ call : language naiveBayes.default(x = X, y = Y, laplace = laplace)
## - attr(*, "class")= chr "naiveBayes"
아직은 차이를 모르겠습니다. 앞에서 했던 것처럼 방금 적합한 분류모형으로 훈련용 데이터셋 307명의 국회의원에 대한 추정 레이블(predict label)을 구하고, 혼동행렬과 ROC 커브를 통해 분류 성능을 확인해보겠습니다.
# 훈련용 데이터셋으로 분류모형의 추정 레이블을 확인합니다.
trPredL1 <- predict(object = fitL1, newdata = trainSet)
# 라플라스 스무딩을 적용한 모형의 혼동행렬 지표들을 확인합니다.
confusionMatrix(data = trPredL1, reference = trainSet$Class)
## Confusion Matrix and Statistics
##
## Reference
## Prediction democrat republican
## democrat 169 9
## republican 19 110
##
## Accuracy : 0.9088
## 95% CI : (0.8709, 0.9385)
## No Information Rate : 0.6124
## P-Value [Acc > NIR] : < 2e-16
##
## Kappa : 0.8108
## Mcnemar's Test P-Value : 0.08897
##
## Sensitivity : 0.8989
## Specificity : 0.9244
## Pos Pred Value : 0.9494
## Neg Pred Value : 0.8527
## Prevalence : 0.6124
## Detection Rate : 0.5505
## Detection Prevalence : 0.5798
## Balanced Accuracy : 0.9117
##
## 'Positive' Class : democrat
##
민감도 0.8989, 특이도 0.9244, 정밀도 0.9494로 라플라스 스무딩 적용하지 않은 모형보다 조금씩 낮게 나왔습니다.
# 라플라스 스무딩을 적용하지 않은 모형의 추정 레이블과 실제값으로 F1 점수를 확인합니다.
F1_Score(y_pred = trPredL1, y_true = trainSet$Class)
## [1] 0.9234973
F1 점수도 0.9234973로 조금 낮게 출력되었구요.
사후확률 추정값을 계산하고 ROC 커브를 그려보겠습니다.
# 분류모형의 사후확률 추정값을 계산합니다.
trProbL1 <- predict(object = fitL1, newdata = trainSet, type = 'raw')
# ROC 커브를 그리고 AUROC를 출력합니다.
checkROC(prob = trProbL1[, 2],
real = trainSet$Class,
title = 'ROC 커브 - 라플라스 스무딩 적용한 모형 (훈련셋)')
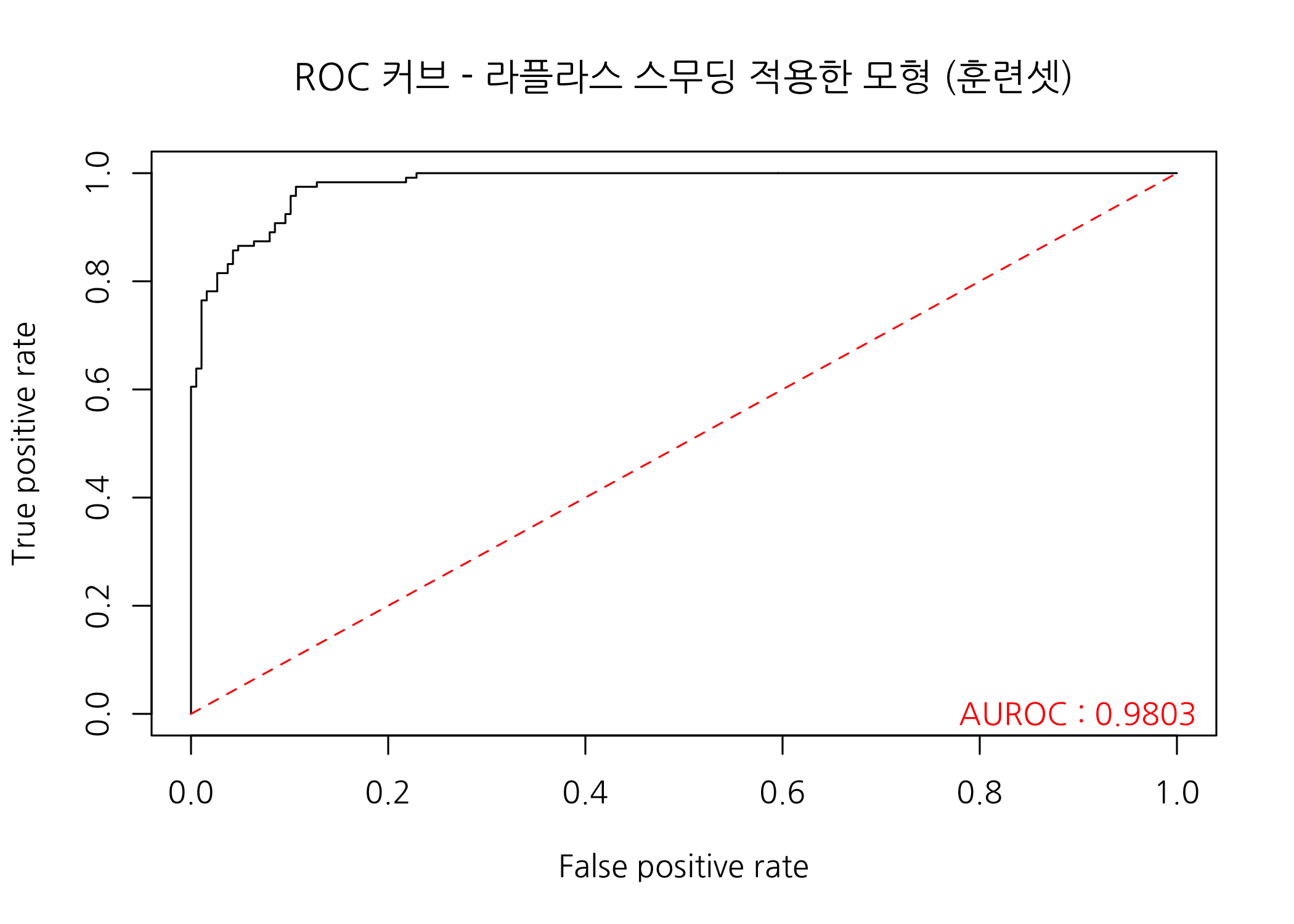
AUROC 역시 조금 낮은 것을 확인할 수 있습니다.
이상으로 나이브 베이즈 알고리즘을 활용한 분류모형 적합 방법에 대해 알아보았습니다.
[1] 자세한 내용은 위키백과를 참조하시기 바랍니다.
[2] 자세한 내용은 위키백과를 참조하시기 바랍니다.
[3] 출처 : http://tendollarbux.com/07/post18/bayes-theorem-venn-diagram/
[4] 출처: http://bcho.tistory.com/1010