K-근접이웃 (K-nearest neighbors)
이 글은 2018~2019년에 작성한 R 기반 강의 노트를 옮긴 것입니다. 코드 일부는 현재 패키지 버전과 다를 수 있습니다.
이전 포스팅에서 기계학습 알고리즘에 대해 간략하게 소개했습니다. 이번 포스팅에서는 목표변수가 있는 지도학습 중 분류(Classification) 모형에 대해 알아보도록 하겠습니다. 분류모형은 목표변수(Target Variable)가 범주형일 때 사용되는 알고리즘입니다. 예를 들어, 신용카드사의 Fraud Detection System와 같이 이상거래를 탐지하는 모형이 분류모형이라고 할 수 있습니다. 이 경우, 목표변수는 이상거래 여부(Yes/No)가 될 것입니다. 목표변수는 방금 예로 든 것과 같이 2가지 범주를 갖는 이진분리와 3개 이상의 범주를 갖는 다지분리로 나눌 수 있습니다. 이 블로그에서는 이진분리를 주로 다루도록 하겠습니다.
(제가 알고 있는 알고리즘 중에서) 분류모형에 사용되는 알고리즘을 열거해보면 다음과 같습니다.
- K-근접이웃 (K-nearest neighbors)
- 나이브 베이즈 (Naive Bayes)
- 의사결정나무 (Decision Tree)
- 로지스틱 회귀분석 (Logistic Regression)
- 랜덤 포레스트 (Random Forest)
- 서포트 벡터 머신 (Support Vector Machine)
K-근접이웃 알고리즘
이 중에서 가장 간단하지만 괜찮은 알고리즘부터 소개해드릴까 합니다. 바로 사례 기반 추론(Case Based Reasoning)에 속하는 K-근접이웃 알고리즘입니다. 위키백과에 따르면, 사례 기반 추론은 과거에 있었던 사례들의 결과를 바탕으로 새로운 사례의 결과를 예측하는 기법입니다.[1] K-근접이웃은 (목표변수가 있는) 기존 데이터와 (목표변수가 없는) 새로운 데이터 간 유사도를 측정하여 가장 가까운 데이터의 목표변수를 기준으로 새로운 데이터의 범주를 추론하는 방법입니다. 데이터 간 유사도는 보통 거리를 많이 사용합니다. 거리를 측정하는 방법에는 맨하탄, 유클리디안, 민코프스키 및 코사인유사도 등이 주로 사용됩니다.
K-근접이웃은 사실 분류모형 뿐만 아니라 회귀모형에도 사용할 수 있는 비모수적 알고리즘입니다. 비모수적이라는 말에서 모집단에 대한 어떠한 가정이 없다는 것을 알 수 있습니다. 즉, 모집단의 형태와 관계 없다는 것이죠. 다만, K-근접이웃은 하나의 관측값(observation)은 거리가 가까운 K개의 이웃 관측값들과 비슷한 특성을 갖는다라고 가정합니다. 따라서 분류모형에서 사용될 경우, K개 이웃의 목표변수 중 다수결로 가장 많은 범주에 속한 값을 결과로 반환합니다. 그리고 회귀모형의 경우, K개 이웃의 목표변수값의 평균을 반환합니다.
 [2]
[2]
그렇기 때문에 KNN 알고리즘에서 가장 중요한 것은 K를 얼마로 설정하느냐에 따라 결과가 달라집니다.
- K를 작은 숫자로 설정하면 참고하는 데이터의 범위가 작아지므로 인접한 소수의 값들에 크게 영향을 받습니다. (이상치에 민감)
- 반대로 K를 큰 숫자로 설정하면 참고하는 데이터의 범위가 커지므로 인접한 값들의 영향도가 감소합니다.
- 일반적으로 훈련용 데이터(Training Dataset) 건수의 제곱근을 사용합니다.
한 가지 추가로 말씀드릴 것은, 인접한 K개의 이웃에 대해 가중치를 부여하거나 부여하지 않을 수 있습니다. 이를테면 거리가 가까울수록 더 긴밀한 관계를 갖는다고 판단이 드는 경우 가까울수록 높은 가중치를 부여하는 것이 좋을 것입니다. 이 때, 가중치로는 거리의 역순을 사용할 수 있습니다.
이제 알고리즘에 대한 설명은 이것으로 마치고 분석 사례로 들어가겠습니다.
K-근접이웃 따라하기
우리는 온라인에 공개된 와인 데이터를 사용하여 와인의 품질을 목표변수로 하는 분류모형을 적합하고자 합니다. 먼저 데이터를 불러온 후 데이터의 구조를 살펴보도록 하겠습니다.
# 데이터를 볼러옵니다.
wine <- read.csv(file = 'https://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-white.csv',
sep = ";")
# 데이터의 구조를 파악합니다.
str(object = wine)
## 'data.frame': 4898 obs. of 12 variables:
## $ fixed.acidity : num 7 6.3 8.1 7.2 7.2 8.1 6.2 7 6.3 8.1 ...
## $ volatile.acidity : num 0.27 0.3 0.28 0.23 0.23 0.28 0.32 0.27 0.3 0.22 ...
## $ citric.acid : num 0.36 0.34 0.4 0.32 0.32 0.4 0.16 0.36 0.34 0.43 ...
## $ residual.sugar : num 20.7 1.6 6.9 8.5 8.5 6.9 7 20.7 1.6 1.5 ...
## $ chlorides : num 0.045 0.049 0.05 0.058 0.058 0.05 0.045 0.045 0.049 0.044 ...
## $ free.sulfur.dioxide : num 45 14 30 47 47 30 30 45 14 28 ...
## $ total.sulfur.dioxide: num 170 132 97 186 186 97 136 170 132 129 ...
## $ density : num 1.001 0.994 0.995 0.996 0.996 ...
## $ pH : num 3 3.3 3.26 3.19 3.19 3.26 3.18 3 3.3 3.22 ...
## $ sulphates : num 0.45 0.49 0.44 0.4 0.4 0.44 0.47 0.45 0.49 0.45 ...
## $ alcohol : num 8.8 9.5 10.1 9.9 9.9 10.1 9.6 8.8 9.5 11 ...
## $ quality : int 6 6 6 6 6 6 6 6 6 6 ...
# 첫 10 행을 미리보기 합니다.
head(x = wine, n = 10L)
## fixed.acidity volatile.acidity citric.acid residual.sugar chlorides
## 1 7.0 0.27 0.36 20.7 0.045
## 2 6.3 0.30 0.34 1.6 0.049
## 3 8.1 0.28 0.40 6.9 0.050
## 4 7.2 0.23 0.32 8.5 0.058
## 5 7.2 0.23 0.32 8.5 0.058
## 6 8.1 0.28 0.40 6.9 0.050
## 7 6.2 0.32 0.16 7.0 0.045
## 8 7.0 0.27 0.36 20.7 0.045
## 9 6.3 0.30 0.34 1.6 0.049
## 10 8.1 0.22 0.43 1.5 0.044
## free.sulfur.dioxide total.sulfur.dioxide density pH sulphates alcohol
## 1 45 170 1.0010 3.00 0.45 8.8
## 2 14 132 0.9940 3.30 0.49 9.5
## 3 30 97 0.9951 3.26 0.44 10.1
## 4 47 186 0.9956 3.19 0.40 9.9
## 5 47 186 0.9956 3.19 0.40 9.9
## 6 30 97 0.9951 3.26 0.44 10.1
## 7 30 136 0.9949 3.18 0.47 9.6
## 8 45 170 1.0010 3.00 0.45 8.8
## 9 14 132 0.9940 3.30 0.49 9.5
## 10 28 129 0.9938 3.22 0.45 11.0
## quality
## 1 6
## 2 6
## 3 6
## 4 6
## 5 6
## 6 6
## 7 6
## 8 6
## 9 6
## 10 6
불러온 데이터는 12개의 컬럼, 4898 행을 갖는 데이터 프레임입니다. 컬럼별 상세는 다음과 같습니다.
- fixed.acidity : 고정 산도
- volatile.acidity : 변동 산도
- citric.acid : 구연산
- residual.sugar : 당도
- chlorides : 염화물
- free.sulfur.dioxide : 이산화황
- total.sulfur.dioxide : 총 이산화황
- density : 밀도(무게감, 바디감)
- pH : 수소이온농도 (낮을수록 산성)
- sulphates : 황산염
- alcohol : 알콜 함유량
- quality : 와인의 품질
맨 마지막 컬럼인 quality만 정수형이고 다른 모든 컬럼들은 숫자형 벡터입니다. 와인의 속성에 해당하는 변수들임을 알 수 있습니다. 분류모형에 사용하려면 범주형 목표변수가 필요한데, 이 데이터에는 범주형 벡터가 없으므로 새로 만들어 주어야 합니다. quality 컬럼을 활용하여 새로운 목표변수를 만들어보도록 하겠습니다. 먼저 데이터의 분포를 확인하겠습니다.
# quality 컬럼의 빈도수를 확인합니다.
table(wine$quality)
##
## 3 4 5 6 7 8 9
## 20 163 1457 2198 880 175 5
# 누적상대도수를 확인합니다.
table(wine$quality) %>%
prop.table() %>%
cumsum() %>%
round(digits = 4L) * 100
## 3 4 5 6 7 8 9
## 0.41 3.74 33.48 78.36 96.33 99.90 100.00
quality 컬럼은 3~9의 값을 갖습니다. 누적상대도수를 확인해보니 3~6점인 건이 전체의 약 78% 정도 됩니다.
# 한글이 제대로 출력되도록 폰트를 설정합니다.
par(family = 'NanumGothic')
# quality 컬럼으로 막대그래프를 그려 분포를 확인합니다.
bp <- barplot(height = table(wine$quality),
ylim = c(0, 2400),
xlab = '와인 품질')
# 빈도수를 추가합니다.
text(x = bp,
y = table(wine$quality),
labels = table(wine$quality),
pos = 3)
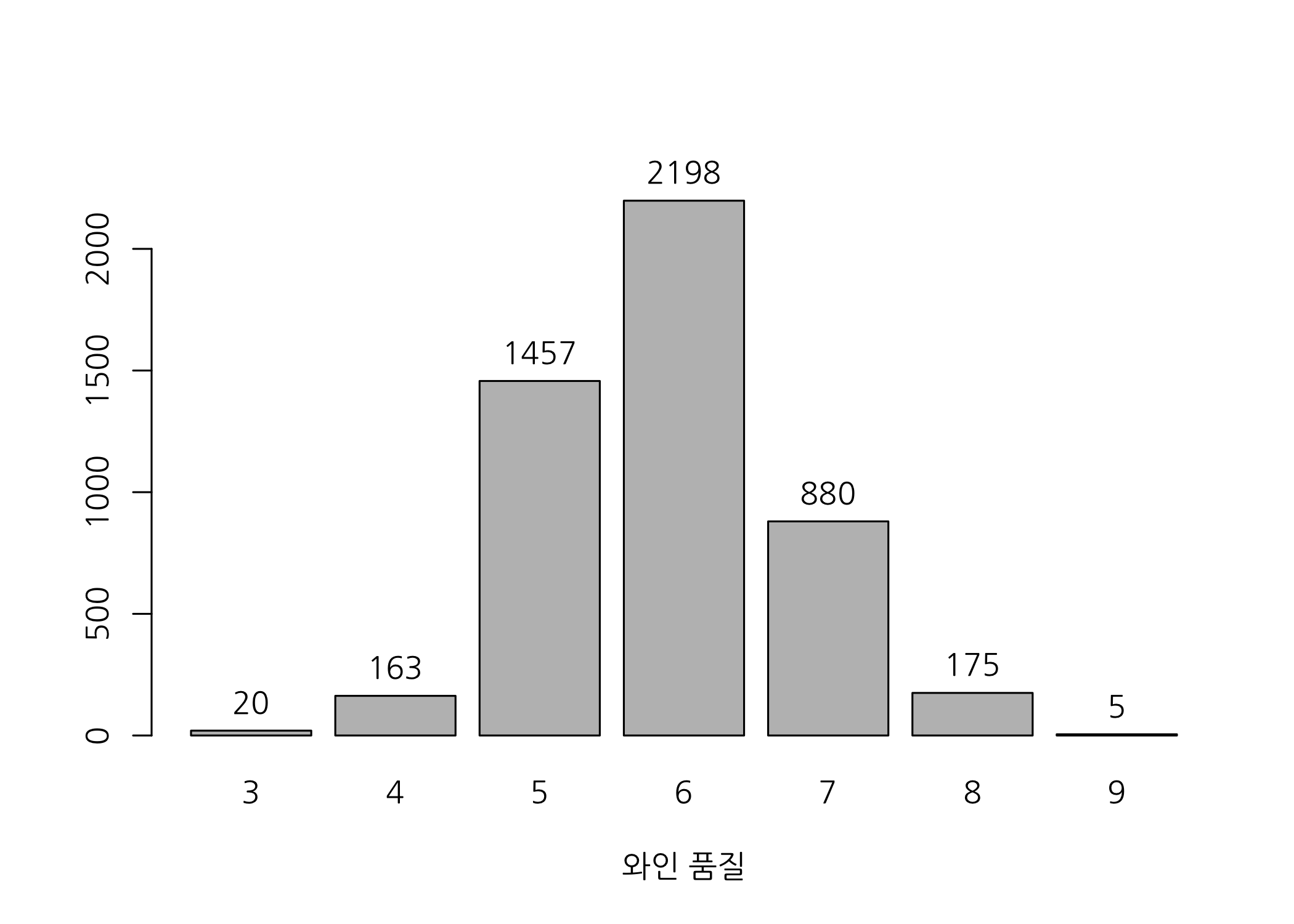
막대그래프로 그려보니 왼쪽으로 치우친 정규분포 형태로 보입니다. 아무튼, quality 컬럼값이 6점 이하면 Good 7점 이상이면 Best의 값을 갖는 목표변수를 새로 만들도록 하겠습니다.
# 목표변수를 새로 만듭니다.
# quality 값이 3~6점이면 'good', 7~9점이면 'best'를 할당합니다.
wine$grade <- ifelse(test = wine$quality >= 7, yes = 'best', no = 'good')
# 새로 만든 목표변수를 범주형으로 변환합니다.
wine$grade <- as.factor(x = wine$grade)
# 새로 만든 목표변수와 기존 품질 컬럼의 빈도수를 확인합니다.
table(wine$grade, wine$quality)
##
## 3 4 5 6 7 8 9
## best 0 0 0 0 880 175 5
## good 20 163 1457 2198 0 0 0
KNN은 데이터 간 유사도를 측정하기 위해 거리를 이용한다고 하였습니다. 거리를 이용할 때 가장 중요한 전처리 작업은 무엇일까요? 바로 표준화입니다. 변수 간 척도(scale)가 다를 때 단위가 큰 변수가 거리에 지배적인(dominant) 영향을 끼칠 수 있기 때문입니다. 표준화를 거치면 모든 변수가 평균이 0, 표준편차가 1인 표준정규분포를 따르게 됩니다. 그럼 표준화를 해보도록 하겠습니다.
# 목표변수를 제외한 나머지 입력변수를 표준화하고 데이터 프레임으로 변환합니다.
wineScaled <- scale(x = wine[, 1:11], center = TRUE, scale = TRUE) %>% as.data.frame()
# 표준화된 데이터에 목표변수를 추가합니다.
wineScaled <- cbind(wineScaled, grade = wine$grade)
scale() 함수를 이용하여 데이터 표준화를 하면 결과 객체가 행렬로 반환됩니다. 그런데 나중에 knn() 함수를 실행하려면 아무래도 데이터 프레임 객체가 더 편리하므로 결과 객체를 변환해줍니다. 데이터 표준화 작업을 할 때 주의할 점은 반드시 숫자 컬럼만 포함해야 한다는 것입니다. 앞에서 새로 만든 목표변수는 표준화 작업이 종료된 후 cbind() 함수로 추가하면 됩니다.
데이터 표준화가 완료되면 이전 포스팅에서 살펴본 바와 같이 자료분할(Hold-out Validation) 방법을 이용하여 전체 데이터를 훈련용(training) 데이터셋과 시험용(test) 데이터셋으로 나눕니다.
이번 예제에서는 전체 데이터의 70%를 훈련용 데이터셋으로 할당하고, 나머지 30%는 시험용 데이터셋으로 할당하겠습니다.
# 전체 데이터셋의 70%를 훈련용, 30%를 시험용 데이터로 분리합니다.
# 같은 결과를 얻기 위해 seed를 설정합니다.
set.seed(seed = 123)
# 전체 데이터를 임의로 샘플링하기 위해 다음과 같이 처리합니다.
idx <- sample(x = 2, size = nrow(x = wineScaled), prob = c(0.7, 0.3), replace = TRUE)
# idx가 1일 때 trainSet, 2일 때 testSet에 할당합니다.
trainSet <- wineScaled[idx == 1, ]
testSet <- wineScaled[idx == 2, ]
sample() 함수에 대해서 간단하게 설명을 하자면 x 인자에 정수 n를 입력하면 1:n과 같은 효과를 가집니다. 그러므로 위와 같이 2를 할당한 경우, x에는 1과 2 두 개의 정수를 갖는 숫자형 벡터가 할당된 것과 마찬가지가 됩니다. size 인자에는 반환할 데이터의 개수를 입력합니다. 이번 예제에서는 wineScaled 데이터의 행 개수를 할당하였습니다. 그 이유는 x 인자에 할당된 1 또는 2를 wineScaled의 행 개수만큼 생성하여 1일 때 trainSet에 할당하고 2일 때 testSet에 할당하기 위함입니다. prob 인자에는 각각의 숫자가 생성될 비중을 지정합니다. 전체 데이터의 70%를 trainSet에 할당하려고 하니 0.7을 넣고, 나머지 30%는 testSet에 할당하기로 하였으니 0.3을 지정합니다. 마지막 replace 인자는 복원추출 여부를 묻는 것입니다. x 인자에 할당된 벡터의 길이(여기에서는 2)가 size에 할당된 숫자(여기에서는 wineScaled 데이터의 행 개수인 4898)보다 작으니 반드시 TRUE를 지정해주어야 합니다. 그렇지 않으면 에러가 발생합니다.
# 훈련용, 시험용 데이터셋의 목표변수 비중을 확인합니다.
trainSet$grade %>% table() %>% prop.table()
## .
## best good
## 0.2102355 0.7897645
testSet$grade %>% table() %>% prop.table()
## .
## best good
## 0.2309801 0.7690199
훈련용 데이터셋과 시험용 데이터셋이 임의로 잘 나뉘었는지 확인해보았습니다. 그럭저럭 비슷한 비중으로 잘 들어가 있습니다. 여기까지 데이터 전처리를 마치고 KNN을 이용한 분류모형을 적합해보겠습니다.
가중치 없는 KNN 분류모형 적합하기
새로운 데이터와 인접 이웃 간 거리와 상관없이 모두 똑같은 비중으로 참조하려면 가중치 없는 분류모형을 적합하면 됩니다. 가중치 없는 KNN 알고리즘은 class 패키지의 knn() 함수를 사용합니다. 주요 인자에 대한 설명을 간단하게 하도록 하겠습니다.
train: 훈련용 데이터셋을 할당합니다. 주의할 점은 입력변수만 포함시켜야 한다는 것입니다.test: 시험용 데이터셋을 할당합니다. 마찬가지로 입력변수만 포함시킵니다.cl: 훈련용 데이터셋의 목표변수를 할당합니다. 범주형 벡터로 할당해야 합니다!k: 참고할 이웃의 수를 할당합니다. 임의로 넣어도 되고, 데이터 행 개수의 제곱근을 할당해도 됩니다. 이 때 제곱근은 대개 무리수이므로,ceiling()또는floor()등을 사용하여 정수로 바꿔주어야 합니다.prob: 목표변수 범주에 속할 확률을 반환할지 여부를TRUE또는FALSE로 할당합니다. 만약TRUE로 할당하면prob속성(attribute)으로 확률값이 저장됩니다.
# 필요 패키지를 불러옵니다.
library(class)
# set.seed를 지정합니다.
set.seed(seed = 123)
# 가중치 없는 KNN 분류모형을 적합합니다.
fitKnn <-
knn(train = trainSet[, 1:11],
test = testSet[, 1:11],
cl = trainSet$grade,
k = trainSet %>% nrow() %>% sqrt() %>% ceiling(),
prob = TRUE)
# 예측값의 첫 100개만 미리보기 합니다.
fitKnn[1:100]
## [1] good good good good good good good best good good good good good good
## [15] good good good good good good good good good good good good good good
## [29] good good good good good good good good good good good good good good
## [43] good good good good good good good good good best good good good good
## [57] good good good good good good good good good good good good good good
## [71] good good good good good good good good good good good good good good
## [85] good good good good good good good good good good good good good good
## [99] good good
## Levels: best good
# 예측값의 확률도 첫 100개만 미리보기 합니다.
attr(x = fitKnn, which = 'prob')[1:100]
## [1] 0.9500000 0.9833333 0.9833333 0.6949153 0.8135593 0.6440678 1.0000000
## [8] 0.5084746 1.0000000 1.0000000 0.9152542 0.8474576 0.7333333 0.9491525
## [15] 0.8666667 0.7288136 0.9830508 0.9830508 0.8000000 0.5084746 0.9322034
## [22] 0.5423729 1.0000000 0.8305085 0.9491525 0.9830508 0.9322034 0.9833333
## [29] 0.9830508 0.6833333 0.8305085 0.9491525 0.9322034 1.0000000 1.0000000
## [36] 0.7457627 0.5500000 0.8983051 0.9491525 0.6949153 0.9830508 0.7500000
## [43] 0.8135593 0.9661017 0.6779661 0.9000000 0.7288136 0.6610169 1.0000000
## [50] 0.9491525 0.7166667 0.6610169 1.0000000 0.5932203 0.9830508 0.7627119
## [57] 0.9661017 0.9661017 1.0000000 0.6949153 1.0000000 0.7118644 0.9152542
## [64] 0.9830508 0.9491525 0.7966102 0.7966102 0.8305085 0.8983051 0.7118644
## [71] 0.6779661 0.7166667 0.7000000 0.9677419 1.0000000 1.0000000 0.9322034
## [78] 0.9322034 0.6101695 0.8305085 1.0000000 0.8474576 0.9666667 0.7627119
## [85] 0.7627119 0.7627119 0.7796610 0.8135593 0.9661017 0.7796610 0.7457627
## [92] 0.6949153 0.8135593 0.7000000 0.7333333 0.7627119 0.8813559 0.6271186
## [99] 0.7966102 0.5084746
# 예측값을 시험용 데이터셋에 pred 컬럼으로 만듭니다.
testSet$pred <- fitKnn
# 시험용 데이터셋의 grade와 pred의 빈도수를 비교합니다.
table(testSet$grade, testSet$pred) %>% addmargins()
##
## best good Sum
## best 83 254 337
## good 45 1077 1122
## Sum 128 1331 1459
시험용 데이터셋의 실제 목표변수인 grade와 분류모형의 결과로 추정된 pred 간 빈도수를 비교해보니 원래 best인 337건 중에서 254건이 good으로 다르게 분류되었음을 알 수 있습니다. 하지만 원래 good인 1122건 중에서 1077건이 제대로 분류되었습니다. 왜 이런 일이 발생할까요? 이 문제는 바로 샘플링에 있습니다.
원데이터의 good과 best의 비중이 78%, 22%로 대다수가 good에 몰려있습니다. 마찬가지로 trainSet과 testSet에서도 목표변수의 두 범주가 원데이터와 비슷한 비중을 보이고 있습니다. 데이터셋이 이와 같을 때 기계학습 알고리즘은 학습을 하는 과정에서 다수(majority)를 차지하는 범주(이번 예제에서는 good)로 더 많이 치우치는 경향을 보입니다. 그리고 일반적으로 (경험이 많지 않은) 분석가들은 분류모형의 성능을 판단하는 기준으로 정확성(accuracy)를 확인하는 경향이 강합니다. 하지만 앞서 말씀드린 이유로 정확성을 기준으로 분류모형의 성능을 판단하면 안됩니다. 분류모형 성능 평가 방법에 대해서는 나중에 따로 살펴보기로 하고, 지금은 trainSet과 testSet을 어떻게 만들면 되는지에 대하여 알아보도록 하겠습니다.
사실 방법은 간단합니다. trainSet의 목표변수의 두 범주인 good과 best의 비중을 50:50으로 맞춰주면 됩니다. 이렇게 하는 것을 표본 균형화(Sample Balancing)라고 합니다. 이번 예제에서는 best의 비중이 good의 비중보다 작으므로 best인 건을 여러 번 복사하여 good의 건수만큼 맞춰주는 Oversampling을 하든가, 아니면 반대로 good의 건수를 best의 건수에 맞도록 Undersampling을 하면 됩니다. 두 범주의 비중 차이가 큰 경우에는 Oversampling과 Undersampling을 혼합한 방법(예를 들면 SMOTE)을 사용하기도 합니다.[3]
R에서는 ROSE 패키지의 ovun.sample() 함수를 사용하여 Oversampling 또는 Undersampling, 아니면 두 가지 방법을 섞은 균형화 작업을 간단하게 해결할 수 있습니다. 이 함수에 필요한 주요 인자들을 설명하겠습니다.
formula: 목표변수와 입력변수 간 관계를 설정합니다. 중간에 tilde(~)를 삽입하면 됩니다. 일반적으로는목표변수 ~ .처럼 간략하게 표현합니다. tilde 오른쪽의.은 모든 입력변수를 의미합니다.data: 데이터셋을 할당합니다. 이번 예제에서는 trainSet을 할당하면 됩니다.method: ‘over’, ‘under’, ‘both’ 중 하나를 할당합니다. ‘both’는 SMOTE가 됩니다.N: 원하는 데이터 크기를 지정할 수 있습니다. 생략하면method와p인자를 참조하여 생성합니다.p: 목표변수의 범주형 비중을 설정합니다. 같은 비중의 데이터를 얻으려면0.5를 할당하면 됩니다.seed: 여러 번 반복하여 실행하더라도 같은 결과를 얻기 위해 seed를 지정합니다.
# 필요 패키지를 불러옵니다.
library(ROSE)
# 훈련용 데이터셋을 다시 만듭니다.
# ovun.sample() 함수는 3개의 원소를 갖는 리스트를 반환합니다.
# 그 중에서 우리가 원하는 데이터셋은 'data' 원소입니다.
trainSetBal <-
ovun.sample(formula = grade ~ .,
data = trainSet,
method = 'both',
p = 0.5,
seed = 123) %>%
`[[`('data')
# 목표변수의 비중을 재확인합니다.
trainSetBal$grade %>% table() %>% prop.table()
## .
## good best
## 0.5027624 0.4972376
새로 만들어진 trainSetBal의 건수는 기존 trainSet과 같지만, 목표변수의 비중이 50.3:49.7로 거의 비슷해졌음을 알 수 있습니다. 그럼 이 균형화된 데이터셋으로 KNN 분류모형을 다시 적합해보고 결과를 비교해보겠습니다.
# set.seed를 지정합니다.
set.seed(seed = 123)
# 균형화된 훈련용 데이터셋으로 가중치 없는 KNN 분류모형을 적합합니다.
# 주의해야 할 점은 trainSet을 모두 trainSetBal로 바꿔주어야 한다는 것입니다.
fitKnnBal <-
knn(train = trainSetBal[, 1:11],
test = testSet[, 1:11],
cl = trainSetBal$grade,
k = trainSetBal %>% nrow() %>% sqrt() %>% ceiling(),
prob = TRUE)
# 예측값을 시험용 데이터셋에 pred 컬럼으로 만듭니다.
testSet$predBal <- fitKnnBal
# 시험용 데이터셋의 grade와 predBal의 빈도수를 비교합니다.
table(testSet$grade, testSet$predBal) %>% addmargins()
##
## good best Sum
## best 68 269 337
## good 731 391 1122
## Sum 799 660 1459
그런데 뭔가 좀 어색하네요. 아무래도 ovun.sample()을 하면서 범주형 벡터인 grade의 level 순서가 바뀐 것 같습니다. 이 문제를 해결하려면 testSet$predBal의 level을 확인하고 필요 시 순서를 변경해주어야 합니다.
# predBal의 level 순서를 확인합니다.
levels(x = testSet$predBal)
## [1] "good" "best"
# predBal의 level 순서를 'best'가 먼저 오도록 변경합니다.
testSet$predBal <- relevel(x = testSet$predBal, ref = 'best')
# 시험용 데이터셋의 grade와 predBal의 빈도수를 비교합니다.
table(testSet$grade, testSet$predBal) %>% addmargins()
##
## best good Sum
## best 269 68 337
## good 391 731 1122
## Sum 660 799 1459
이제 제대로 원하는 결과를 얻었습니다. 첫 번째 결과와 크게 달라진 것을 알 수 있습니다. 그럼 지금까지 두 개의 분류모형을 적합한 결과를 가지고 어느 모형이 얼마나 더 우수한 성능을 보이는지 평가하는 방법에 대해 알아보도록 하겠습니다. 이 내용은 분류모형에 공통적으로 적용할 수 있으므로 별도의 포스팅으로 정리해두었습니다. 분류모형의 성능 평가 기준 바로가기를 클릭하여 해당 내용을 확인하고 다시 돌아오도록 하겠습니다.
분류모형 성능 비교하기
이전 포스팅에서 소개해드린 바와 같이 분류모형의 성능을 평가하는 여러 기준 중에서 혼동행렬의 여러 지표들과 AUROC 기준으로 와인 품질을 분류하는 모형의 성능을 비교해보도록 하겠습니다.
혼동행렬 (Confusion Matrix)
caret 패키지의 confusionMatrix() 함수로 간단하게 확인할 수 있습니다. 이 함수에서 사용되는 주요 인자 2가지를 설명하겠습니다.
data: 예측값을 할당합니다.reference: 실제값을 할당합니다.
# 필요 패키지를 불러옵니다.
library(caret)
# 첫 번째 예측값과 실제값으로 혼동행렬과 지표들을 확인합니다.
confusionMatrix(data = testSet$pred, reference = testSet$grade)
## Confusion Matrix and Statistics
##
## Reference
## Prediction best good
## best 83 45
## good 254 1077
##
## Accuracy : 0.7951
## 95% CI : (0.7734, 0.8155)
## No Information Rate : 0.769
## P-Value [Acc > NIR] : 0.009245
##
## Kappa : 0.2633
## Mcnemar's Test P-Value : < 2.2e-16
##
## Sensitivity : 0.24629
## Specificity : 0.95989
## Pos Pred Value : 0.64844
## Neg Pred Value : 0.80917
## Prevalence : 0.23098
## Detection Rate : 0.05689
## Detection Prevalence : 0.08773
## Balanced Accuracy : 0.60309
##
## 'Positive' Class : best
##
표본 균형화 작업을 하지 않은 첫 번째 훈련용 데이터셋으로 예측한 값과 실제값으로 만든 혼동행렬 결과를 간단하게 확인해보겠습니다. 가장 먼저 확인해야 할 것은 맨 마지막 줄에 있는 Positive의 범주입니다. 이번 예제에서는 best입니다.
- 정확도(Accuracy)는 0.7951로 상당히 높게 나왔습니다. 하지만 정확도는 중요한 지표가 아니라는 사실을 아시죠?
- 민감도(Sensitivity)는 0.24629에 불과합니다. 실제값이
best인 개수 중에서 모형이best라고 제대로 예측한 비율이 24.6% 밖에 안 된다는 것입니다. 좋은 모형이 아닙니다. - 특이도(Specificity)는 0.95989로 매우 높습니다. 실제값이
good인 개수 중에서 모형이good이라고 제대로 예측한 비율이 96.0%나 된다는 것입니다. - 정밀도(Precision 또는 Pro Pred Value)는 0.64844입니다. 모형이
best라고 예측한 것 중 실제로best인 비중이 64.8% 정도 된다고 하는 것입니다.
위와 같이 confusionMatrix() 함수로 확인할 수 있는 주요 지표들을 확인해봤습니다. 그럼 제가 가장 중요하다고 강조한 F1 점수는 어떻게 확인할 수 있을까요? 사실 그동안은 table() 함수의 결과값으로 직접 만들었는데, 이번 포스팅을 작성하면서 구글링해보니 MLmetrics 패키지의 F1_Score() 함수로 간단하게 해결이 가능하다는 것을 알았습니다. confusionMatrix() 함수와 인자명만 바뀌었을 뿐 예측값과 실제값을 할당하는 순서는 같아서 좋네요.
# 필요 패키지를 불러옵니다.
library(MLmetrics)
# 첫 번째 예측값과 실제값으로 F1 점수를 확인합니다.
F1_Score(y_pred = testSet$pred, y_true = testSet$grade)
## [1] 0.3569892
F1 점수가 0.3569892로 상당히 낮다는 것을 알 수 있습니다. 직접 계산하는 것도 한 번 해볼까요? 혼동행렬의 경우 행 기준으로 예측값, 열 기준으로 실제값이 사용되었음을 감안하여 table() 함수에도 예측값, 실제값 순서로 할당하도록 합니다.
# 실제값과 예측값 빈도행렬을 만들고 tbl 객체에 할당합니다.
tbl <- table(testSet$pred, testSet$grade)
# tbl 객체를 출력합니다.
print(tbl)
##
## best good
## best 83 45
## good 254 1077
tbl 객체를 출력해보니 혼동행렬과 비슷하다는 것을 알 수 있습니다. 이제 tbl 객체의 4가지 원소에 대해 TP, FP, FN, TN을 지정합니다.
# tbl 객체의 4가지 원소에 대해 TP, FP, FN, TN을 지정합니다.
TP <- tbl[1, 1]
FP <- tbl[1, 2]
FN <- tbl[2, 1]
TN <- tbl[2, 2]
# 공식을 이용하여 F1 점수를 계산합니다.
F1 <- 2*TP / (2*TP + FP + FN)
print(F1)
## [1] 0.3569892
F1_Score() 함수를 사용한 것과 똑같은 결과를 보입니다. 혹시 혼동행렬의 여러 지표들을 직접 만들어보고 싶다는 생각이 들지 않나요?
이제 두 번째 모형과 비교해보도록 하겠습니다.
# 두 번째 예측값과 실제값으로 혼동행렬과 지표들을 확인합니다.
confusionMatrix(data = testSet$predBal, reference = testSet$grade)
## Confusion Matrix and Statistics
##
## Reference
## Prediction best good
## best 269 391
## good 68 731
##
## Accuracy : 0.6854
## 95% CI : (0.6609, 0.7092)
## No Information Rate : 0.769
## P-Value [Acc > NIR] : 1
##
## Kappa : 0.3368
## Mcnemar's Test P-Value : <2e-16
##
## Sensitivity : 0.7982
## Specificity : 0.6515
## Pos Pred Value : 0.4076
## Neg Pred Value : 0.9149
## Prevalence : 0.2310
## Detection Rate : 0.1844
## Detection Prevalence : 0.4524
## Balanced Accuracy : 0.7249
##
## 'Positive' Class : best
##
먼저 Positive 범주가 best인 것을 확인한 후 주요 지표들을 하나씩 확인해보겠습니다.
- 정확도는 0.6854로 첫 번째 모형보다 다소 낮아졌습니다.
- 민감도는 0.7982로 크게 향상되었습니다. 표본 균형화 작업은 이렇게 중요합니다!
- 특이도는 0.6515로 낮아졌지만 그래도 괜찮습니다. 민감도가 더 중요하니까요.
- 정밀도가 0.4076으로 낮아진 건 조금 아쉽습니다. 이 값이 높아야 F1 점수도 높아지거든요.
# 두 번째 예측값과 실제값으로 F1 점수를 확인합니다.
F1_Score(y_pred = testSet$predBal, y_true = testSet$grade)
## [1] 0.5396189
두 번째 모형의 F1 점수는 0.5396189로 첫 번째 모형에 비해 크게(?) 향상되었습니다. 비록 정밀도가 조금 낮아졌지만 민감도가 크게 향상되었기 때문입니다.
ROC 커브와 AUROC
ROC 커브는 민감도와 1-특이도를 기준으로 분류모형의 예측 정확도를 평가하는데 사용되는 곡선이라고 설명한 바 있습니다. ROC 커브는 ROCR 패키지의 prediction() 함수와 performance() 함수를 이용하여 그릴 수 있습니다.
prediction() 함수에 예측값과 실제값을 순서대로 지정하여 실행한 후 그 결과를 predObj에 할당합니다. 이 함수는 혼동행렬의 각 지표들을 표준화된 값으로 반환합니다. 그런데 주의해야 할 점은 예측값을 할당하는 predictions 인자에 숫자 벡터를 지정해야 한다는 것입니다. 이번 예제처럼 범주형 벡터를 숫자 벡터로 변환하면 정수값이 할당되므로 ROC 커브가 몇 개의 직선으로 그려집니다. 하지만 확률값을 할당하면 완만한 곡선이 그려집니다.
performance() 함수에는 바로 앞에서 만든 predObj를 이용하여 ROC 커브를 그릴 각 지점을 잡아냅니다. measure 인자에는 y축에 해당하는 민감도(tpr), x.measure 인자에는 x축에 해당하는 1-특이도(fpr)을 할당합니다.
# 필요 패키지를 불러옵니다.
library(ROCR)
# 첫 번째 예측값과 실제값으로 표준화된 prediction 객체를 생성합니다.
# [주의] 예측값은 숫자 벡터로 변환하여 할당해야 합니다!
predObj <- prediction(predictions = as.numeric(testSet$pred),
labels = testSet$grade)
# prediction 객체를 활용하여 performance 객체를 생성합니다.
perform <- performance(prediction.obj = predObj,
measure = 'tpr',
x.measure = 'fpr')
# ROC 커브를 그립니다.
plot(x = perform, main = 'ROC 커브 - 첫 번째 모형')
# 왼쪽 아래 모서리에서 오른쪽 위 모서리를 잇는 대각선을 추가합니다.
lines(x = c(0, 1), y = c(0, 1), col = 'red', lty = 2)
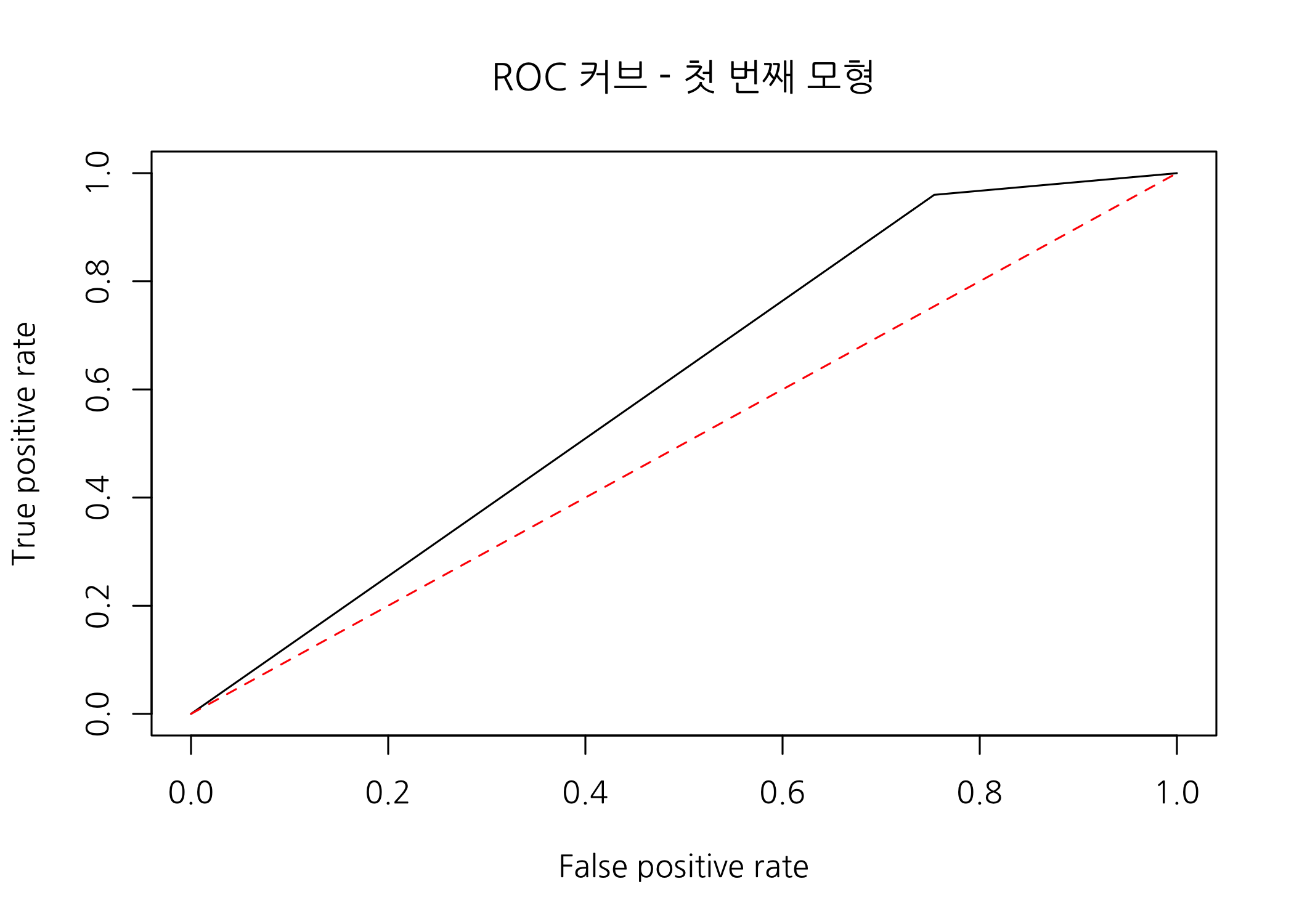
(생애 처음으로 그려본) ROC 커브가 생각보다 예쁘지 않네요. 검정색 곡선이 왼쪽 위 모서리에 가까울수록 좋은 모형이라는 것은 앞에서 설명을 드렸습니다. 그럼 pROC 패키지의 auc() 함수에 실제값과 예측값을 할당하여 AUROC를 확인해보도록 하겠습니다. 이 함수도 예측값은 숫자 벡터로 할당해주어야 한다는 점을 주의하기 바랍니다.
# 필요 패키지를 불러옵니다.
library(pROC)
## Type 'citation("pROC")' for a citation.
##
## Attaching package: 'pROC'
## The following objects are masked from 'package:stats':
##
## cov, smooth, var
# 첫 번째 분류모형의 AUROC를 확인합니다.
# [주의] 예측값은 숫자 벡터로 변환하여 할당해야 합니다!
auc(testSet$grade, as.numeric(testSet$pred))
## Area under the curve: 0.6031
분류모형의 성능 평가 기준 포스팅에서 AUROC는 0.5 ~ 1 사이의 값을 갖는다고 설명했는데, 이 모형의 AUROC는 0.6031이므로 분류 성능이 매우 낮다는 것을 AUROC로도 확인할 수 있습니다.
그럼 두 번째 모형의 성능은 어떨까요? ROC 커브를 그리고 AUROC도 바로 확인해보겠습니다.
# 두 번째 예측값과 실제값으로 표준화된 prediction 객체를 생성합니다.
# [주의] 예측값은 숫자 벡터로 변환하여 할당해야 합니다!
predObj <- prediction(predictions = as.numeric(testSet$predBal),
labels = testSet$grade)
# prediction 객체를 활용하여 performance 객체를 생성합니다.
perform <- performance(prediction.obj = predObj,
measure = 'tpr',
x.measure = 'fpr')
# ROC 커브를 그립니다.
plot(x = perform, main = 'ROC 커브 - 두 번째 모형')
# 왼쪽 아래 모서리에서 오른쪽 위 모서리를 잇는 대각선을 추가합니다.
lines(x = c(0, 1), y = c(0, 1), col = 'red', lty = 2)
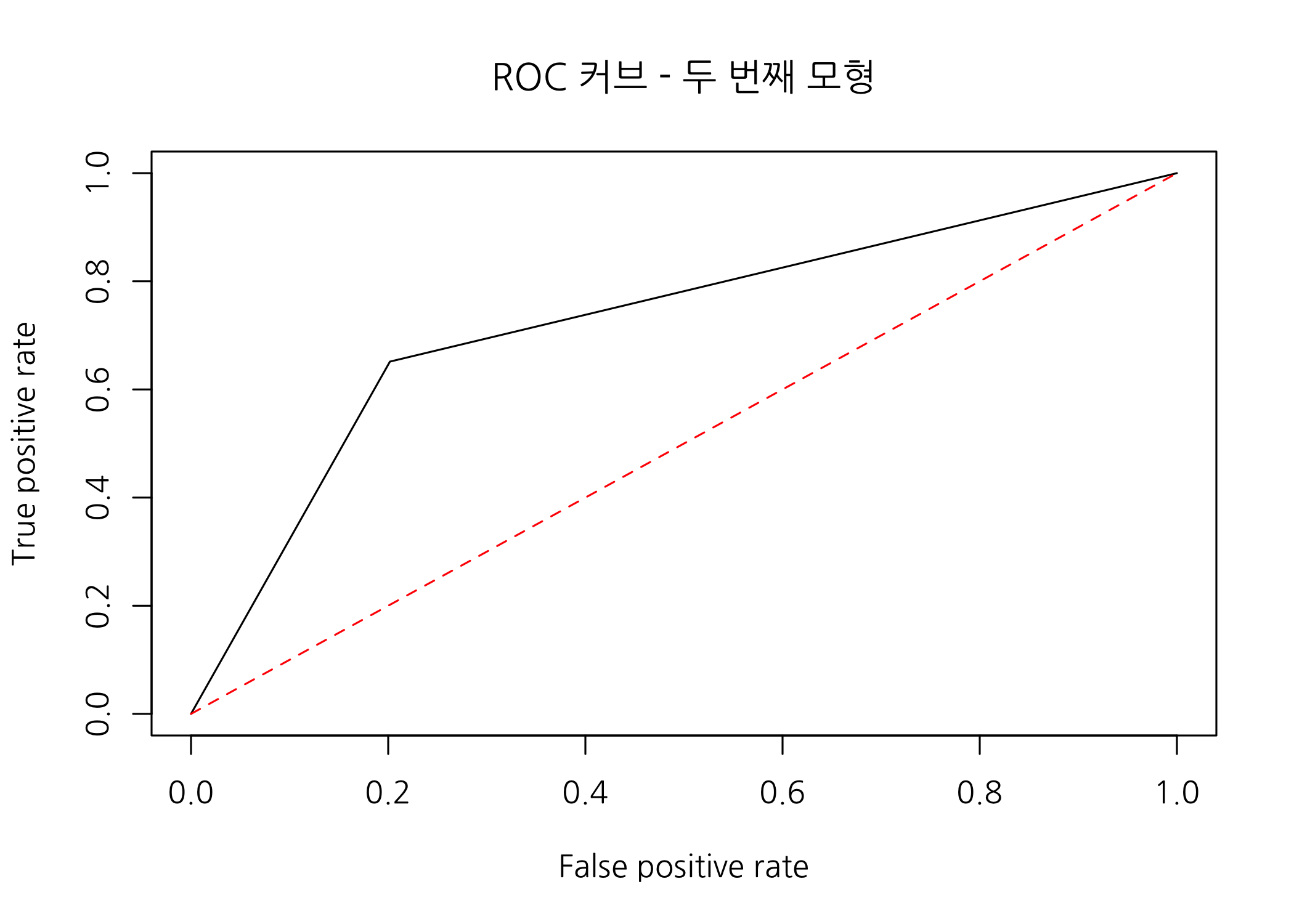
첫 번째 모형에 비해 뭔가 더 볼록해진 기분이 듭니다.
# 두 번째 분류모형의 AUROC를 확인합니다.
# [주의] 예측값은 숫자 벡터로 변환하여 할당해야 합니다!
auc(testSet$grade, as.numeric(testSet$predBal))
## Area under the curve: 0.7249
두 번째 모형의 AUROC는 0.7249로 첫 번째 모형에 비해 크게 증가했습니다. 이로써 분류모형의 성능을 평가하는 여러 지표들을 확인하는 방법과 여러 분류모형들의 성능을 비교하는 방법에 대해서 충분히 이해했을 것으로 믿습니다.
가중치 있는 KNN 분류모형 적합하기
유유상종이라든가 끼리끼리 논다라는 속담에서 알 수 있듯이 비슷한 성질을 가질수록 서로 가깝다라고 생각할 수 있습니다. 이러한 점을 착안하여 KNN에서는 예측하고자 하는 데이터와 가까울수록 결과에 더 큰 영향을 미치는 중요한 이웃이라고 판단할 수 있습니다. 더 중요한 이웃으로 판단한다는 것은 가중치를 크게 부여한다는 것이므로, 거리의 역수를 가중치로 설정함으로써 간단하게 해결할 수 있습니다.
가중치 있는 KNN 분류모형은 kknn 패키지의 kknn() 함수를 이용하여 적합할 수 있습니다. 주요 인자는 다음과 같습니다.
formula: 입력변수와 목표변수 간의 관계를 표현한 식을 할당합니다.train: 훈련용 데이터셋을 할당합니다.test: 시험용 데이터셋을 할당합니다.k: 참고할 이웃의 수를 할당합니다. 이번에도 데이터 행 개수의 제곱근을 할당합니다.distance: Minkowski 거리에서의p값을 정수로 입력합니다. (1:맨하탄, 2:유클리디안)kernel: 가중치를 부여하는 방법을 할당합니다. ‘rectangular’(가중치 없는 모형), ‘triangular’, ‘epanechnikov’, ‘biweight’, ‘triweight’, ‘cos’, ‘inv’, ‘gaussian’, ‘rank’, ‘optimal’ 중 하나를 선택합니다.
# 필요 패키지를 불러옵니다.
library(kknn)
# 유클리디안 거리의 역수로 가중치를 준 knn 분류모형을 적합합니다.
fitKnnW <-
kknn(formula = grade ~ .,
train = trainSetBal,
test = testSet,
k = trainSetBal %>% nrow() %>% sqrt() %>% ceiling(),
distance = 2,
kernel = 'triangular')
# 모형 결과의 속성을 확인합니다.
class(x = fitKnnW)
## [1] "kknn"
kknn() 함수는 kknn 속성의 객체를 결과로 반환합니다. 비록 익숙한 속성은 아니지만, 데이터 프레임처럼 $ 연산자를 사용하면 됩니다. 모형 예측값은 fitted.values라는 범주형 벡터입니다. 앞에서 했던 것과 동일하게 testSet에 predBalW라는 컬럼으로 저장하고, 실제값과 빈도수를 확인해보겠습니다.
# 예측값을 testSet에 predW 컬럼으로 저장합니다.
testSet$predBalW <- fitKnnW$fitted.values
# 실제값과 예측값의 빈도수를 확인합니다.
table(testSet$grade, testSet$predBalW) %>% addmargins()
##
## good best Sum
## best 61 276 337
## good 804 318 1122
## Sum 865 594 1459
이번에도 예측값의 level이 바뀌어 있는 것 같습니다. level 순서를 변경하고 다시 확인해봅니다.
# predBalW의 level 순서를 확인합니다.
levels(x = testSet$predBalW)
## [1] "good" "best"
# predBal의 level 순서를 'best'가 먼저 오도록 변경합니다.
testSet$predBalW <- relevel(x = testSet$predBalW, ref = 'best')
# 시험용 데이터셋의 grade와 predBal의 빈도수를 비교합니다.
table(testSet$grade, testSet$predBalW) %>% addmargins()
##
## best good Sum
## best 276 61 337
## good 318 804 1122
## Sum 594 865 1459
이제 제대로 나왔으니 가중치를 준 KNN 분류모형의 성능을 가중치 없는 모형과 비교해보겠습니다. 먼저 혼동행렬 주요 지표들 출력합니다.
# 가중치 있는 모형의 예측값과 실제값으로 혼동행렬과 지표들을 확인합니다.
confusionMatrix(data = testSet$predBalW, reference = testSet$grade)
## Confusion Matrix and Statistics
##
## Reference
## Prediction best good
## best 276 318
## good 61 804
##
## Accuracy : 0.7402
## 95% CI : (0.7169, 0.7626)
## No Information Rate : 0.769
## P-Value [Acc > NIR] : 0.9955
##
## Kappa : 0.4228
## Mcnemar's Test P-Value : <2e-16
##
## Sensitivity : 0.8190
## Specificity : 0.7166
## Pos Pred Value : 0.4646
## Neg Pred Value : 0.9295
## Prevalence : 0.2310
## Detection Rate : 0.1892
## Detection Prevalence : 0.4071
## Balanced Accuracy : 0.7678
##
## 'Positive' Class : best
##
먼저 Positive 범주가 best인 것을 확인한 후 주요 지표들을 하나씩 확인해보겠습니다.
- 정확도는 0.7402로 두 번째 모형보다 조금 향상되었습니다.
- 민감도는 0.8190으로 두 번째 모형보다 조금 향상되었습니다.
- 특이도는 0.7166으로 두 번째 모형보다 조금 향상되었습니다.
- 정밀도가 0.4646으로 두 번째 모형보다 조금 향상되었습니다.
가중치가 있는 KNN 분류모형이 가중치가 없는 모형보다 더 좋은 성능을 보인다는 것을 알 수 있습니다. 그럼 F1 점수는 어떨까요?
# 가중치 있는 모형의 예측값과 실제값으로 F1 점수를 확인합니다.
F1_Score(y_pred = testSet$predBalW, y_true = testSet$grade)
## [1] 0.5929108
가중치 없는 두 번째 모형의 F1 점수는 0.5396189였는데, 가중치 있는 모형의 F1 점수는 0.5929108로 이 또한 소폭 향상되었습니다. 유유상종이 맞네요!!
이번에는 ROC 커브를 그리고 AUROC를 확인해보겠습니다.
# 가중치 있는 모형의 예측값과 실제값으로 표준화된 prediction 객체를 생성합니다.
# [주의] 예측값은 숫자 벡터로 변환하여 할당해야 합니다!
predObj <- prediction(predictions = as.numeric(testSet$predBalW),
labels = testSet$grade)
# prediction 객체를 활용하여 performance 객체를 생성합니다.
perform <- performance(prediction.obj = predObj,
measure = 'tpr',
x.measure = 'fpr')
# ROC 커브를 그립니다.
plot(x = perform, main = 'ROC 커브 - 가중치 모형')
# 왼쪽 아래 모서리에서 오른쪽 위 모서리를 잇는 대각선을 추가합니다.
lines(x = c(0, 1), y = c(0, 1), col = 'red', lty = 2)
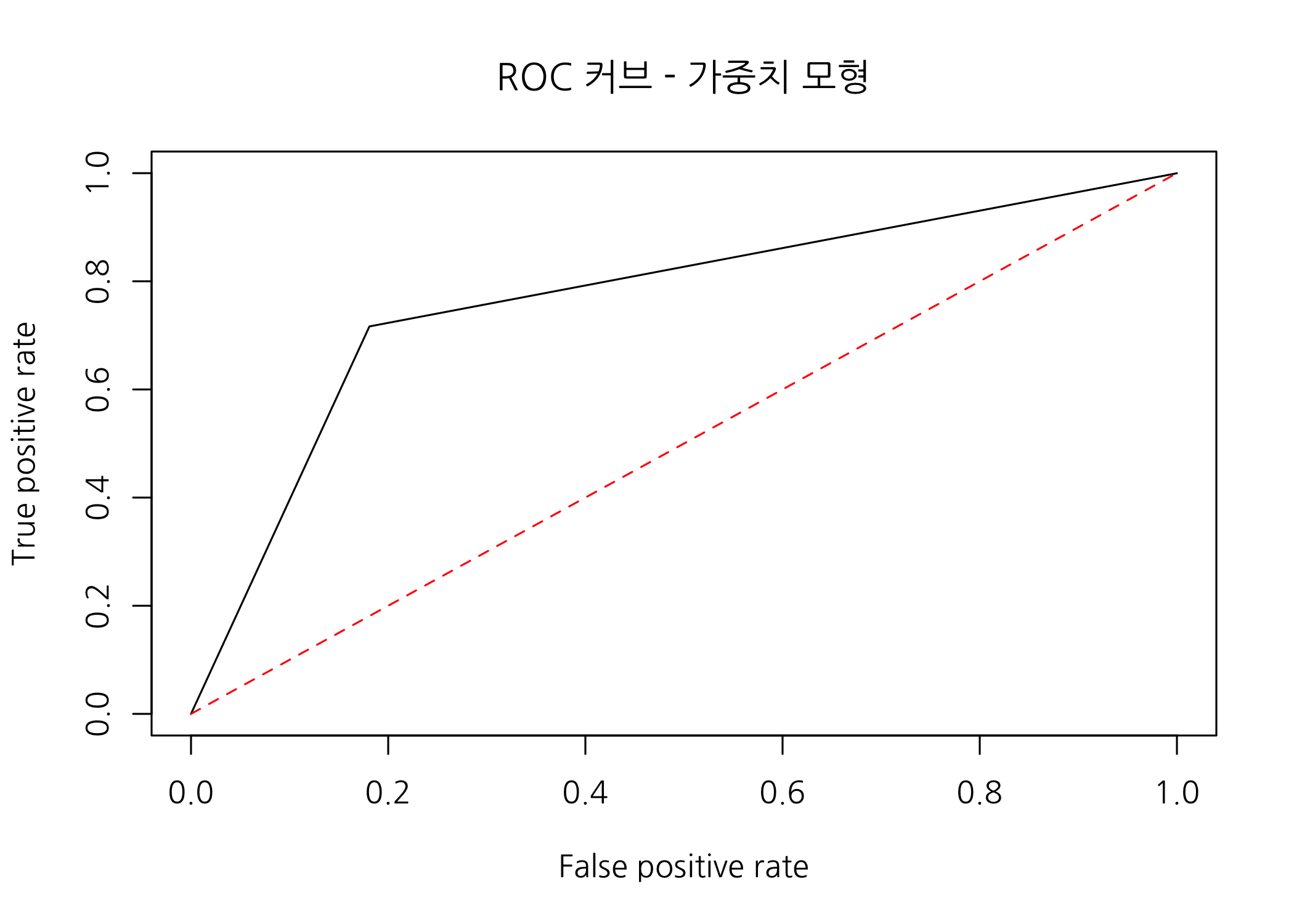
가중치 없는 두 번째 모형보다 더욱 볼록해진 것 같습니다.
# 가중치 있는 분류모형의 AUROC를 확인합니다.
# [주의] 예측값은 숫자 벡터로 변환하여 할당해야 합니다!
auc(testSet$grade, as.numeric(testSet$predBalW))
## Area under the curve: 0.7678
가중치 없는 두 번째 모형의 AUROC는 0.7249였는데, 가중치 있는 모형의 AUROC는 0.7678입니다. AUROC 기준으로도 가중치 있는 모형의 분류 성능이 더 뛰어나다는 것을 확인하였습니다.
이상으로 K-근접이웃에 대한 소개를 마치고, 다음 포스팅에서는 나이브 베이즈(Naive Bayes) 알고리즘을 활용한 분류모형을 소개해드리겠습니다.
[1] 자세한 내용은 위키백과를 참조하시기 바랍니다.
[3] 자세한 내용은 관련 위키피디아를 참조하기 바랍니다.