의사결정나무 (Decision Tree)
이 글은 2018~2019년에 작성한 R 기반 강의 노트를 옮긴 것입니다. 코드 일부는 현재 패키지 버전과 다를 수 있습니다.
이번 포스팅에서는 분류모형 세 번째 소개로 의사결정나무 (Decision Tree)에 대해서 알아보겠습니다. 의사결정나무는 목표변수가 범주형이면 분류모형, 연속형이면 회귀모형을 적합할 수 있습니다. 의사결정나무는 분류모형을 적합하기 위해 가장 많이 사용되는 알고리즘 중 하나이지만, 전체 과정을 끝까지 실행하는 분석가가 (생각보다) 많지 않은 것 같습니다.
의사결정나무는 순수도(Purity) 또는 불순도(Impurity) 기준으로 나무를 성장시킵니다. 즉, 부모마디로부터 자식마디로 분리될 때 부모마디보다 자식마디의 순수도가 높아지거나 불순도가 낮아져야 한다는 것이죠. 일단 모형을 적합하고 나면 나무를 보고 IF-THEN 규칙을 만들 수 있으므로 모형을 해석하고 활용하기에 좋기 때문에 널리 사용되고 있습니다. 아울러 의사결정나무는 비모수적 알고리즘이며, 이상치에 덜 민감하다는 장점도 가지고 있습니다. 그리고 결측값(NA)이 있어도 모형을 적합할 수 있습니다. 회귀분석은 결측값이 있을 때 해당 건을 삭제하거나 다른 값으로 대체해주어야 하거든요. 한편으로는 결측값 그 자체가 입력변수의 값으로 인정받을 수도 있습니다. 예컨데, 보험회사의 상품가입신청서에 의무사항이 아닌 선택사항을 입력하는 소비자들이 입력하지 않는 대다수와 다른 성향을 갖고 있다고 보는 거죠.
물론 의사결정나무는 과적합하기 쉽다는 단점이 있습니다. 따라서 의사결정나무를 활용하여 분류모형을 적합하고자 할 때 분석가가 정지규칙을 잘 설정해야 하며, 적합된 분류모형을 가지치기 함으로써 과적합될 위험을 줄여야 합니다. 이 포스팅에서 소개하는 함수는 교차검증 방법을 활용하여 가지치기합니다.
의사결정나무의 종류
의사결정나무 알고리즘은 크게 3가지 종류가 사용됩니다.
1. CART (Classification and Regression Tree)
- 분류모형은 지니지수(Gini Index)를 이용하여 순수도를 계산합니다.
- 예측모형의 경우, 분산의 감소량을 기준으로 나무를 성장시킵니다.
- [예/아니오]와 같이 목표변수의 범주가 2개인 이진분리에 사용됩니다.
- R에서는 rpart 패키지의
rpart()함수를 사용합니다. 이 포스팅에서는rpart()함수만 설명합니다.
2. C5.0
- 엔트로피(Enthropy)를 이용하여 순수도를 계산하는 알고리즘입니다.
- 부모마디의 엔트로피에서 자식마디의 엔트로피 가중평균을 뺀 정보이익(Information Gain)을 이용합니다.
- 목표변수가 3개 이상 범주를 갖는 다지분리가 가능합니다.
- R에서는 C5.0 패키지의
C5.0.default()함수를 사용합니다.
3. CHAID (Chisquared Automatic Interaction Detection)
- 분류모형은 카이제곱 통계량을 이용하여 순수도를 계산합니다.
- 예측모형의 경우, 분산분석의 F-통계량을 이용합니다.
- 입력변수는 반드시 범주형이어야 하므로, 숫자형 벡터는 범주형으로 변환해주어야 합니다.
- R에서는
party()함수를 사용합니다.
의사결정나무의 구성요소
아래 그림처럼 의사결정나무는 뿌리마디(Root node), 부모마디(Parent node), 자식마디(Child node), 중간마디(Internal node), 끝마디(Terminal node), 깊이(Depth) 등으로 구성되어 있습니다.
 [1]
[1]
의사결정나무 프로세스
의사결정나무는 뿌리마디로부터 출발하여, 부모마디보다 자식마디의 순수도가 높아지거나 불순도가 낮아지는 최적의 분리규칙을 찾았을 때 나무를 성장시킵니다. 아울러 정지규칙을 만족할 때 성장을 중단합니다. 정지규칙은 각 마디에 포함되는 데이터 건수 기준 또는 나무의 깊이, 끝마디의 개수 등으로 설정할 수 있습니다.
나무를 적합하고 나면 과적합을 피해 불필요한 가지를 잘라내는 가지치기를 하여 모형을 완성합니다. 이런 방식으로 여러 가지 분류모형을 적합한 다음 이익표(Gains Chart) 또는 위험도표(Risk Chart), 교차검증(Cross-validation) 등으로 각각의 분류모형을 평가하고 최종모형을 결정합니다. 마지막으로 최종모형에 대해 해석하고 활용합니다.
1. 분리규칙
분리규칙은 각 마디에서 목표변수를 가장 잘 분리해주는 입력변수와 분리기준으로 정해집니다. 분리규칙을 정하는 기준은 순수도 또는 불순도를 사용합니다. 부모마디의 순수도에 비해 자식마디의 순수도가 높은 경우에만 분리됩니다. 아울러 자식마디의 순수도를 가장 크게 해주는 분리규칙이 우선 적용됩니다.
아래 그림을 보면, 부모마디에는 30명의 학생이 속해 있고 그 중 15명이 크리켓 선수입니다. 따라서 부모마디의 순수도는 지니지수 기준으로 50%입니다. 왼쪽 그림은 입력변수가 성별(Gender) 기준으로 분리되고, 오른쪽 그림은 학급(Class) 기준으로 분리되는 것을 보입니다. 분리된 이후 가중평균 순수도는 성별일 때 59%, 학급일 때 51%이므로 성별 기준으로 가지를 분리하게 됩니다. 그럼 이 예제로 각각의 분리규칙을 설명하겠습니다.
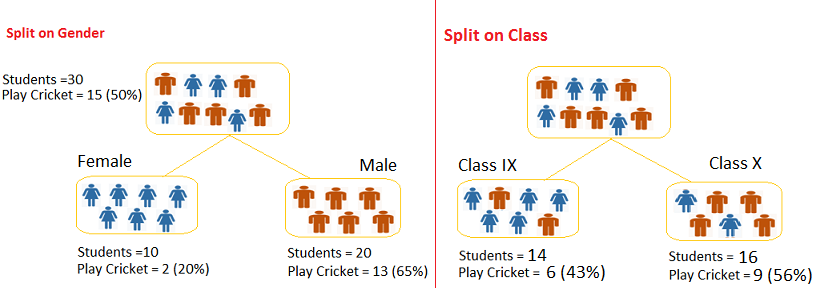 [2]
[2]
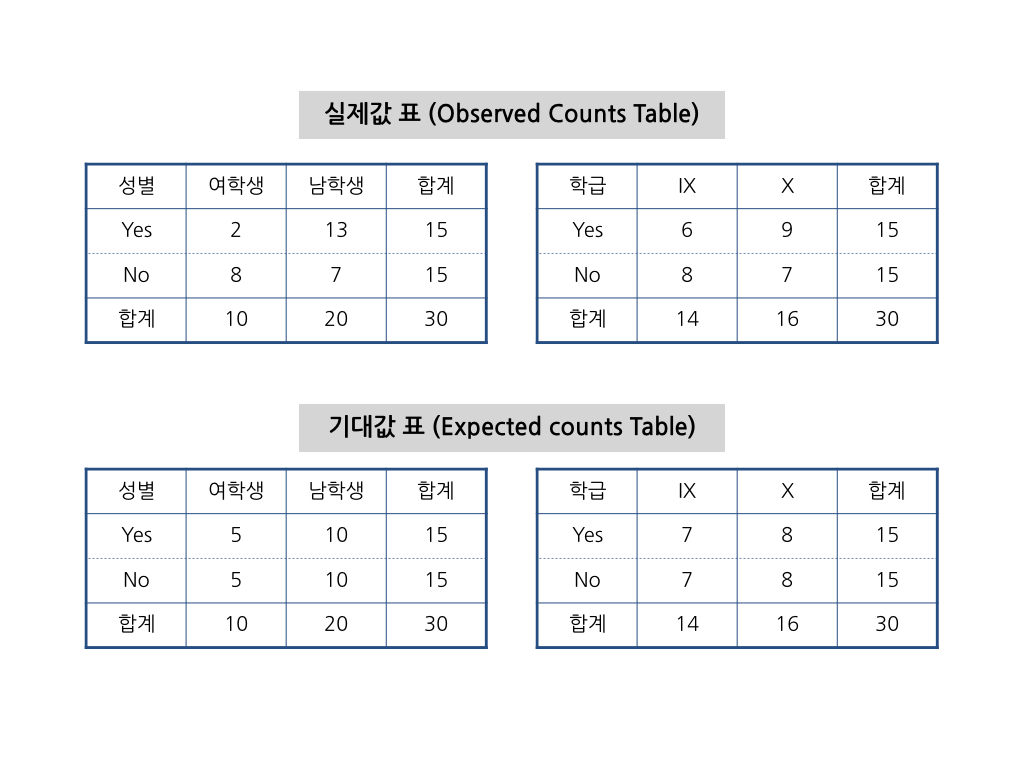
아래 실제값 표는 위 그림을 분할표(Contingency Table)로 표현한 것입니다. 그리고 실제값 표를 기준으로 기대값 표를 완성합니다. 기대값 표의 각 셀에 들어갈 숫자는 각 합계의 곱을 전체 관측치의 수로 나눈 것입니다. 예를 들어, 여학생 중 크리켓 선수일 기대값은 실제값 표의 첫 행의 합계(15)와 첫 열의 합계(10)를 곱한 것을 전체 관측치의 수(30)로 나눈 것입니다.
지니지수 (Gini Index)
지니지수의 공식은 아래와 같습니다.
\[\text {지니지수} = 1 - \sum {P_j^2}\]Pj는 끝마디에 속한 목표변수의 확률(비율)을 의미합니다. 예제에서 부모마디에는 Yes와 No가 각각 15명씩 있으므로 각각의 Pj는 1/2입니다. 따라서 부모마디의 지니지수를 계산하면 아래와 같습니다.
자식마디의 지니지수는 왼쪽마디와 오른쪽마디의 지니지수를 각각 계산한 후 관측치 기준으로 가중평균한 값입니다. 두 입력변수별 분리규칙으로 각각의 지니지수를 계산한 다음 부모마디의 지니지수와의 차이가 가장 큰 분리규칙을 선택하면 됩니다.
\[\text {자식마디의 지니지수(성별)} = \frac {10}{30} \times \biggl[ 1 - \biggl( (\frac {2}{10})^2 + (\frac {8}{10})^2 \biggl) \biggl] + \frac {20}{30} \times \biggl[ 1 - \biggl( (\frac {13}{20})^2 + (\frac {7}{20})^2 \biggl) \biggl] = 0.41\] \[\text {자식마디의 지니지수(학급)} = \frac {14}{30} \times \biggl[ 1 - \biggl( (\frac {6}{14})^2 + (\frac {8}{14})^2 \biggl) \biggl] + \frac {16}{30} \times \biggl[ 1 - \biggl( (\frac {9}{16})^2 + (\frac {7}{16})^2 \biggl) \biggl] = 0.4911\]지니지수 기준으로는 성별로 분리할 때 부모마디와의 차이가 더 크므로, 성별을 기준으로 가지를 분리하게 됩니다.
엔트로피 (Enthropy)
엔트로피는 정보이론(Information Theory)에서 사용되는 용어로, 어떤 시스템에서 송신자가 메시지를 보내고 채널은 특정한 방식으로 메시지를 변경하며, 수신자는 어떤 메시지가 보내진 것인지 추론한다고 할 때, 각 메시지에 포함된 정보의 기대값(평균)을 정보 엔트로피라고 합니다.[3] 일반적으로 엔트로피는 무질서도 또는 불확실성을 가리키며, 0~1 값을 갖습니다.
엔트로피 계산식을 먼저 확인하고 설명을 이어나가겠습니다. 엔트로피는 목표변수의 각 범주별 확률(비율)에 밑이 2인 로그를 취하고 다시 확률을 곱하여 모두 더한 것입니다. 확률은 0~1 값을 갖기 때문에 로그를 취하면 음수가 되므로 맨 앞에 마이너스 부호를 추가해준 것입니다.
\[\text {엔트로피} = − \sum { P_j log_2 {P_j} }\]위 식에서 알 수 있듯이 엔트로피는 목표변수의 추정값(labelled value)이 정확하게 같은 비율일 때 1이 되고, 목표변수의 추정값이 어느 한 쪽으로 완전하게 치우쳤을 때 0이 됩니다. 왜냐하면, 추정값의 비중이 같다는 것은 Pj가 각각 1/2이라는 것이므로 밑이 2인 로그를 취해주면 -1값을 가지게 되며 맨 앞에 붙은 마이너스 부호로 인해 전체 엔트로피는 1이 되는 것입니다. 그리고 어느 한 쪽으로 치우쳤다는 것은 Pj가 각각 0과 1이라는 것을 의미합니다. 따라서 전체 엔트로피는 0이 되는 것이죠.
이번 예제에서 부모마디의 엔트로피를 계산하면 다음과 같습니다.
\[\text {부모마디의 엔트로피} = - \biggl( \frac {1}{2} \log_2 {\frac {1}{2}} + \frac {1}{2} \log_2 {\frac {1}{2}} \biggl) = 1\]이번에는 자식마디에서의 엔트로피 가중평균을 계산해보겠습니다.
\[\text {자식마디의 엔트로피(성별)} = \frac {10}{30} \times \biggl[ - \biggl( \frac {2}{10} \log_2 {\frac {2}{10}} + \frac {8}{10} \log_2 {\frac {8}{10}} \biggl) \biggl] + \frac {20}{30} \times \biggl[ - \biggl( \frac {13}{20} \log_2 {\frac {13}{20}} + \frac {7}{20} \log_2 {\frac {7}{20}} \biggl) \biggl] = 0.8634\] \[\text {자식마디의 엔트로피(학급)} = \frac {14}{30} \times \biggl[ - \biggl( \frac {6}{14} \log_2 {\frac {6}{14}} + \frac {8}{14} \log_2 {\frac {8}{14}} \biggl) \biggl] + \frac {16}{30} \times \biggl[ - \biggl( \frac {9}{16} \log_2 {\frac {9}{16}} + \frac {7}{16} \log_2 {\frac {7}{16}} \biggl) \biggl] = 0.9871\]부모마디의 엔트로피에서 자식마디의 엔트로피를 뺀 값을 정보이득(Information Gain)이라고 합니다. 결국 정보이득이 큰 분리규칙을 찾는 것입니다. 각 분리규칙에 대한 정보이득을 계산해보겠습니다.
\[\text {정보이득(성별)} = 1 − 0.8634 = 0.1366\] \[\text {정보이득(학급)} = 1 − 0.9871 = 0.0129\]정보이득을 계산해보니 성별을 기준으로 분리할 때 순수도를 높여준다는 것을 알 수 있습니다.
정보이득비 (Information Gain Ratio)
엔트로피는 범주형 입력변수가 사용될 때 비중이 큰 범주로 편향(bias)이 생기는 단점이 있습니다. 그리고 목표변수가 3개 이상의 범주를 갖는 다지분리에서는 분리되는 가지의 수가 늘어날수록 엔트로피가 감소합니다. 다지분리 모형에서 정도이득을 기준으로 순수도를 평가하면 가지를 많아지게 하는 경향이 발생합니다. 가지가 많아지면 해석과 활용에 불편하므로 나무는 단순할수록 좋습니다. 따라서 C5.0과 같은 다지분리 알고리즘에서에서는 정보이득비를 대신 사용합니다. 정보이득비는 정보이득을 분리정보(Split Information)로 나눈 값입니다.
분리정보는 다음과 같은 공식이 적용됩니다.
\[\text {분리정보(D)} = - \sum {\frac {|D_j|}{D} log_2 {\frac {|D_j|}{D}}}\]위 식에서 D는 부모마디에 속한 관측값의 수이고 $ D_j $는 각 자식마디에 속한 각각의 관측값의 수입니다. 이번 예제에서의 분리정보를 계산하면 다음과 같습니다.
\[\text {분리정보} = - \biggl[ \frac {10}{30} \log_2 {\frac {10}{30}} + \frac {20}{30} \log_2 {\frac {20}{30}} \biggl] = 0.9183\]따라서 정보이득을 분리정보로 나눈 정보이득비를 계산하면 최적의 분리규칙을 정할 수 있습니다.
카이제곱 통계량 (Chi-square statistics)
카이제곱 통계량은 앞에서 보여드린 분할표(Contingency table)를 이용하여 두 범주로 나누는 것이 통계적으로 유의한지 검증할 때 사용됩니다. 카이제곱 통계량의 계산식은 다음과 같습니다.
\[\text {카이제곱 통계량} = \sum \frac {\text{(관측값-기대값)}^2} {\text{기대값}}\]위 식을 이용하여 자식마디에서의 카이제곱 통계량을 각각 구해보겠습니다.
\[\text {자식마디의 카이제곱(성별)} = \frac {(2-5)^2}{5} + \frac {(8-5)^2}{5} + \frac {(13-10)^2}{10} + \frac {(7-10)^2}{10} = 5.4\] \[\text {자식마디의 카이제곱(학급)} = \frac {(6-7)^2}{7} + \frac {(8-7)^2}{7} + \frac {(9-8)^2}{8} + \frac {(7-8)^2}{8} = 0.5\]카이제곱 통계량이 클수록 두 범주로 나누었을 때 통계적으로 유의한 결과가 나올 확률이 높습니다. 이번 예제에서는 카이제곱 통계량 기준으로 분리규칙을 비교할 때 역시 성별로 나누는 것이 맞습니다.
이상으로 의사결정나무로 분류모형을 적합할 때 순수도의 기준으로 3가지를 살펴보았습니다. 앞서 언급한 바와 같이 의사결정나무로 회귀모형도 적합할 수 있습니다. 이 경우, 순수도의 기준은 아래 기준으로 정해지는 데 이번 포스팅에서는 회귀나무를 다루지 않을 예정이므로 간단하게 설명만 하겠습니다.
분산분석의 F-통계량 (F-statistics) or t검정의 t-통계량
의사결정나무로 회귀모형을 적합할 때 순수도의 기준으로는 입력변수의 분리규칙이 3개 이상일 때는 분산분석의 F-통계량을, 2개일 때는 t검정의 t-통계량을 사용합니다. 통계량이 가장 큰 분리규칙을 정합니다.
분산의 감소량
분산의 감소량은 자식마디의 분산의 합이 가장 작은 분리규칙을 선택하는 것입니다.
2. 정지규칙
정지규칙은 더이상 가지의 분리가 일어나지 않도록 (나무가 성장하지 않도록) 하는 규칙입니다. 정지규칙은 분석가가 분류모형을 적합할 때 설정해주는 것입니다. 다음과 같은 조건을 만족할 때 나무의 성장이 정지됩니다.
- 모든 관측값이 하나의 마디에 속할 때
- 마디에 속하는 관측값의 수가 일정 기준 이하일 때
- 뿌리마디로부터 나무의 깊이(Depth)가 기준값에 도달했을 때
- 순수도의 증가량 또는 불순도의 감소량이 아주 작을 때
3. 가지치기
나무가 성장하면 할수록 분류모형은 과적합이 될 가능성이 높아집니다. 아래 그림을 보면 쉽게 이해할 수 있습니다.
 [4]
[4]
가로축으로 분류모형이 복잡해질수록 훈련셋(Training dataset)의 에러는 감소합니다. 훈련셋에 과적합되므로 모형을 적합할 때 사용되지 않은 시험셋(Test dataset)을 적용하면 오차가 감소하다가 어느 시점 이후로는 다시 급격하게 증가하게 됩니다.
앞에서 설명한 바와 같이 의사결정나무는 과적합하는 경향이 있으므로 가지치기를 해주어야 합니다. 의사결정나무에서는 비용복잡도 가지치기 (Cost Complexity Pruning)이라고 하는데 다음과 같은 공식을 활용합니다.
\[\text {비용복잡도(T)} = \text {오분류율(T)} + \alpha \times |\text {T}|\] \[\begin{cases} \text {오분류율} : \text{전체 관측치의 수에서 잘못 분류된 관측치의 비중} \\ \alpha: \text{복잡도 파라미터로 0보다 큰 값으로 분석가가 정함} \\ |\text {T}|: \text{나무(T) 끝마디의 개수} \\ \end{cases}\]위 공식은 다음과 같이 해석합니다. 일반적으로 나무가 커질수록 과적합하기 때문에 오분류율이 감소하므로 비용복잡도는 낮아집니다. 하지만 나무가 커진다는 것은 끝마디의 개수가 늘어난다는 것입니다. 그 결과 복잡도 파라미터를 곱한 값이 증가하게 되므로 비용복잡도는 오히려 증가할 수 있습니다. 따라서 가지치기란 비용복잡도 기준으로 끝마디의 개수를 조절하는 것이며, 이 때 모형 성능 향상에 기여도가 낮은 (불필요한) 가지를 잘라내게 됩니다.
4. 모형의 평가
- 분류모형 : 각 끝마디에서 목표변수의 범주별 비중을 확인하고 가장 많은 범주로 라벨링(Labeling) 합니다. 예컨데 [Yes/No] 이진분리 모형을 적합했는데 어떤 끝마디에 속한 건수가 100이고, 그 중에서 [Yes]가 60, [No]가 40이면 해당 마디에 속한 100 건을 [Yes]로 추정하는 것입니다. 이 때 이 끝마디의 오분류율은 40%가 됩니다. 이렇게 전체 끝마디마다 Labeling한 뒤 전체 오분류율을 계산하여 모형의 분류성능을 평가할 수 있습니다.
- 회귀모형 : 최종모형은 각 끝마디마다 목표변수의 평균을 추정값으로 제공합니다. 회귀모형의 성능을 평가하는 지표는 추정값과 실제값과의 차인 에러를 계산하는 방법을 주로 사용합니다. 따라서 MSE(Mean Squared Error), RMSE(Root Mean Squared Error), MAPE(Mean Absolute Percentage Error) 등을 계산합니다. 회귀모형의 성능을 평가하는 지표는 별도의 포스팅으로 정리할 예정입니다.
알고리즘에 관한 설명은 이정도로 마무리하고 실습을 통해 의사결정나무를 이해하는 시간을 가져보도록 하겠습니다.
의사결정나무 따라하기
이번 포스팅에서는 온라인에 공개되어 있는 UniversalBank.csv 파일을 불러와서 개인대출을 받은 고객을 골라내는 분류모형을 적합합니다. 데이터 컬럼별 상세는 다음과 같습니다.
- ID : 고객번호 (1 ~ 5000)
- Age : 나이 (23 ~ 67)
- Experience : 경력 (-3 ~ 43)
- Income : 소득 (8 ~ 224)
- ZIP Code : 우편번호
- Family : 가족수 (1 ~ 4)
- CCAvg : 월별 신용카드 평균 사용금액 (0 ~ 10)
- Education : 교육수준 (UG = 1, Grad = 2, Prof = 3)
- Mortgage : 주택담보대출 잔액 (0 ~ 635)
- PersonalLoan : 개인대출 보유여부 (yes = 1, no = 0)
- SecuritiesAccount : 증권계좌 보유여부 (yes = 1, no = 0)
- CDAccount : CD계좌 보유여부 (yes = 1, no = 0)
- Online : 온라인뱅킹 이용여부 (yes = 1, no = 0)
- CreditCard : 신용카드 이용여부 (yes = 1, no = 0)
# 데이터를 불러옵니다.
# 원래 위치 : https://raw.githubusercontent.com/gchoi/Dataset/master/UniversalBank.csv
bank <- read.csv(file = 'https://goo.gl/vE8GyN')
# 데이터의 구조를 파악합니다.
str(object = bank)
## 'data.frame': 5000 obs. of 14 variables:
## $ ID : int 1 2 3 4 5 6 7 8 9 10 ...
## $ Age : int 25 45 39 35 35 37 53 50 35 34 ...
## $ Experience : int 1 19 15 9 8 13 27 24 10 9 ...
## $ Income : int 49 34 11 100 45 29 72 22 81 180 ...
## $ ZIP.Code : int 91107 90089 94720 94112 91330 92121 91711 93943 90089 93023 ...
## $ Family : int 4 3 1 1 4 4 2 1 3 1 ...
## $ CCAvg : num 1.6 1.5 1 2.7 1 0.4 1.5 0.3 0.6 8.9 ...
## $ Education : int 1 1 1 2 2 2 2 3 2 3 ...
## $ Mortgage : int 0 0 0 0 0 155 0 0 104 0 ...
## $ PersonalLoan : int 0 0 0 0 0 0 0 0 0 1 ...
## $ SecuritiesAccount: int 1 1 0 0 0 0 0 0 0 0 ...
## $ CDAccount : int 0 0 0 0 0 0 0 0 0 0 ...
## $ Online : int 0 0 0 0 0 1 1 0 1 0 ...
## $ CreditCard : int 0 0 0 0 1 0 0 1 0 0 ...
# 미리보기 합니다.
head(x = bank, n = 5L)
## ID Age Experience Income ZIP.Code Family CCAvg Education Mortgage
## 1 1 25 1 49 91107 4 1.6 1 0
## 2 2 45 19 34 90089 3 1.5 1 0
## 3 3 39 15 11 94720 1 1.0 1 0
## 4 4 35 9 100 94112 1 2.7 2 0
## 5 5 35 8 45 91330 4 1.0 2 0
## PersonalLoan SecuritiesAccount CDAccount Online CreditCard
## 1 0 1 0 0 0
## 2 0 1 0 0 0
## 3 0 0 0 0 0
## 4 0 0 0 0 0
## 5 0 0 0 0 1
불러온 데이터는 5000행, 14개 컬럼으로 이루어진 데이터 프레임입니다. 모든 컬럼이 다 숫자형 벡터인 특징이 있습니다. 그런데 다섯 번째 컬럼인 ZIP.Code는 숫자가 아니므로 문자형 또는 범주형 벡터로 변환해주어야 하지만 이번 예제에서는 사용하지 않아도 될 것 같으므로 제거하도록 하겠습니다.
# 불필요한 컬럼 삭제합니다. (ID & ZIP.Code)
bank <- bank[, -c(1, 5)]
# 요약통계량을 확인합니다.
summary(object = bank)
## Age Experience Income Family
## Min. :23.00 Min. :-3.0 Min. : 8.00 Min. :1.000
## 1st Qu.:35.00 1st Qu.:10.0 1st Qu.: 39.00 1st Qu.:1.000
## Median :45.00 Median :20.0 Median : 64.00 Median :2.000
## Mean :45.34 Mean :20.1 Mean : 73.77 Mean :2.396
## 3rd Qu.:55.00 3rd Qu.:30.0 3rd Qu.: 98.00 3rd Qu.:3.000
## Max. :67.00 Max. :43.0 Max. :224.00 Max. :4.000
## CCAvg Education Mortgage PersonalLoan
## Min. : 0.000 Min. :1.000 Min. : 0.0 Min. :0.000
## 1st Qu.: 0.700 1st Qu.:1.000 1st Qu.: 0.0 1st Qu.:0.000
## Median : 1.500 Median :2.000 Median : 0.0 Median :0.000
## Mean : 1.938 Mean :1.881 Mean : 56.5 Mean :0.096
## 3rd Qu.: 2.500 3rd Qu.:3.000 3rd Qu.:101.0 3rd Qu.:0.000
## Max. :10.000 Max. :3.000 Max. :635.0 Max. :1.000
## SecuritiesAccount CDAccount Online CreditCard
## Min. :0.0000 Min. :0.0000 Min. :0.0000 Min. :0.000
## 1st Qu.:0.0000 1st Qu.:0.0000 1st Qu.:0.0000 1st Qu.:0.000
## Median :0.0000 Median :0.0000 Median :1.0000 Median :0.000
## Mean :0.1044 Mean :0.0604 Mean :0.5968 Mean :0.294
## 3rd Qu.:0.0000 3rd Qu.:0.0000 3rd Qu.:1.0000 3rd Qu.:1.000
## Max. :1.0000 Max. :1.0000 Max. :1.0000 Max. :1.000
목표변수인 PersonalLoan 컬럼이 숫자형 벡터이므로 범주형으로 변경해주어야 합니다.
# 목표변수를 범주형 벡터로 변환합니다. (PersonalLoan)
bank$PersonalLoan <- as.factor(x = bank$PersonalLoan)
# 목표변수의 범주별 비중을 확인합니다.
bank$PersonalLoan %>% table() %>% prop.table()
## .
## 0 1
## 0.904 0.096
목표변수의 범주별 비중을 확인해보니, 개인대출을 받은 고객이 전체 고객의 10% 미만입니다. 목표변수가 한 쪽으로 치우친 불균형된 데이터라는 것을 알 수 있습니다. 그리고 레벨의 순서가 ‘0’, ‘1’입니다. caret 패키지의 confusionMatrix() 함수는 목표변수의 levels를 확인하여 먼저오는 것을 positive로 인식하므로 우리는 목표변수의 levels 순서를 변경해줄 필요가 있습니다.
# 목표변수의 레벨을 변경합니다.
bank$PersonalLoan <- relevel(x = bank$PersonalLoan, ref = '1')
# 목표변수의 레벨이 잘 변경되었는지 확인합니다.
levels(x = bank$PersonalLoan)
## [1] "1" "0"
우리는 불균형된 데이터를 어떻게 하면 좋을지 이미 살펴본 바 있습니다. 그런데 이번 포스팅에서는 훈련셋의 목표변수 균형화 작업을 하지 않습니다. 왜냐하면, 그렇게 해봤더니 가지치기를 할 필요가 없는 분류모형이 적합되었기 때문입니다. 가지치기 실습이 중요하니 균형화 작업을 생략하고 전체 데이터를 7대 3의 비율로 훈련셋과 시험셋으로 나누기만 하겠습니다.
# 전체 데이터셋의 70%를 훈련용, 30%를 시험용 데이터로 분리합니다.
# 같은 결과를 얻기 위해 seed를 설정합니다.
set.seed(seed = 1234)
# 전체 데이터를 임의로 샘플링하기 위해 다음과 같이 처리합니다.
idx <- sample(x = 2, size = nrow(x = bank), prob = c(0.7, 0.3), replace = TRUE)
# idx가 1일 때 trainSet, 2일 때 testSet에 할당합니다.
trainSet <- bank[idx == 1, ]
testSet <- bank[idx == 2, ]
# 훈련용, 시험용 데이터셋의 목표변수 비중을 확인합니다.
trainSet$PersonalLoan %>% table() %>% prop.table()
## .
## 1 0
## 0.0964539 0.9035461
testSet$PersonalLoan %>% table() %>% prop.table()
## .
## 1 0
## 0.09491525 0.90508475
이제 데이터 준비가 완료되었으니 의사결정나무 분류모형을 적합할 차례입니다. 앞에서 설명한 바와 같이 의사결정나무에는 여러 가지 알고리즘이 사용되고 있으며, R에서도 다양한 의사결정나무 함수들이 있습니다. 이번 포스팅에서는 rpart 패키지의 rpart() 함수만 활용하도록 하겠습니다. 이 함수에 사용되는 주요 인자들은 다음과 같습니다.
formula: 목표변수와 입력변수 간 관계식을 할당합니다.data: 모형 적합에 사용할 훈련용 데이터셋을 할당합니다.method:class(분류모형) 또는anova(회귀모형) 중 하나를 할당하면 됩니다. 생략하면 목표변수의 속성을 확인하여 범주형일 때class, 연속형일 때anova가 자동으로 할당됩니다.parms:method별로 파라미터를 지정할 수 있는데,anova는 별도의 파라미터가 필요없으며,class의 경우 순수도 기준(split)을 할당할 수 있습니다. 기본값은gini이며,information도 가능합니다.control: 정지규칙에 관한 설정을rpart.control()함수로 할당합니다.
rpart.control() 함수에 들어갈 주요 인자들도 함께 설명하겠습니다.
minsplit: 어느 마디의 관측값 개수가 이 설정값 이하일 때 더이상 분리되지 않습니다.minbucket: 끝마디에 속한 관측값의 수의 최소값을 설정합니다.minsplit이 설정되면 1/3에 해당하는 숫자가 자동으로 할당됩니다.cp: 비용복잡도에 사용할 파라미터(알파)를 설정합니다. 기본값은0.01입니다.maxdepth: 뿌리마디로부터 끝마디까지의 깊이(Depth) 최대값을 설정합니다. 기본값은30입니다.
# 필요 패키지를 불러옵니다.
library(rpart)
# 분류모형을 적합합니다.
fitTree <- rpart(formula = PersonalLoan ~ .,
data = trainSet,
method = 'class',
parms = list(split = 'gini'),
control = rpart.control(minsplit = 20,
cp = 0.01,
maxdepth = 10))
# 적합된 모형을 살펴봅니다.
summary(object = fitTree)
## Call:
## rpart(formula = PersonalLoan ~ ., data = trainSet, method = "class",
## parms = list(split = "gini"), control = rpart.control(minsplit = 20,
## cp = 0.01, maxdepth = 10))
## n= 3525
##
## CP nsplit rel error xerror xstd
## 1 0.30441176 0 1.0000000 1.0000000 0.05155083
## 2 0.14117647 2 0.3911765 0.4147059 0.03421892
## 3 0.04117647 3 0.2500000 0.2823529 0.02842241
## 4 0.02647059 4 0.2088235 0.2235294 0.02536267
## 5 0.01029412 5 0.1823529 0.2029412 0.02419095
## 6 0.01000000 9 0.1382353 0.1911765 0.02349288
##
## Variable importance
## Education Income Family CCAvg CDAccount Mortgage Age
## 30 28 20 13 5 3 1
##
## Node number 1: 3525 observations, complexity param=0.3044118
## predicted class=0 expected loss=0.0964539 P(node) =1
## class counts: 340 3185
## probabilities: 0.096 0.904
## left son=2 (770 obs) right son=3 (2755 obs)
## Primary splits:
## Income < 110.5 to the right, improve=157.54890, (0 missing)
## CCAvg < 2.95 to the right, improve=123.98300, (0 missing)
## CDAccount < 0.5 to the right, improve= 61.40191, (0 missing)
## Mortgage < 293.5 to the right, improve= 32.80038, (0 missing)
## Education < 1.5 to the right, improve= 13.67929, (0 missing)
## Surrogate splits:
## CCAvg < 3.225 to the right, agree=0.867, adj=0.390, (0 split)
## Mortgage < 294.5 to the right, agree=0.806, adj=0.110, (0 split)
## CDAccount < 0.5 to the right, agree=0.783, adj=0.006, (0 split)
##
## Node number 2: 770 observations, complexity param=0.3044118
## predicted class=0 expected loss=0.3792208 P(node) =0.2184397
## class counts: 292 478
## probabilities: 0.379 0.621
## left son=4 (275 obs) right son=5 (495 obs)
## Primary splits:
## Education < 1.5 to the right, improve=211.451400, (0 missing)
## Family < 2.5 to the right, improve=140.260400, (0 missing)
## CDAccount < 0.5 to the right, improve= 48.317130, (0 missing)
## Income < 156.5 to the right, improve= 13.702040, (0 missing)
## CCAvg < 3.95 to the right, improve= 6.813474, (0 missing)
## Surrogate splits:
## Family < 2.5 to the right, agree=0.744, adj=0.284, (0 split)
## CDAccount < 0.5 to the right, agree=0.694, adj=0.142, (0 split)
## CCAvg < 8.85 to the right, agree=0.648, adj=0.015, (0 split)
## Mortgage < 568 to the right, agree=0.648, adj=0.015, (0 split)
## Income < 116.5 to the left, agree=0.647, adj=0.011, (0 split)
##
## Node number 3: 2755 observations, complexity param=0.01029412
## predicted class=0 expected loss=0.01742287 P(node) =0.7815603
## class counts: 48 2707
## probabilities: 0.017 0.983
## left son=6 (186 obs) right son=7 (2569 obs)
## Primary splits:
## CCAvg < 2.95 to the right, improve=19.1570700, (0 missing)
## Income < 92.5 to the right, improve= 7.9237130, (0 missing)
## CDAccount < 0.5 to the right, improve= 1.3044200, (0 missing)
## Mortgage < 325 to the right, improve= 1.3038900, (0 missing)
## Age < 62.5 to the right, improve= 0.1463884, (0 missing)
##
## Node number 4: 275 observations, complexity param=0.04117647
## predicted class=1 expected loss=0.1236364 P(node) =0.07801418
## class counts: 241 34
## probabilities: 0.876 0.124
## left son=8 (221 obs) right son=9 (54 obs)
## Primary splits:
## Income < 116.5 to the right, improve=34.407540, (0 missing)
## CCAvg < 2.75 to the right, improve=11.714120, (0 missing)
## Experience < 38.5 to the left, improve= 3.733753, (0 missing)
## Age < 63.5 to the left, improve= 3.347071, (0 missing)
## CDAccount < 0.5 to the right, improve= 1.939394, (0 missing)
## Surrogate splits:
## Age < 65.5 to the left, agree=0.815, adj=0.056, (0 split)
## Experience < 40.5 to the left, agree=0.807, adj=0.019, (0 split)
##
## Node number 5: 495 observations, complexity param=0.1411765
## predicted class=0 expected loss=0.1030303 P(node) =0.1404255
## class counts: 51 444
## probabilities: 0.103 0.897
## left son=10 (54 obs) right son=11 (441 obs)
## Primary splits:
## Family < 2.5 to the right, improve=85.8242400, (0 missing)
## CDAccount < 0.5 to the right, improve=10.5835000, (0 missing)
## CCAvg < 6.635 to the left, improve= 1.5510780, (0 missing)
## Mortgage < 189 to the right, improve= 1.4346690, (0 missing)
## Age < 35.5 to the right, improve= 0.5672034, (0 missing)
##
## Node number 6: 186 observations, complexity param=0.01029412
## predicted class=0 expected loss=0.2365591 P(node) =0.05276596
## class counts: 44 142
## probabilities: 0.237 0.763
## left son=12 (13 obs) right son=13 (173 obs)
## Primary splits:
## CDAccount < 0.5 to the right, improve=7.931573, (0 missing)
## Income < 92.5 to the right, improve=7.537278, (0 missing)
## Mortgage < 277.5 to the right, improve=3.320066, (0 missing)
## Age < 61.5 to the right, improve=3.085095, (0 missing)
## Experience < 36.5 to the right, improve=3.085095, (0 missing)
##
## Node number 7: 2569 observations
## predicted class=0 expected loss=0.001557026 P(node) =0.7287943
## class counts: 4 2565
## probabilities: 0.002 0.998
##
## Node number 8: 221 observations
## predicted class=1 expected loss=0 P(node) =0.06269504
## class counts: 221 0
## probabilities: 1.000 0.000
##
## Node number 9: 54 observations, complexity param=0.02647059
## predicted class=0 expected loss=0.3703704 P(node) =0.01531915
## class counts: 20 34
## probabilities: 0.370 0.630
## left son=18 (11 obs) right son=19 (43 obs)
## Primary splits:
## CCAvg < 3.5 to the right, improve=8.0181660, (0 missing)
## Age < 60 to the left, improve=3.7898360, (0 missing)
## Experience < 34.5 to the left, improve=3.7898360, (0 missing)
## CreditCard < 0.5 to the left, improve=0.9204793, (0 missing)
## Income < 111.5 to the left, improve=0.7407407, (0 missing)
##
## Node number 10: 54 observations
## predicted class=1 expected loss=0.05555556 P(node) =0.01531915
## class counts: 51 3
## probabilities: 0.944 0.056
##
## Node number 11: 441 observations
## predicted class=0 expected loss=0 P(node) =0.1251064
## class counts: 0 441
## probabilities: 0.000 1.000
##
## Node number 12: 13 observations
## predicted class=1 expected loss=0.2307692 P(node) =0.003687943
## class counts: 10 3
## probabilities: 0.769 0.231
##
## Node number 13: 173 observations, complexity param=0.01029412
## predicted class=0 expected loss=0.1965318 P(node) =0.04907801
## class counts: 34 139
## probabilities: 0.197 0.803
## left son=26 (56 obs) right son=27 (117 obs)
## Primary splits:
## Income < 92.5 to the right, improve=5.274727, (0 missing)
## Age < 29.5 to the left, improve=2.447491, (0 missing)
## Experience < 3.5 to the left, improve=1.954857, (0 missing)
## CCAvg < 4.85 to the left, improve=1.746949, (0 missing)
## Family < 2.5 to the right, improve=1.426529, (0 missing)
## Surrogate splits:
## Age < 58.5 to the right, agree=0.723, adj=0.143, (0 split)
## Experience < 34.5 to the right, agree=0.723, adj=0.143, (0 split)
## Mortgage < 248.5 to the right, agree=0.699, adj=0.071, (0 split)
## CCAvg < 5.3 to the right, agree=0.694, adj=0.054, (0 split)
##
## Node number 18: 11 observations
## predicted class=1 expected loss=0.09090909 P(node) =0.003120567
## class counts: 10 1
## probabilities: 0.909 0.091
##
## Node number 19: 43 observations
## predicted class=0 expected loss=0.2325581 P(node) =0.01219858
## class counts: 10 33
## probabilities: 0.233 0.767
##
## Node number 26: 56 observations, complexity param=0.01029412
## predicted class=0 expected loss=0.375 P(node) =0.01588652
## class counts: 21 35
## probabilities: 0.375 0.625
## left son=52 (26 obs) right son=53 (30 obs)
## Primary splits:
## Education < 1.5 to the right, improve=7.547436, (0 missing)
## Family < 2.5 to the right, improve=4.705556, (0 missing)
## Income < 104.5 to the left, improve=2.710882, (0 missing)
## CCAvg < 4.25 to the left, improve=2.704545, (0 missing)
## Mortgage < 40.5 to the right, improve=1.575000, (0 missing)
## Surrogate splits:
## Income < 102.5 to the left, agree=0.679, adj=0.308, (0 split)
## Family < 1.5 to the right, agree=0.679, adj=0.308, (0 split)
## CCAvg < 4.25 to the left, agree=0.679, adj=0.308, (0 split)
## Age < 60.5 to the right, agree=0.643, adj=0.231, (0 split)
## Mortgage < 40.5 to the right, agree=0.643, adj=0.231, (0 split)
##
## Node number 27: 117 observations
## predicted class=0 expected loss=0.1111111 P(node) =0.03319149
## class counts: 13 104
## probabilities: 0.111 0.889
##
## Node number 52: 26 observations
## predicted class=1 expected loss=0.3461538 P(node) =0.007375887
## class counts: 17 9
## probabilities: 0.654 0.346
##
## Node number 53: 30 observations
## predicted class=0 expected loss=0.1333333 P(node) =0.008510638
## class counts: 4 26
## probabilities: 0.133 0.867
summary() 함수로 분류모형을 출력하면, 여러 가지 정보가 나옵니다만 우리가 봐야 할 것은 두 번째와 세 번째 표입니다. 두 번째 표는 비용복잡도(CP) 파라미터별로 가지가 분리되는 횟수, 실제 오차와 교차검증 오차를 제시합니다. 우리는 모형을 적합할 때 비용복잡도 파라미터를 기본값인 0.01로 정했기 때문에 그 기준으로 분리된 개수가 9입니다. 이는 끝마디가 10개라는 것을 의미입니다.
세 번째 표는 변수별 중요도를 보여줍니다. 이번 예제에서는 Education, Income, Family, CCAvg 순으로 오분류율이 낮은 모형을 만드는 데 높은 기여를 했다는 것을 알 수 있습니다.
나머지 내용은 분류모형에 관한 설명을 한 것인데, 아무래도 텍스트로 되어 있다보니 한 눈에 들어오지 않습니다. 따라서 전체 분류모형은 그림을 그려서 설명하도록 하겠지만, 첫 분기되는 것을 설명하면 다음과 같습니다.
뿌리마디에는 3,525건의 관측값이 속해 있는데, ‘0’과 ‘1’ 중에서 ‘0’의 비중이 조금 더 높으므로 뿌리마디는 ‘0’으로 추정(Labeling)됩니다. 이 때 오분류율은 0.0964539입니다. 뿌리마디에 속한 데이터에 대해 여러 개의 분리규칙(Primary splits)을 만들어 비교해본 결과, 지니지수 기준으로 가장 순수도를 높일 수 있는 분리규칙은 [Income < 110.5]였습니다. 즉, Income이 110.5 미만인 3,185건이 오른쪽 자식마디로, 그리고 Income이 110.5 이상인 340건이 왼쪽 자식마디로 할당된 것이죠. 각각의 확률(비중)은 0.096, 0.904입니다.
나무모형을 텍스트로 간단하게 출력해보는 방법이 따로 있습니다. 적합된 분류모형을 출력하면 됩니다.
# 나무모형을 출력합니다.
print(fitTree)
## n= 3525
##
## node), split, n, loss, yval, (yprob)
## * denotes terminal node
##
## 1) root 3525 340 0 (0.096453901 0.903546099)
## 2) Income>=110.5 770 292 0 (0.379220779 0.620779221)
## 4) Education>=1.5 275 34 1 (0.876363636 0.123636364)
## 8) Income>=116.5 221 0 1 (1.000000000 0.000000000) *
## 9) Income< 116.5 54 20 0 (0.370370370 0.629629630)
## 18) CCAvg>=3.5 11 1 1 (0.909090909 0.090909091) *
## 19) CCAvg< 3.5 43 10 0 (0.232558140 0.767441860) *
## 5) Education< 1.5 495 51 0 (0.103030303 0.896969697)
## 10) Family>=2.5 54 3 1 (0.944444444 0.055555556) *
## 11) Family< 2.5 441 0 0 (0.000000000 1.000000000) *
## 3) Income< 110.5 2755 48 0 (0.017422868 0.982577132)
## 6) CCAvg>=2.95 186 44 0 (0.236559140 0.763440860)
## 12) CDAccount>=0.5 13 3 1 (0.769230769 0.230769231) *
## 13) CDAccount< 0.5 173 34 0 (0.196531792 0.803468208)
## 26) Income>=92.5 56 21 0 (0.375000000 0.625000000)
## 52) Education>=1.5 26 9 1 (0.653846154 0.346153846) *
## 53) Education< 1.5 30 4 0 (0.133333333 0.866666667) *
## 27) Income< 92.5 117 13 0 (0.111111111 0.888888889) *
## 7) CCAvg< 2.95 2569 4 0 (0.001557026 0.998442974) *
출력 결과에서 오른쪽 끝에 *가 출력된 것이 끝마디입니다. 세어보니 10개입니다. 이걸로는 어떻게 나무가 어떤 형태를 갖는지 알기 어려우니 나무모형을 그림으로 그려보겠습니다.
# 한글 폰트를 설정합니다.
par(family = 'NanumGothic')
# 나무모형을 그립니다.
plot(x = fitTree,
compress = TRUE,
uniform = TRUE,
branch = 0.8,
margin = 0.1,
main = 'Classification Tree for Universal Bank')
# 분리기준을 추가로 출력합니다.
text(x = fitTree,
use.n = TRUE,
all = TRUE,
cex = 0.8)
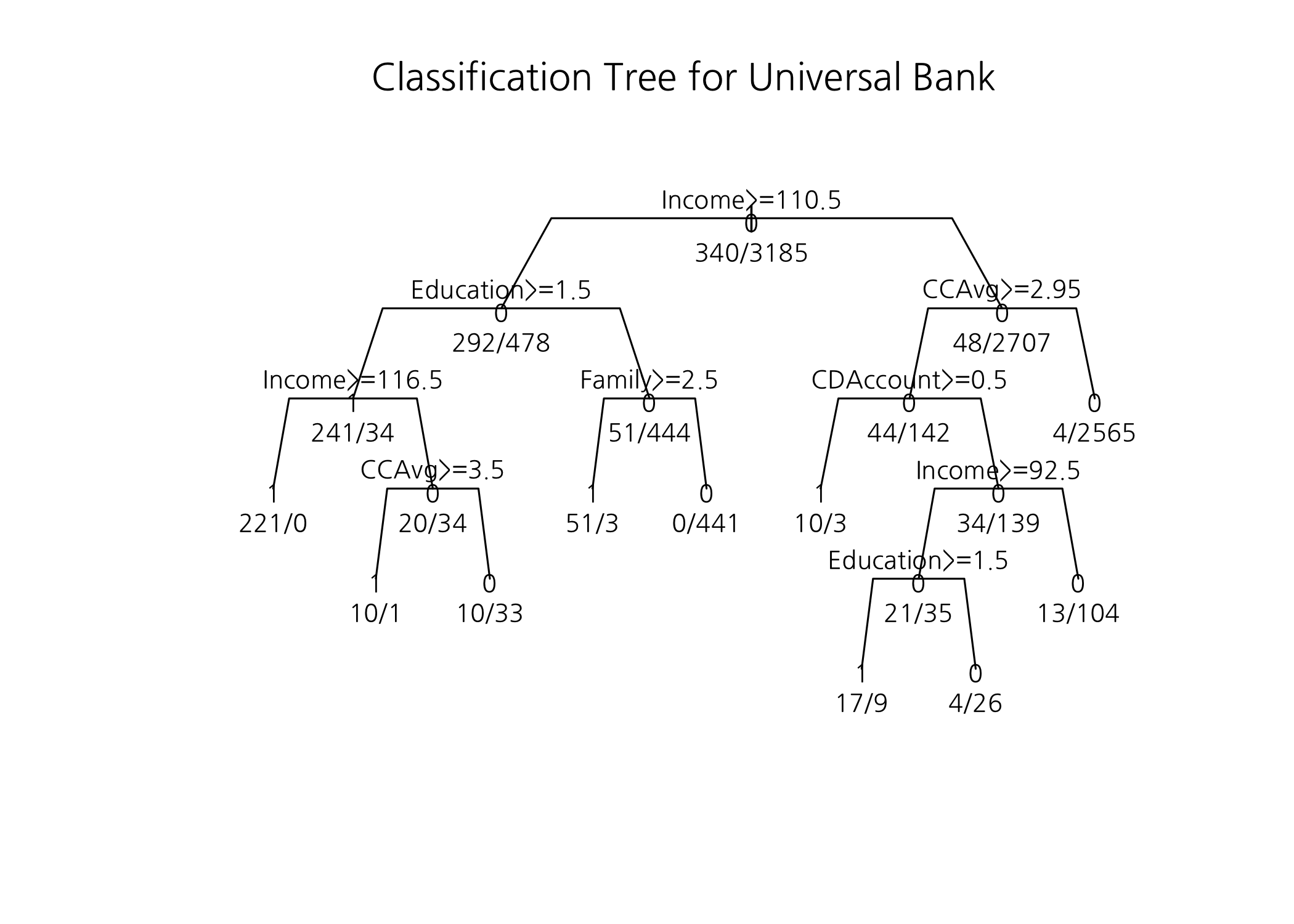
확실하게 텍스트보다는 그림이 더 눈에 잘 들어옵니다. 끝마디의 개수를 세어보면 모두 10개라는 것을 알 수 있습니다. 그리고 끝마디별로 ‘1’ 또는 ‘0’으로 Labeling되어 있음을 알 수 있습니다. 가장 왼쪽에 있는 끝마디에 출력된 숫자 221/0는 목표변수의 범주 중 ‘1’이 221건이고, ‘0’이 0건이라는 의미입니다. 따라서 이 끝마디에 속한 관측값(데이터)은 ‘1’로 추정됩니다. 운이 좋게도 이 끝마디의 오분류율은 0입니다. 이런 식으로 각각의 끝마디마다 목표변수의 범주별 비중을 기준으로 Labeling을 해준 것입니다. 만약 의사결정나무 결과로 마케팅에 활용할 고객을 타겟팅한다면 끝마디의 추정 범주가 ‘1’인 것 중 오분류율이 낮은 순서대로 타겟팅하면 됩니다.
기본 그림이라 별로입니다. 그렇죠? 대안으로 rpart.plot 패키지에 속한 함수 두 가지를 소개해드리겠습니다.
# 보기 좋은 나무그림을 그릴 수 있습니다.
library(rpart.plot)
rpart.plot(x = fitTree)
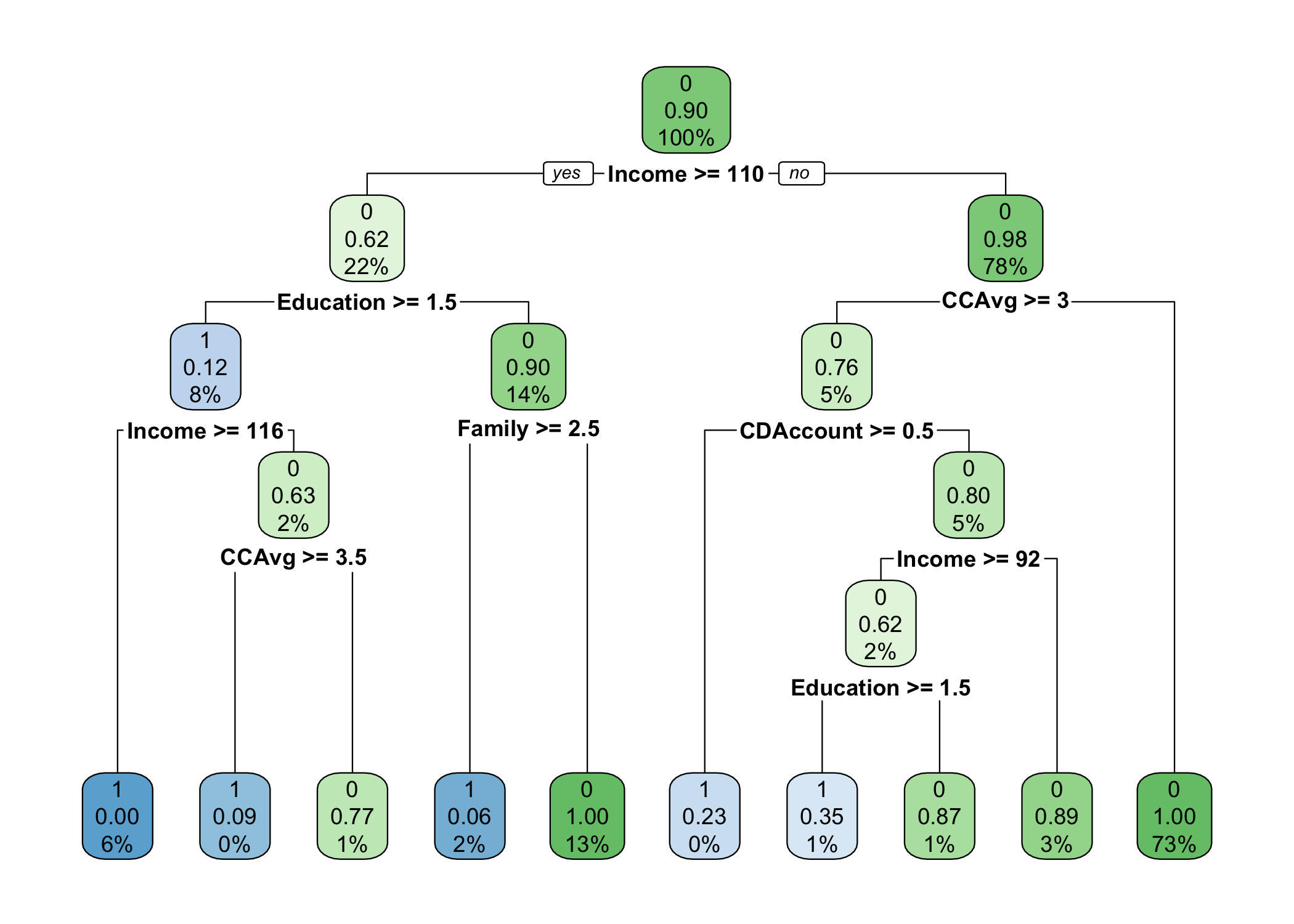
이 그림은 한결 낫습니다. 비록 각 끝마디에 속한 관측값의 수는 알 수 없지만 Labeling 결과와 오분류율, 그리고 전체 관측값 중 비중을 한 번에 알 수 있습니다.
나무그림 하나만 더 그려볼까요? rpart.plot 패키지에 prp() 함수도 있는데요. faclen 인자에 0을 할당하면 범주형 목표변수의 레이블을 출력해줍니다. 그리고 extra 인자에 101을 할당하면 끝마디에 목표변수의 범주별 빈도수를 출력합니다. 앞에서 기본형 함수로 그림을 그렸을 때 text() 함수의 use.n = TRUE와 같은 기능을 하는 것이죠. box.pal을 지정하지 않으면 그냥 하얀색으로 출력되어 심심합니다. 각자 기호에 맞게 설정하면 되겠습니다.
# 나만의 팔레트를 설정합니다.
library(RColorBrewer)
myPal <- brewer.pal(n = 3, name = 'Set2')
# 다른 나무그림도 소개합니다.
prp(x = fitTree,
faclen = 0,
cex = 0.8,
extra = 101,
box.pal = myPal[fitTree$frame$yval])
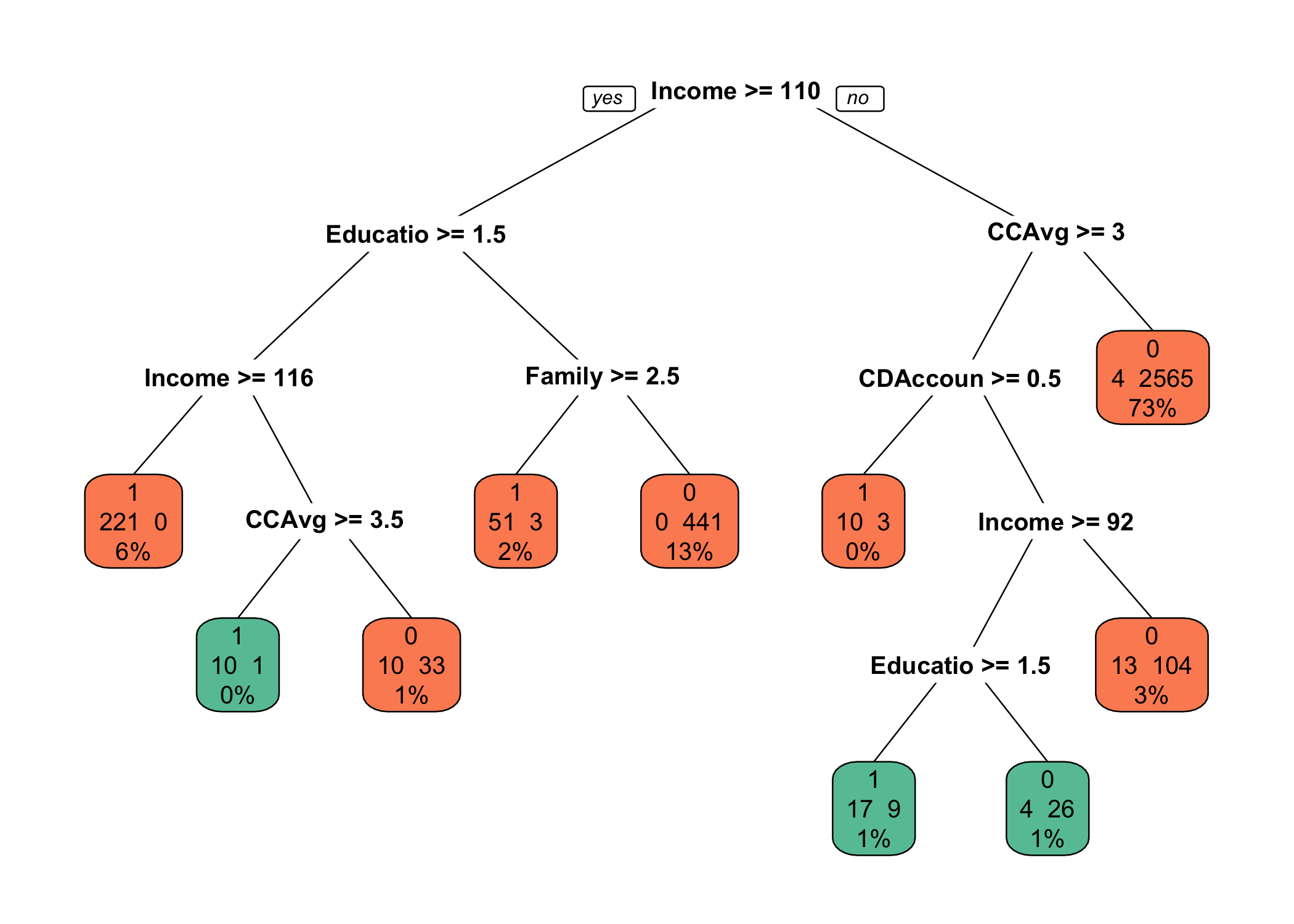
다음으로 방금 적합한 분류모형에 대해 가지치기를 해야할지 판단해야 합니다. printcp() 함수를 실행해보겠습니다.
# 비용복잡도 표를 출력합니다.
printcp(x = fitTree)
##
## Classification tree:
## rpart(formula = PersonalLoan ~ ., data = trainSet, method = "class",
## parms = list(split = "gini"), control = rpart.control(minsplit = 20,
## cp = 0.01, maxdepth = 10))
##
## Variables actually used in tree construction:
## [1] CCAvg CDAccount Education Family Income
##
## Root node error: 340/3525 = 0.096454
##
## n= 3525
##
## CP nsplit rel error xerror xstd
## 1 0.304412 0 1.00000 1.00000 0.051551
## 2 0.141176 2 0.39118 0.41471 0.034219
## 3 0.041176 3 0.25000 0.28235 0.028422
## 4 0.026471 4 0.20882 0.22353 0.025363
## 5 0.010294 5 0.18235 0.20294 0.024191
## 6 0.010000 9 0.13824 0.19118 0.023493
분류모형 출력했을 때 두 번째로 출력된 표와 같습니다. 여기에서 우리가 확인해야 할 것은 xerror가 가장 작은 행이 어떤 것인지 찾는 것입니다. 현재로는 최종 모형이 가장 좋습니다. 즉, 가지치기를 할 필요가 없다는 것이죠. 그래도 가지치기 실습을 꼭 해봐야 하니 처음 모형을 만들었을 때 코드에서 cp를 0.001, maxdepth를 30으로 바꿔서 분류모형을 다시 적합해보겠습니다. cp에 할당되는 값이 작을수록, maxdepth에 할당되는 값이 커질수록 가지의 수가 많아집니다.
# 분류모형을 다시 적합합니다.
fitImsi <- rpart(formula = PersonalLoan ~ .,
data = trainSet,
method = 'class',
parms = list(split = 'gini'),
control = rpart.control(minsplit = 20,
cp = 0.001,
maxdepth = 30))
# 적합된 모형을 살펴봅니다.
printcp(x = fitImsi)
##
## Classification tree:
## rpart(formula = PersonalLoan ~ ., data = trainSet, method = "class",
## parms = list(split = "gini"), control = rpart.control(minsplit = 20,
## cp = 0.001, maxdepth = 30))
##
## Variables actually used in tree construction:
## [1] CCAvg CDAccount Education Experience Family Income
## [7] Online
##
## Root node error: 340/3525 = 0.096454
##
## n= 3525
##
## CP nsplit rel error xerror xstd
## 1 0.3044118 0 1.00000 1.00000 0.051551
## 2 0.1411765 2 0.39118 0.41765 0.034335
## 3 0.0411765 3 0.25000 0.28529 0.028566
## 4 0.0264706 4 0.20882 0.22941 0.025687
## 5 0.0102941 5 0.18235 0.20588 0.024362
## 6 0.0014706 9 0.13824 0.18529 0.023135
## 7 0.0010000 13 0.13235 0.22941 0.025687
나무모형이 더 커졌습니다. 끝마디의 개수가 14개인 것으로 보입니다. nsplit이 9일 때 xerror이 가장 낮습니다. 그러므로 끝마디의 개수가 10인 나무가 가장 좋다는 의미입니다. 그래프로 그려보면 더 보기 좋겠죠? plotcp() 함수가 있습니다. 이 그래프는 나무가 성장함에 따라, 끝마디 개수가 증가함에 따라 relative cross-validation error가 어떻게 변하는지 보여줍니다. 가로 점선보다 아래에 있는 나무모형을 선택하면 되는데요. 가장 낮은 값을 선택합니다.
# 교차확인 상대오차 도표를 확인합니다.
plotcp(x = fitImsi)
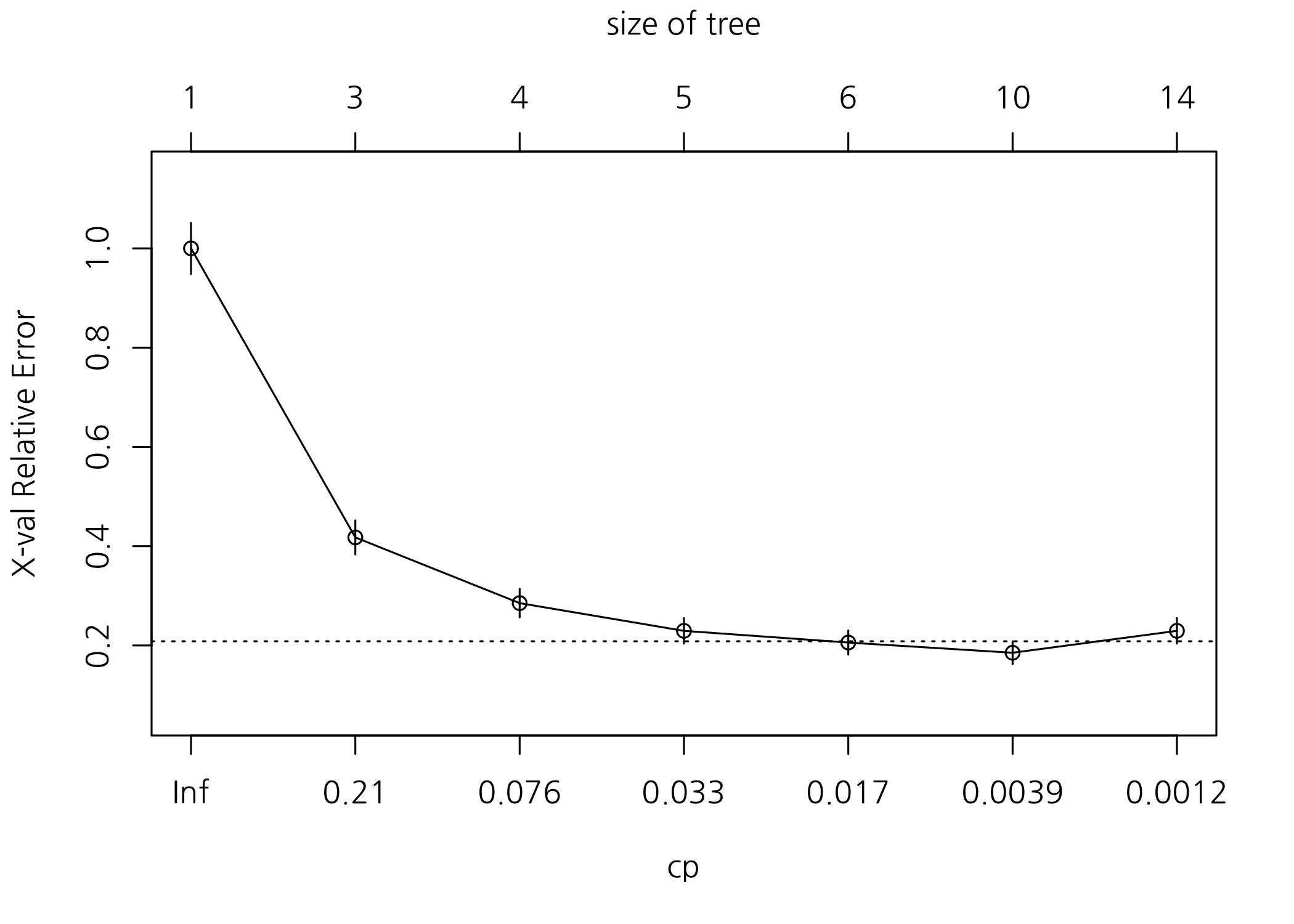
그래프로 그려보니 끝마디의 개수가 10일 때가 가장 좋다는 것을 알 수 있습니다. xerror이 최소값일 때의 cp를 비용복잡도 파라미터로 갖는 나무모형으로 가지치기하러 갑시다!
# xerror이 가장 낮을 때의 비용복잡도 파라미터를 구합니다.
bestCP <- fitImsi$cptable[which.min(fitImsi$cptable[ , 'xerror']), 'CP']
# bestCP를 출력합니다.
print(bestCP)
## [1] 0.001470588
# 가지치기(pruning)를 합니다.
fitPrun <- prune.rpart(tree = fitImsi, cp = bestCP)
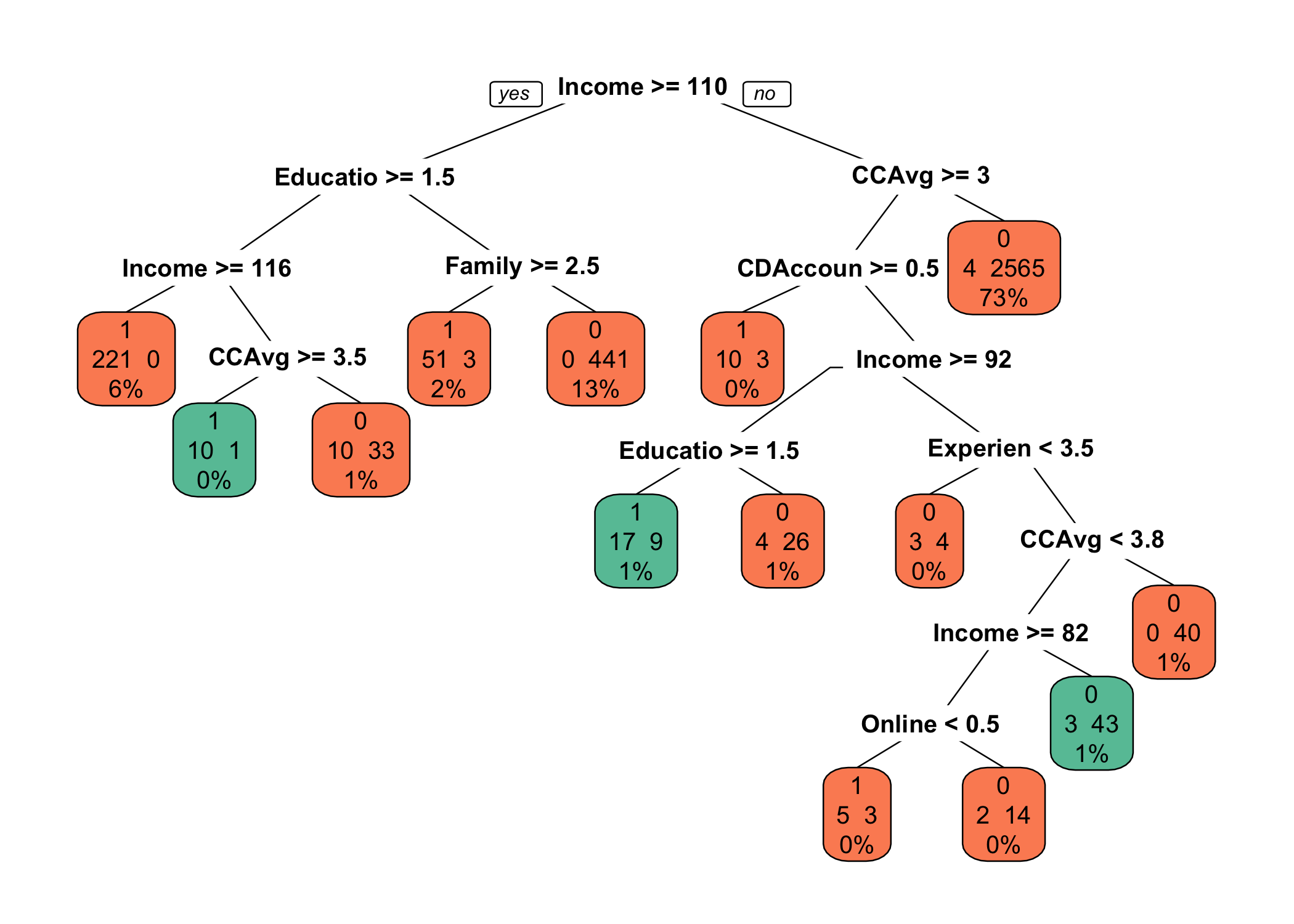
bestCP는 0.001470588이었습니다. 가지치기 전후 모형을 그림으로 확인해보도록 하죠.
# 가지치기 전 모형을 그림으로 출력합니다.
prp(x = fitImsi,
faclen = 0,
cex = 0.8,
extra = 101,
box.pal = myPal[fitImsi$frame$yval])
# 가지치기 후 모형을 그림으로 출력합니다.
prp(x = fitPrun,
faclen = 0,
cex = 0.8,
extra = 101,
box.pal = myPal[fitPrun$frame$yval])
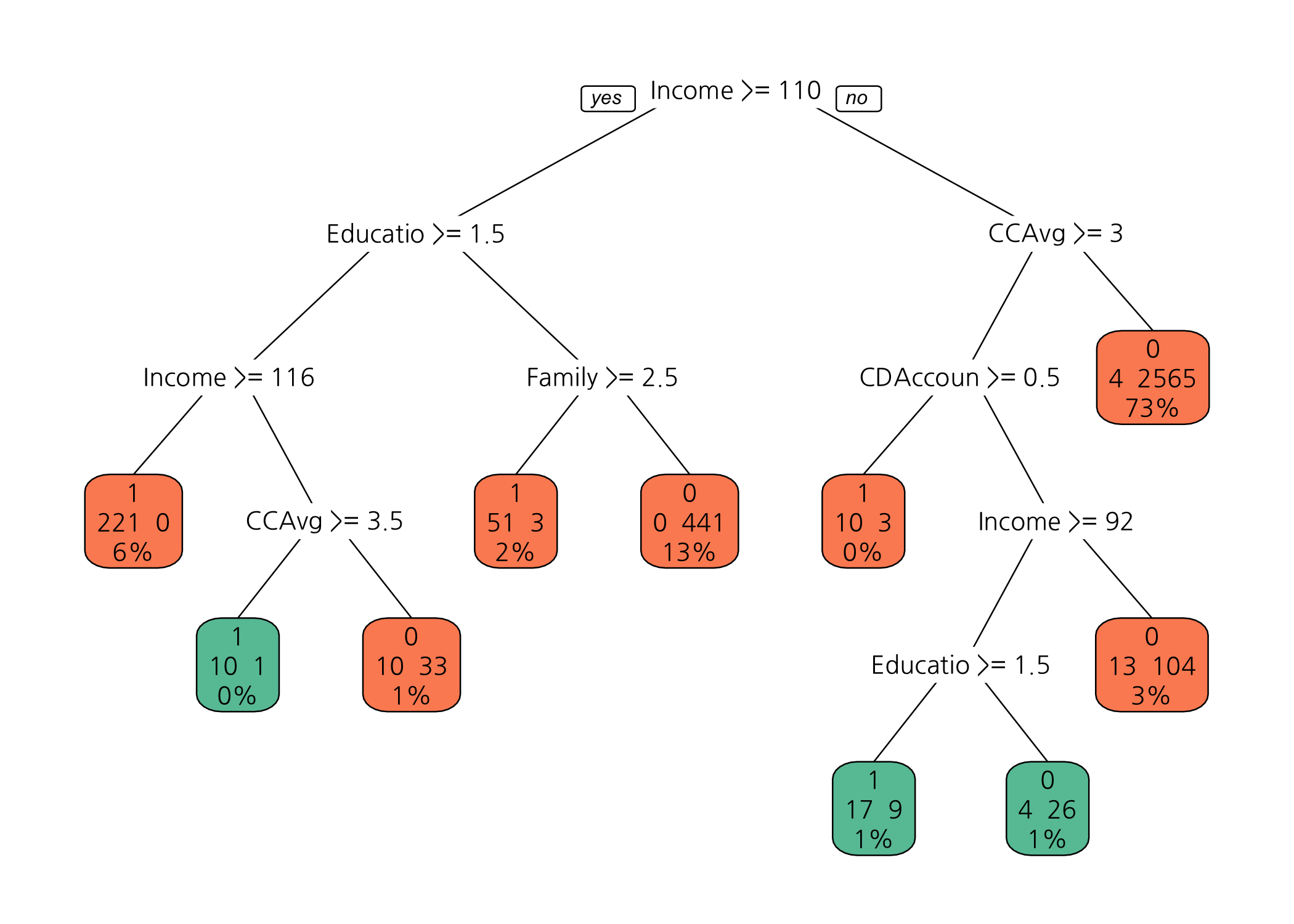
가지치기를 한 모형이 좀 더 깔끔해진 (느낌 같은) 느낌이 듭니다. 실제로 현업에서 마케팅에 활용하기에도 가지치기를 한 심플한 모형이 더 낫습니다.
가지치기까지 했으니 cp에 0.001을 할당한 가지치기 전 모형과 가지치기 한 모형의 분류 성능을 비교하기 위해 혼동행렬과 ROC 커브를 그려보겠습니다.
# 각각의 모형에 시험셋을 적용하여 추정값을 만듭니다.
predImsi <- predict(object = fitImsi, newdata = testSet, type = 'class')
predPrun <- predict(object = fitPrun, newdata = testSet, type = 'class')
# 혼동행렬에 필요한 패키지를 불러옵니다.
library(caret)
# 첫 번째 모형의 혼동행렬 지표들을 확인합니다.
confusionMatrix(data = predImsi, reference = testSet$PersonalLoan)
## Confusion Matrix and Statistics
##
## Reference
## Prediction 1 0
## 1 130 14
## 0 10 1321
##
## Accuracy : 0.9837
## 95% CI : (0.9759, 0.9895)
## No Information Rate : 0.9051
## P-Value [Acc > NIR] : <2e-16
##
## Kappa : 0.9065
## Mcnemar's Test P-Value : 0.5403
##
## Sensitivity : 0.92857
## Specificity : 0.98951
## Pos Pred Value : 0.90278
## Neg Pred Value : 0.99249
## Prevalence : 0.09492
## Detection Rate : 0.08814
## Detection Prevalence : 0.09763
## Balanced Accuracy : 0.95904
##
## 'Positive' Class : 1
##
민감도가 0.92857, 특이도가 0.98951, 그리고 정밀도는 0.90278로 모형의 분류 성능이 아주 뛰어납니다. 당연히 F1 점수도 높을 것 같습니다.
# F1 점수에 필요 패키지를 불러옵니다.
library(MLmetrics)
# 첫 번째 모형의 추정 레이블과 실제값으로 F1 점수를 확인합니다.
F1_Score(y_pred = predImsi, y_true = testSet$PersonalLoan)
## [1] 0.915493
F1 점수는 0.915493으로 예상대로 아주 높은 값이 나왔습니다. ROC커브를 그리고 AUROC도 확인하겠습니다. 지난 포스팅에서 만든 함수를 사용하면 편리하겠죠?
# ROC 커브를 그리고, AUROC를 계산하는 사용자 정의 함수를 만듭니다.
checkROC <- function(prob, real, title = 'ROC 커브') {
# ROC 커브에 필요 패키지를 불러옵니다.
library(ROCR)
# 추정값 및 실제값이 범주형인 경우, 숫자 벡터로 변환합니다.
if(class(x = prob) == 'factor') prob <- as.numeric(x = prob)
if(class(x = real) == 'factor') real <- as.numeric(x = real)
# ROC 커브를 그려서 분류 성능을 확인합니다.
predObj <- prediction(predictions = prob,
labels = real)
# prediction 객체를 활용하여 performance 객체를 생성합니다.
perform <- performance(prediction.obj = predObj,
measure = 'tpr',
x.measure = 'fpr')
# 한글이 제대로 출력되도록 설정합니다.
par(family = 'NanumGothic')
# ROC 커브를 그립니다.
plot(x = perform, main = title)
# 왼쪽 아래 모서리에서 오른쪽 위 모서리를 잇는 대각선을 추가합니다.
lines(x = c(0, 1), y = c(0, 1), col = 'red', lty = 2)
# AUROC에 필요 패키지를 불러옵니다.
library(pROC)
# AUROC를 계산하고 ROC 커브 위에 출력합니다.
auroc <- auc(real, prob) %>% round(digits = 4L)
text(x = 0.9, y = 0, labels = str_c('AUROC : ', auroc), col = 'red')
}
첫 번째 모형의 시험용 데이터셋으로 ROC 커브를 그리고 AUROC를 출력합니다.
# ROC 커브를 그리고 AUROC를 출력합니다.
checkROC(prob = predImsi,
real = testSet$PersonalLoan,
title = 'ROC 커브 - 가지치기 하기 전 모형 (CP = 0.001)')
## Loading required package: gplots
##
## Attaching package: 'gplots'
## The following object is masked from 'package:stats':
##
## lowess
## Type 'citation("pROC")' for a citation.
##
## Attaching package: 'pROC'
## The following objects are masked from 'package:stats':
##
## cov, smooth, var
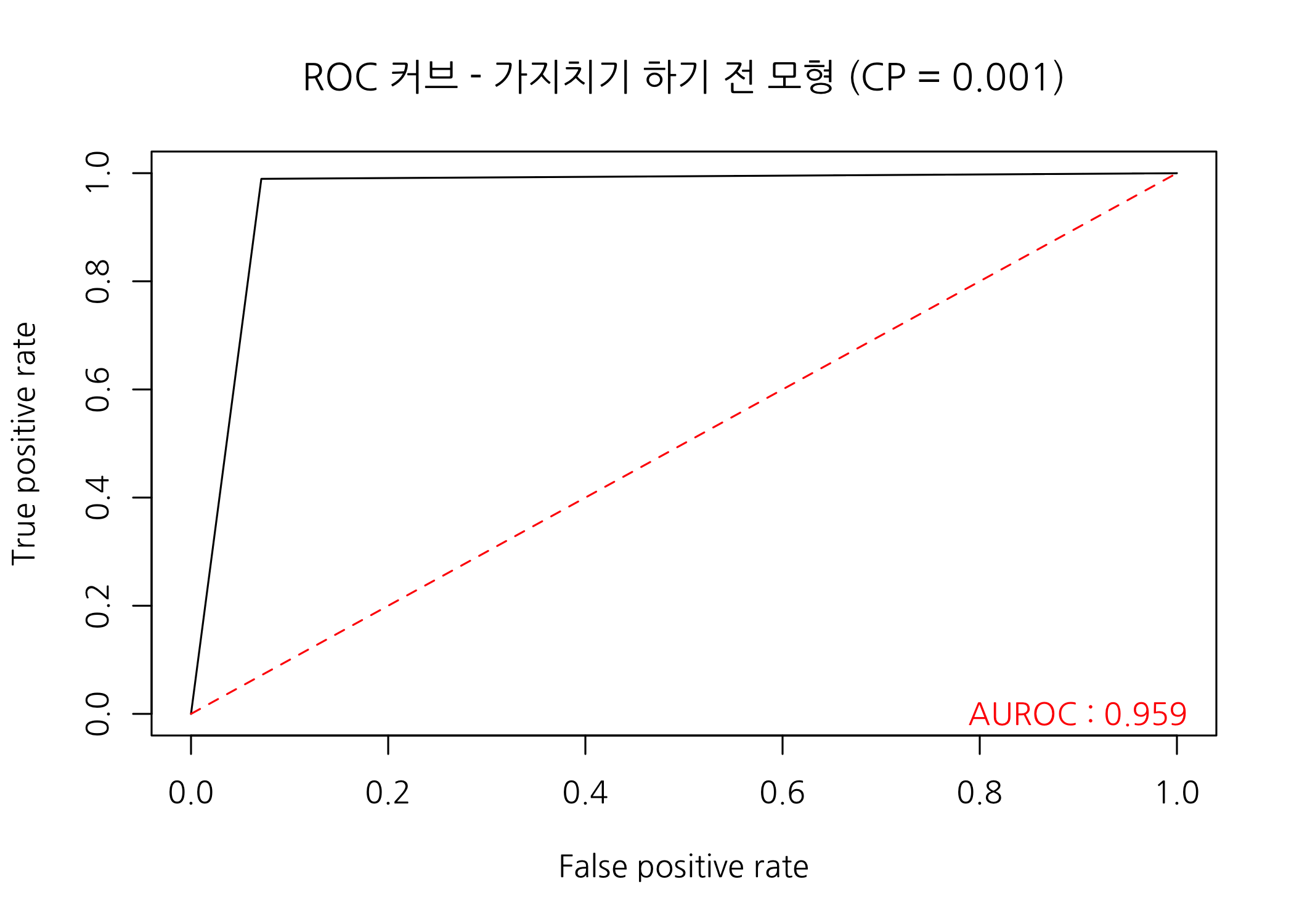
AUROC가 0.959입니다. 상당히 양호한 것 같습니다.
그럼 가지치기한 두 번째 모형에 대해서 같은 평가 지표를 확인해보겠습니다.
# 두 번째 모형의 혼동행렬 지표들을 확인합니다.
confusionMatrix(data = predPrun, reference = testSet$PersonalLoan)
## Confusion Matrix and Statistics
##
## Reference
## Prediction 1 0
## 1 130 8
## 0 10 1327
##
## Accuracy : 0.9878
## 95% CI : (0.9808, 0.9928)
## No Information Rate : 0.9051
## P-Value [Acc > NIR] : <2e-16
##
## Kappa : 0.9285
## Mcnemar's Test P-Value : 0.8137
##
## Sensitivity : 0.92857
## Specificity : 0.99401
## Pos Pred Value : 0.94203
## Neg Pred Value : 0.99252
## Prevalence : 0.09492
## Detection Rate : 0.08814
## Detection Prevalence : 0.09356
## Balanced Accuracy : 0.96129
##
## 'Positive' Class : 1
##
민감도가 0.92857, 특이도가 0.99401, 그리고 정밀도는 0.94203로 출력된 것으로 보아 가지치기 전 모형에 비해 분류 성능이 조금씩 더 개선된 것 같습니다. 그럼 F1 점수도 좋아졌겠죠?
# 두 번째 모형의 추정 레이블과 실제값으로 F1 점수를 확인합니다.
F1_Score(y_pred = predPrun, y_true = testSet$PersonalLoan)
## [1] 0.9352518
역시 F1 점수가 조금 더 올랐네요. 0.9352518입니다. 마지막으로 ROC 커브를 그리고 AUROC를 확인하겠습니다.
# ROC 커브를 그리고 AUROC를 출력합니다.
checkROC(prob = predPrun,
real = testSet$PersonalLoan,
title = 'ROC 커브 - 가지치기 한 모형 (CP = 0.003)')
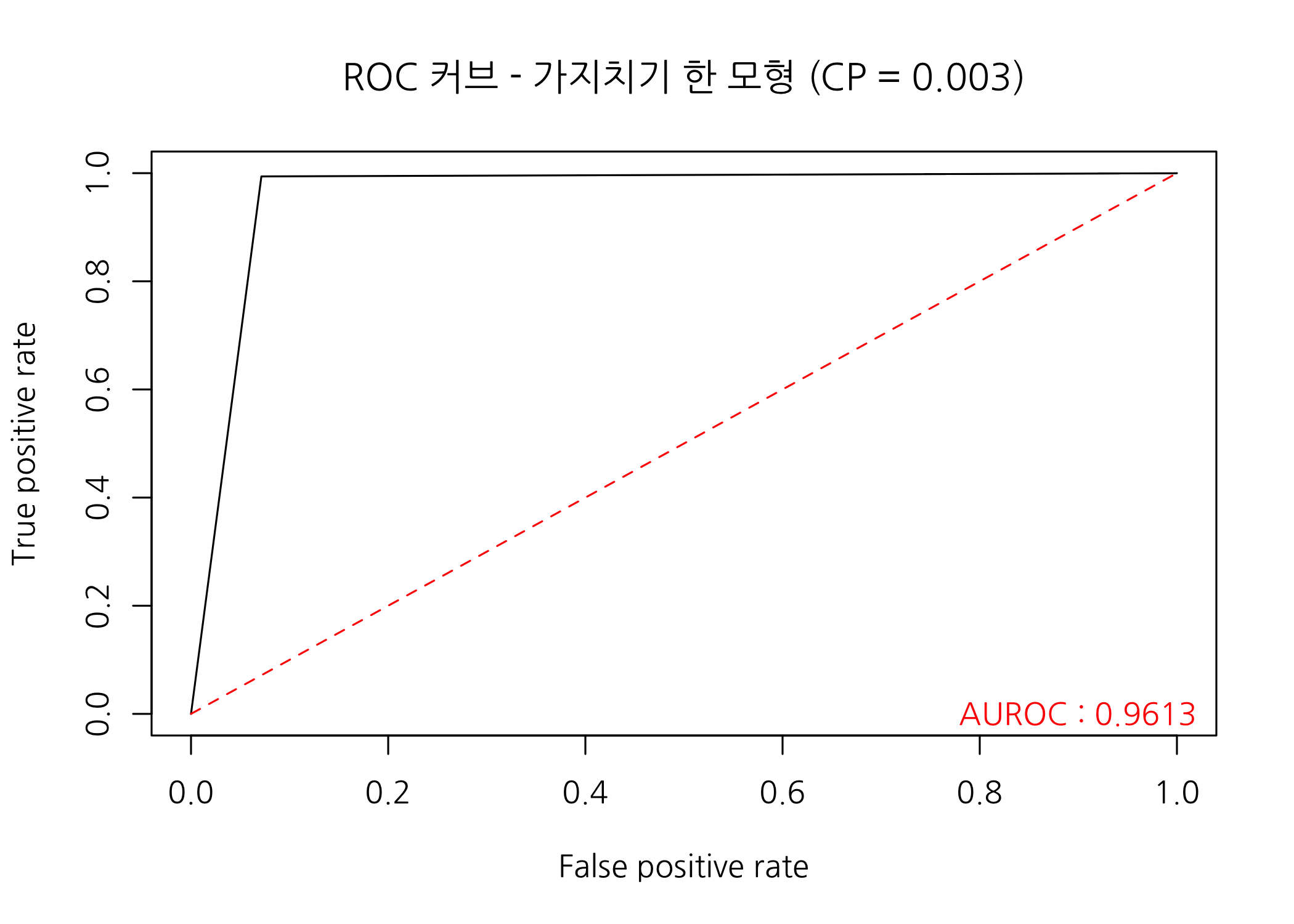
AUROC가 0.9613입니다. 분류성능이 소폭이나마 좋아졌습니다.
이번 포스팅에서 의사결정나무로 분류모형을 적합할 때 가지치기의 중요성까지 알고 가신다면 더할 나위 없을 것 같습니다.
[3] 자세한 사항은 관련 위키백과를 참고하기 바랍니다.
[4] 출처 : http://www.luigifreda.com/2017/03/22/bias-variance-tradeoff/