로지스틱 회귀분석 (Logistic Regression)
이 글은 2018~2019년에 작성한 R 기반 강의 노트를 옮긴 것입니다. 코드 일부는 현재 패키지 버전과 다를 수 있습니다.
이번 포스팅은 분류모형 네 번째 소개로 로지스틱 회귀분석입니다. 로지스틱 회귀분석은 범주형인 목표변수를 입력변수들의 선형결합으로 표현한 것입니다. 로지스틱 회귀모형을 적합하면 입력변수마다 회귀계수가 산출되고 목표변수의 추정값으로 0~1 값을 갖는 확률을 얻게 됩니다.
로지스틱 회귀분석은 목표변수의 범주 개수에 따라 이항(binomial) 또는 다항(multinomial) 로지스틱 회귀분석으로 구분할 수 있습니다. 목표변수의 범주 개수가 2개인 이항 로지스틱 회귀분석은 목표변수의 추정값에 대한 기준점(cut-off)으로 Labeling 합니다. 일반적으로 cut-off를 0.5로 설정하므로 추정값이 0.5 미만일 때는 ‘0’, 0.5 이상일 때는 ‘1’로 Labeling 하는 것이죠.[1] 다항 로지스틱 회귀분석의 경우 추정값(확률)이 가장 큰 범주로 Labeling 합니다.
로지스틱 회귀분석 알고리즘
앞에서 로지스틱 회귀분석에 대해 간단하게 설명한 바와 같이 로지스틱 회귀모형의 추정값은 0~1의 값을 갖습니다. 이항 로지스틱 회귀분석에서 추정값 p를 성공할 확률이라고 하면 1-p는 실패할 확률로 해석할 수 있습니다. 성공할 확률은 입력변수(열벡터) X가 주어졌을 때 y가 1일 확률이 되며, 이를 조건부 확률로 표현하면 다음과 같습니다.
\[P(y = 1| X)\]한편, 로지스틱 회귀분석에서는 오즈(Odds) 개념이 중요합니다. 오즈는 성공할 확률(p)이 실패할 확률(1-p)의 몇 배인지를 의미합니다. 오즈를 수식으로 표현하면 다음과 같습니다.
\[\text {Odds} = \frac {p}{1-p} = \frac {P(y = 1 | X)}{P(y = 0 | X)}\]오즈에 네이피어 상수(e)를 밑으로 하는 자연로그를 씌우면 로짓함수 (Logit Function)가 되며, 이 함수의 x축은 0~1, y축은 -∞ ~ ∞ 값을 갖습니다. (아래 왼쪽 그래프) 하지만 로지스틱 회귀모형의 추정값은 0~1의 값을 가지므로 로짓함수에 대해 y = x 대칭을 해줍니다. (아래 오른쪽 그래프) 마지막으로 로짓함수를 입력변수들의 선형결합으로 바꿔주면 비로소 로지스틱 회귀모형이 됩니다.
 [2]
[2]
이상의 설명을 수식으로 표현하면 다음과 같습니다.
\[\ln {\biggl( \frac {p}{1-p} \biggl)} = \text {logit}(p)\]위 식에서 로그를 벗기기 위해 네이피어 상수(e)를 밑으로 하는 지수함수로 씌워주면 아래와 같이 표현됩니다.
\[\frac {p}{1-p} = \exp \biggl( \text{logit}(p) \biggl)\]편의상 로짓함수를 입력변수가 p개인 선형결합으로 바꾼 뒤, 위 식을 성공할 확률 p로 정리하면 첫 번째 식을 y = x 대칭을 한 것과 같습니다.
가능도 함수 (Likelihood Function)
로지스틱 회귀분석은 회귀계수의 추정을 위해 가능도 함수를 사용합니다. 가능도 함수는 가지고 있는 데이터(표본)로 모수를 추정할 때 사용하는 것으로 다음과 같이 표현됩니다.
\[L(\theta | x) = P(X = x | \theta) \quad \text {(단, } X \text {는 확률변수이고 } \theta \text{는 모수)}\]위 식에서 오른쪽 항을 풀어쓰면 다음과 같습니다.
\[P(X = x | \theta) = P(x_1, x_2, ⋯, x_n | \theta)\] \[= P(x_1 | \theta) \times P(x_2 | \theta) \times ⋯ \times P(x_n | \theta)\] \[L(\theta | x) = \prod_{i=1}^{n} P(x_i | \theta)\]위 식의 양변에 자연로그를 씌우면 확률의 곱을 로그 확률의 합으로 바꿔 표현할 수 있습니다.
\[\ln L(\theta | x) = \ln \sum_{i=1}^{n} P(x_i | \theta)\]최대 로그 가능도 방법 (Maxium Log Likelihood Method)
우리는 실제값 y가 1일 때 성공할 확률 p가 1에 가깝게 추정되고, 실제값 y가 0일 때 실패할 확률 1-p가 1에 가깝게 하는 회귀 계수를 추정해야 합니다. 따라서 로지스틱 회귀모형의 각 계수를 추정하기 위해 가능도 함수를 적용하면 다음과 같습니다.
양변에 자연로그를 씌워 정리하면 다음과 같습니다.
\[\ln L(\beta) = \sum_{i=1}^n \biggl[ y_i \ln p_i + (1-y_i) \ln (1-p_i) \biggl]\] \[= \sum_{i=1}^n \biggl[ y_i \ln p_i - y_i \ln (1-p_i) + \ln (1-p_i) \biggl]\] \[= \sum_{i=1}^n \biggl[ y_i \ln \frac {p_i}{1-p_i} + \ln (1-p_i) \biggl]\] \[\ln \frac {p}{1-p} = \text {logit}(p) = \beta^TX, \quad \ln(1-p) = -\ln(1 + e^{\beta^TX}) \space \text {이므로}\] \[\ln L(\beta) = \sum_{i=1}^n \biggl[ y_i \beta^TX - \ln(1 + e^{\beta^TX}) \biggl]\]따라서 로그 가능도(Log Likeihood, LL)를 최대로 하는 회귀계수를 계산하면 됩니다. 또는 -2LL을 최소화하는 문제로 바꿀 수 있습니다.
로지스틱 회귀모형의 유의성 검정
이 포스팅에서는 로지스틱 회귀모형의 유의성 검정 방법에 대해 다음과 같은 두 가지를 소개합니다.
1. 두 모형 간 편차(deviance) 비교 (카이제곱 검정)
로지스틱 회귀모형이 유의한지 여부는 상수항만 사용된 회귀모형(M0)과 입력변수가 사용된 회귀모형(Mp) 간 편차(deviance)를 비교함으로써 확인할 수 있습니다. R에서 로지스틱 회귀모형을 적합하면 두 모형의 편차를 제공합니다. Null deviance는 상수항만 사용된 회귀모형의 편차이고, Residual deviance는 입력변수가 사용된 회귀모형입니다. 이 두 편차의 차이를 카이제곱 통계량으로 사용하여 두 모형 간 유의한 차이가 있는지 확인하면 됩니다. 카이제곱 검정 시, 두 모형의 자유도 차이를 카이제곱 통계량의 자유도로 사용합니다. 검정 결과, 유의확률(p-value)이 0.05보다 작으면 두 모형 간 유의한 차이가 있으므로 입력변수가 사용된 회귀모형이 유의하다고 판단합니다. R에서 카이제곱 검정에 사용하는 함수는 pchisq()입니다.
2. 두 모형 간 로그 가능도 비(ratio) 통계량
상수항만 사용된 회귀모형과 입력변수가 사용된 회귀모형 간 로그 가능도 비 통계량을 이용하는 방법이 있습니다. 로그 가능도 비는 아래 식처럼 표현할 수 있습니다.
\[\text {Log Likelihood Ration} = -2(LL(M_0) - LL(M_p)) = -2 \ln \biggl( \frac {L(M_0)}{L(M_p)} \biggl)\]두 모형이 완벽하게 일치하면 로그의 진수(= 가능도 비)는 1이 되므로, 로그 가능도 비는 0이 됩니다. R에서 로그 가능도 비 검정에 사용하는 함수는 lmtest 패키지의 lrtest() 함수입니다. 검정 결과, 유의확률(p-value)이 0.05보다 작으면 입력변수가 사용된 회귀모형(Mp)이 유의하다고 판단합니다.
로그 가능도 비 검정은 하나의 회귀계수에 대한 검정방법으로도 사용할 수 있습니다. 즉, 하나의 입력변수를 포함한 모형과 제외한 모형을 각각 적합한 수 로그 가능도 비 검정을 실시하면 해당 회귀계수의 유의성 검정이 되는 것이죠.
로지스틱 회귀계수의 유의성 검정
로지스틱 회귀계수의 유의성 검정은 z-검정 또는 Wald 검정을 통해 확인할 수 있습니다. z 통계량과 Wald 통계량은 다음의 공식을 이용합니다.
\[z = \frac {\hat \beta - \beta_0}{\sigma_{\hat \beta}} \sim N(0, 1), \quad W^2 = \frac {(\hat \beta - \beta_0)^2}{\sigma_{\hat \beta}^2} \sim \chi_1^2\]z-검정과 Wald 검정은 선형회귀계수의 유의성 검정 방법인 t-검정의 역할을 합니다. 두 검증의 귀무가설은 회귀계수가 0이라고 가정합니다. 따라서 위 식에서 분자항에 있는 β0는 귀무가설에 의해 0으로 치환되므로 z-검정통계량은 회귀계수를 표준오차로 나눈 값으로 정규분포를 따르고, Wald 통계량은 회귀계수와 표준오차를 각각 제곱하여 나눈 값으로 카이제곱분포를 따릅니다. 두 검정의 유의확률은 같은 값을 출력합니다. 검증 결과, 유의확률이 0.05보다 작으면 귀무가설을 기각할 수 있으므로 회귀계수는 0이 아니라고 판단합니다.
로지스틱 회귀모형 활용하기 (오즈비의 해석)
입력변수가 하나인 로지스틱 회귀모형에서 오즈는 다음과 같이 표현됩니다.
\[\text {Odds} = \frac {p}{1-p} = e^{\beta_0 + \beta_1 x_1}\]오즈비(Odds Ratio)는 2개의 오즈 간 비율이며, 다음과 같이 표현됩니다.
\[\text {Odds Ratio} = \frac {e^{\beta_0 + \beta_1 (x_1 + 1)}}{e^{\beta_0 + \beta_1 x_1}} = e^{\beta_1}\]위 식을 통해, 입력변수가 1단위 증가할 때 회귀모형의 추정값이 오즈비만큼 증가한다는 것을 알 수 있습니다.
이항 로지스틱 회귀분석 따라하기
온라인에 공개되어 있는 binary.csv 파일을 내려받아 대학교 지원자들의 고등학교 성적으로 합격 또는 불합격 여부를 설명하는 이항 로지스틱 회귀모형을 적합하는 실습을 해보겠습니다. 데이터 컬럼별 상세는 다음과 같습니다.
admit: 합격 여부 (0, 1)gre: 영어 성적gpa: 학점rank: 출신 고등학교 등급 (1~4)
# 데이터를 불러옵니다.
univ <- read.csv(file = 'https://stats.idre.ucla.edu/stat/data/binary.csv')
# 데이터의 구조를 파악합니다.
str(object = univ)
## 'data.frame': 400 obs. of 4 variables:
## $ admit: int 0 1 1 1 0 1 1 0 1 0 ...
## $ gre : int 380 660 800 640 520 760 560 400 540 700 ...
## $ gpa : num 3.61 3.67 4 3.19 2.93 3 2.98 3.08 3.39 3.92 ...
## $ rank : int 3 3 1 4 4 2 1 2 3 2 ...
# 미리보기 합니다.
head(x = univ, n = 10L)
## admit gre gpa rank
## 1 0 380 3.61 3
## 2 1 660 3.67 3
## 3 1 800 4.00 1
## 4 1 640 3.19 4
## 5 0 520 2.93 4
## 6 1 760 3.00 2
## 7 1 560 2.98 1
## 8 0 400 3.08 2
## 9 1 540 3.39 3
## 10 0 700 3.92 2
400행 4열로 이루어진 데이터셋임을 확인할 수 있습니다. 모든 컬럼이 숫자형 벡터인데요. 이 중에서 admit과 rank는 범주형 벡터로 변환하고 요약데이터를 확인하겠습니다.
# admit, rank를 범주형으로 변환합니다.
univ$admit <- as.factor(x = univ$admit)
univ$rank <- as.factor(x = univ$rank)
# 요약데이터를 확인합니다.
summary(object = univ)
## admit gre gpa rank
## 0:273 Min. :220.0 Min. :2.260 1: 61
## 1:127 1st Qu.:520.0 1st Qu.:3.130 2:151
## Median :580.0 Median :3.395 3:121
## Mean :587.7 Mean :3.390 4: 67
## 3rd Qu.:660.0 3rd Qu.:3.670
## Max. :800.0 Max. :4.000
전체 400명 중 합격자가 127명, 불합격자가 273명입니다. gre(영어성적)은 최소 220점부터 최대 800점까지 분포하고 있으며 평균은 587.7입니다. gpa(학점)의 경우 최소 2.26부터 최대 4.00까지 분포하고 있구요. 지원자의 출신 고등학교 rank(등급)은 2~3 등급에 집중되어 있음을 알 수 있습니다.
이번 예제의 목표변수는 admit입니다. 요약데이터를 확인하면서 합격/불합격 빈도수를 확인할 수 있었는데요. 비중은 얼마나 될까요?
# 목표변수(admit)의 비율을 확인합니다.
univ$admit %>% table() %>% prop.table()
## .
## 0 1
## 0.6825 0.3175
전체 400명 중 31.75%가 합격자라는 것을 알 수 있습니다.
분석할 데이터에 대한 파악은 이 정도로 마치고 로지스틱 회귀모형을 적합해보겠습니다. 로지스틱 회귀모형은 glm() 함수를 이용합니다. 로지스틱 회귀분석은 연결함수로 로짓함수를 사용하는 일반화 선형모형(Generalized Linear Model)의 일종입니다. 그래서인지 R함수명도 glm()을 사용하는 것 같습니다. 이 함수의 주요 인자는 다음과 같습니다.
formula: 목표변수와 입력변수 간 관계를 표현합니다.data: 로지스틱 회귀모형에 사용될 데이터셋을 할당합니다.family: glm은 목표변수의 분포에 따라family를 지정해주어야 합니다. 로지스틱 회귀분석의 목표변수는 이항분포(binomial)를 따르므로binomial을 할당합니다. 연결함수는 생략해도 무방하지만 제대로(?) 하기 위해logit으로 설정합니다.
이상의 간단한 설정만으로 로지스틱 회귀모형을 쉽게 적합할 수 있습니다.
# 이항 로지스틱 회귀모형을 적합합니다.
fitLR1 <- glm(formula = admit ~ .,
data = univ,
family = binomial(link = 'logit'))
# 모형 적합 결과를 확인합니다.
summary(fitLR1)
##
## Call:
## glm(formula = admit ~ ., family = binomial(link = "logit"), data = univ)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.6268 -0.8662 -0.6388 1.1490 2.0790
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -3.989979 1.139951 -3.500 0.000465 ***
## gre 0.002264 0.001094 2.070 0.038465 *
## gpa 0.804038 0.331819 2.423 0.015388 *
## rank2 -0.675443 0.316490 -2.134 0.032829 *
## rank3 -1.340204 0.345306 -3.881 0.000104 ***
## rank4 -1.551464 0.417832 -3.713 0.000205 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 499.98 on 399 degrees of freedom
## Residual deviance: 458.52 on 394 degrees of freedom
## AIC: 470.52
##
## Number of Fisher Scoring iterations: 4
모형 적합 결과를 출력하면 여러 가지 정보를 확인할 수 있습니다. Call은 분석가가 설정해준 로지스틱 회귀모형입니다. Deviance Residuals는 목표변수의 실제값과 추정값 간의 차이인 오차의 4분위수를 확인할 수 있습니다. 중앙값이 0에 가깝고 최소값과 최대값의 폭이 일정하면 정규분포를 따른다고 가정할 수 있는 것이죠.
Coefficients는 로지스틱 회귀모형의 입력변수별 회귀계수가 어떻게 적합되었는지 알 수 있습니다. Intercept(y절편)는 신경쓰지 않아도 되고, 다른 입력변수에 대한 회귀계수가 유의한지 확인하면 됩니다. 이 표의 오른쪽 끝에 출력되는 * 개수가 3개이면 유의확률이 0.01 이하인 것을 의미하며, 1개이면 유의확률이 0.05 이하인 것을 의미합니다. 즉, *가 1개 이상 출력되어야 회귀계수가 0이 아니라고 판단할 수 있습니다.
그런데 왜 입력변수가 5개일까요? 우리는 입력변수로 gre, gpa, 그리고 rank 이렇게 3개만 할당했는데, 로지스틱 회귀모형을 적합해보니 rank는 사라지고 대신에 rank2, rank3, rank4와 같은 새로운 변수들이 생겼습니다. 그 이유는, rank가 1~4의 값을 갖는 범주형 벡터이기 때문입니다. 범주형은 숫자가 아니므로 1~4의 값을 1 또는 0으로 표현해야 하는데, 그렇게 하기 위해 3개의 더미변수들이 필요했던 것입니다. 글로 설명하기 어려우니 표를 그려 설명하도록 하겠습니다.
| rank | rank2 | rank3 | rank4 |
|---|---|---|---|
| 1 | 0 | 0 | 0 |
| 2 | 1 | 0 | 0 |
| 3 | 0 | 1 | 0 |
| 4 | 0 | 0 | 1 |
위 표를 보면, rank가 1일 때 모든 더미변수들은 0을 갖습니다. 그리고 rank가 2일 때는 더미변수 rank2이 1이고 나머지 두 개의 더미변수들은 0을 갖습니다. 이런 식으로 rank가 3 또는 4일 때 rank3와 rank4가 각각 1이 되는 것이죠. 더미변수가 1의 값을 갖는다는 것은 rank가 1일 때와 그렇지 않을 때를 서로 비교하는 것으로 이해해야 합니다. 예를 들어, 3개의 더미변수가 모두 0이면 rank가 1인 경우를 의미한다고 했으므로, 더미변수 rank2의 회귀계수는 rank가 1일 때와 2일 때의 차이를 의미합니다. 나중에 회귀모형을 해석하는 부분에서 좀 더 자세히 다루도록 하겠습니다.
다음으로, 출력된 내용의 맨 아래에 있는 2개의 deviance에 주목합시다. (선형이든 로지스틱이든) 일단 회귀모형을 적합하고 나면 회귀모형의 유의성 검정을 가장 먼저 확인해야 합니다. 회귀모형의 유의성 검정은 이 회귀모형에 사용된 모든 회귀계수 중 어느 하나라도 0이 아닌 것인 있는지 확인하는 것인데 왜 이것을 가장 먼저 확인해야 하냐면, 만약 모든 회귀계수가 유의하지 않다면 0이라고 할 수 있고, 그것은 곧 회귀모형이 어떠한 설명력도 갖지 못한다는 의미가 되기 때문입니다.
로지스틱 회귀모형의 유의성 검정 방법에는, 앞에서 설명한 바와 같이 2가지가 있는데요. 첫 번째는 카이제곱 검정으로, 입력변수가 사용되지 않은 null 모형(M0)의 편차와 입력변수가 사용된 모형(Mp)의 편차 간 차이를 카이제곱 통계량으로 설정하여 검정하는 방법입니다. 이번 예제에서 적합한 로지스틱 회귀모형의 Null deviance는 499.98이고, Residual deviance가 458.52이며, 두 모형의 자유도는 각각 399, 394입니다. 이 값들의 차를 가지고 카이제곱 검정을 실시합니다.
# 로지스틱 회귀모형의 유의성 검정을 위해 두 편차의 차를 계산합니다.
devGap <- fitLR1$null.deviance - fitLR1$deviance
# 두 모형의 자유도 차를 계산합니다.
dfGap <- fitLR1$df.null - fitLR1$df.residual
# 위의 통계량으로 카이제곱 검정을 합니다. (단측검정)
pchisq(q = devGap, df = dfGap, lower.tail = FALSE)
## [1] 0.00000007578194
유의확률이 0.05보다 작으므로 두 모형이 서로 같다고 할 수 없습니다. 그러므로 최소한 1개 이상의 회귀계수가 0이 아니라고 할 수 있습니다.
로지스틱 회귀모형의 유의성을 검정하는 두 번째 방법은, 로그 가능도 비를 사용하는 것입니다. 이 방법을 사용하려면 입력변수를 사용하지 않은 회귀모형(M0)을 따로 적합해야 합니다.
# 먼저 독립변수가 하나도 사용되지 않는 null 모형을 적합합니다.
fitLR0 <- glm(formula = admit ~ 1,
data = univ,
family = binomial(link = logit))
# 필요 패키지를 불러옵니다.
library(lmtest)
# 두 모형의 가능도 비 검정을 합니다.
lrtest(fitLR0, fitLR1)
## Likelihood ratio test
##
## Model 1: admit ~ 1
## Model 2: admit ~ gre + gpa + rank
## #Df LogLik Df Chisq Pr(>Chisq)
## 1 1 -249.99
## 2 6 -229.26 5 41.459 0.00000007578 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
역시 유의확률이 0.05보다 작으므로 입력변수가 사용된 로지스틱 회귀모형이 유의하다고 판단합니다. lrtest() 함수 대신 waldtest() 함수로도 회귀모형의 유의성 검정을 실시할 수 있습니다. 아래와 같이 두 가지 방법을 사용할 수 있습니다.
# lmtest 패키지의 waldtest() 함수로 회귀모형의 유의성을 검정합니다.
# test 인자는 생략해도 무방합니다.
waldtest(object = fitLR1, test = c('F', 'Chisq'))
## Wald test
##
## Model 1: admit ~ gre + gpa + rank
## Model 2: admit ~ 1
## Res.Df Df F Pr(>F)
## 1 394
## 2 399 -5 7.2279 0.000001721 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
waldtest() 함수를 이용하면 특정 입력변수를 제외한 모형과 모두 포함한 모형 간 유의성 검증도 가능합니다. object2 인자에 제외할 입력변수를 지정하고 실행하면 됩니다.
# lmtest 패키지의 waldtest() 함수로 회귀모형의 유의성을 검정합니다
waldtest(object = fitLR1, object2 = c('gre', 'gpa'))
## Wald test
##
## Model 1: admit ~ gre + gpa + rank
## Model 2: admit ~ rank
## Res.Df Df F Pr(>F)
## 1 394
## 2 396 -2 7.6939 0.0005274 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
두 개의 입력변수(gre, gpa)를 제외한 모형과 포함한 모형 간 유의한 차이가 있음을 알 수 있습니다. 그런데 위와 같이 함수를 사용하여 회귀모형의 유의성을 검정하는 방법 대신, 두 모형의 로그 가능도를 각각 구한 다음 두 값의 차이를 가지고 카이제곱 검정을 실시할 수도 있습니다. 그러니까 맨 처음 소개한 방법과 비슷한 거죠.
# 두 모형의 로그 가능도를 각각 구해 차이를 계산합니다. (가능도 비)
LLR <- -2 * (logLik(object = fitLR0) - logLik(object = fitLR1))
# 카이제곱 검정을 실시합니다. (단측검정)
pchisq(q = LLR, df = dfGap, lower.tail = FALSE)
## 'log Lik.' 0.00000007578194 (df=1)
지금까지 로지스틱 회귀모형의 유의성 검정 결과 유의확률이 모두 똑같다는 것을 알 수 있습니다. 전체 회귀모형이 유의하다는 것을 알았으니 개별 회귀계수가 유의한지 확인해보겠습니다.[3]
회귀계수 유의성 검정 방법도 z-검정과 Wald 검정 2가지가 있다는 것을 앞에서 설명했습니다만, 여기에 회귀계수 신뢰구간을 확인하는 방법까지 추가하여 3가지를 소개하도록 하겠습니다.
첫 번째로, z-검정에 대해서 알아보겠습니다. 먼저 회귀모형을 적합한 결과 객체(fitLR1)에서 회귀계수와 표준오차 표를 추출합니다.
# 회귀모형 결과 객체에서 회귀계수와 표준오차 표를 추출합니다.
coefTbl <- as.data.frame(summary(fitLR1)$coefficients)
# 컬럼명을 변경합니다.
colnames(coefTbl) <- c('coef', 'se', 'z-stats', 'p-value')
# 회귀계수와 표준오차를 확인합니다.
coefTbl
## coef se z-stats p-value
## (Intercept) -3.989979073 1.139950936 -3.500132 0.0004650273
## gre 0.002264426 0.001093998 2.069864 0.0384651284
## gpa 0.804037549 0.331819298 2.423119 0.0153878974
## rank2 -0.675442928 0.316489661 -2.134171 0.0328288188
## rank3 -1.340203916 0.345306418 -3.881202 0.0001039415
## rank4 -1.551463677 0.417831633 -3.713131 0.0002047107
첫 번째 컬럼이 회귀계수, 두 번째 컬럼이 표준오차입니다. 각 입력변수마다 유의성 검정을 하려면 회귀계수(첫 번째 컬럼)를 표준오차(두 번째 컬럼)로 나눈 z-통계량을 구해야 합니다. z-통계량은 평균이 0, 표준편차가 1인 표준정규분포를 따릅니다. 따라서 z-통계량이 0이면, 표준정규분포의 확률밀도함수는 0.5를 반환합니다. z-통계량이 1.64보다 크면 누적확률이 0.95 이상이고, -1.64보다 작으면 누적확률이 0.05 미만임을 의미합니다.
# z-통계량을 계산하고 결과를 출력합니다.
zStat <- coefTbl$coef / coefTbl$se
print(zStat)
## [1] -3.500132 2.069864 2.423119 -2.134171 -3.881202 -3.713131
Intercept(y절편)을 포함한 6개 회귀계수 모두 1.64보다 크거나 -1.64보다 작습니다. 그렇다면 유의확률을 구해보겠습니다. 이 때, pnorm() 함수를 이용합니다. 이 함수는 정규분포의 누적확률을 반환하는 함수입니다. 예를 들어, pnorm() 함수의 x 인자에 0, mean 인자에 0, sd 인자에 1을 할당하고 함수를 실행하면 0.5가 반환됩니다. 평균이 0, 표준편차가 1인 표준정규분포에서 z-통계량이 0일 때 누적확률이 0.5라는 의미입니다.
# z-통계량의 누적확률을 확인합니다.
zProb <- pnorm(q = abs(x = zStat), mean = 0, sd = 1, lower.tail = TRUE)
print(zProb)
## [1] 0.9997675 0.9807674 0.9923061 0.9835856 0.9999480 0.9998976
숫자가 어지럽게 출력되었습니다만, 우리가 알아야 할 것은 1에서 누적확률을 뺀 값에 2를 곱한 것이 유의확률이라는 것입니다. 즉, z-통계량의 절대값을 구하고, 그 값에 대한 정규분포 누적확률을 산출한 다음 유의수준을 계산하기 위해 아래와 같이 처리합니다.
# z-검정 유의확률을 계산하고 소수점 둘째자리에서 반올림합니다.
round(x = (1 - zProb) * 2, digits = 2L)
## [1] 0.00 0.04 0.02 0.03 0.00 0.00
모든 회귀계수의 유의확률이 0.05보다 작습니다. 모든 회귀계수가 유의하다는 것이죠.
이번에는 Wald 검정을 해볼까요? Wald 검정 통계량은 회귀계수와 표준오차를 각각 제곱하여 나눈 값입니다. 이 통계량으로 카이제곱 검정을 하는 것이죠.
# 회귀계수와 표준오차를 각각 제곱한 뒤 나눈 Wald 통계량을 계산합니다.
wald2 <- (coefTbl$coef)^2 / (coefTbl$se)^2
# 카이제곱 검정을 하고, 유의확률을 소수점 둘째자리에서 반올림합니다.
round(x = pchisq(q = wald2, df = 1, lower.tail = FALSE), digits = 2L)
## [1] 0.00 0.04 0.02 0.03 0.00 0.00
Wald 검정 결과로도 모든 회귀계수가 유의하다는 것을 확인할 수 있었습니다.
회귀계수의 유의성 검정 방법으로 하나 더 추가하자면, 회귀계수의 신뢰구간(Confidence Intervals)을 확인함으로써 회귀계수가 0인지 아닌지 확인할 수 있습니다. 만약 회귀계수의 신뢰구간 양끝점(2.5%와 97.5%)의 부호가 서로 다르면 회귀계수의 신뢰구간이 0을 통과하므로 회귀계수가 0일 가능성이 있습니다. 회귀계수의 신뢰구간은 간단하게 confint() 함수로 확인할 수 있습니다.
# 회귀계수의 신뢰구간을 확인합니다.
confint(object = fitLR1)
## Waiting for profiling to be done...
## 2.5 % 97.5 %
## (Intercept) -6.2716202334 -1.792547080
## gre 0.0001375921 0.004435874
## gpa 0.1602959439 1.464142727
## rank2 -1.3008888002 -0.056745722
## rank3 -2.0276713127 -0.670372346
## rank4 -2.4000265384 -0.753542605
로지스틱 회귀모형을 적합하고 유의성 검증도 모두 마쳤으니 로지스틱 회귀모형의 결과를 해석하는 방법에 대해 살펴보겠습니다. 앞에서 오즈비에 대한 설명을 했었는데요. 일단 이번 예제에 사용된 입력변수들의 오즈비를 확인해보겠습니다.
# 모든 입력변수들의 오즈비를 확인합니다.
coef(object = fitLR1) %>% exp() %>% round(digits = 2L)
## (Intercept) gre gpa rank2 rank3 rank4
## 0.02 1.00 2.23 0.51 0.26 0.21
Intercept(y절편)은 의미가 없으므로 생략하고, gre부터 하나씩 살펴보겠습니다. gre의 오즈비는 1.00입니다. 이것은 무엇을 의미하는 것일까요? 바로 다른 모든 조건이 그대로일 때 gre가 1단위 증가할 때마다 불합격 확률(1-p) 대비 합격할 확률(p)의 비율이 1.00배라는 것을 의미합니다. gre가 추정값(확률)에 미치는 영향이 거의 없다는 것이죠. gre의 회귀계수를 봐도 알 수 있습니다. 결국 영어성적과 대학교 합격은 거의 무관한 것으로 보입니다.
gpa의 오즈비는 2.23입니다. 그러니까 다른 모든 조건이 그대로일 때 gpa가 1단위 증가할 때마다 불합격 확률(1-p) 대비 합격할 확률(p)의 비율이 2.23배라는 것이죠. 모든 입력변수들 중에 gpa의 오즈비가 가장 높습니다. 즉, gpa가 대학교 합격을 판가름짓는 가장 영향력 높은 입력변수라는 것입니다. (이번 모형으로만 판단하면) 미국 대학교에 입학하려면 학점에 가장 많은 신경을 써야 할 것 같습니다.
rank2, rank3, rank4는 범주형 벡터인 rank 대신에 새로 생긴 더미변수들임을 앞에서 설명한 바 있습니다. 이 세 개의 회귀계수들에 대해서 오즈비를 구하면 다음과 같습니다. rank2의 오즈비가 0.51이므로 rank가 1인 학생에 비해서 2인 학생의 합격할 확률이 절반에 불과하다는 것을 알 수 있습니다. rank3의 오즈비는 0.26이니까 rank가 1인 학생에 비해서 3인 학생의 합격할 확률이 약 1/4에 불과하다는 것 알 수 있겠죠? 그리고 rank가 4인 학생은 1/5로 더 떨어지는 것을 확인할 수 있습니다. 요약하자면 지원자의 출신 고등학교 등급이 낮을수록 합격할 확률도 낮아집니다.
우리는 앞에서 Wald 검정을 통해 회귀계수의 유의성 검정을 했었는데요. 더미변수 간 유의성 검정도 Wald 검정을 통해 확인할 수 있습니다. 다만 사용하는 함수가 다른데요. aod 패키지의 wald.test() 함수를 사용합니다. Sigma 인자에는 회귀계수의 분산-공분산 행렬을 할당하고, b 인자에는 회귀계수 벡터를 할당합니다. 마지막으로 Terms 인자에는 검증할 회귀계수를 지정합니다. 더미변수는 4~6번째에 있으므로 4:6을 입력하면 됩니다.
# 필요 패키지를 불러옵니다.
library(aod)
# wald.test() 함수를 이용하여 더미변수의 유의성 검정을 실시합니다.
wald.test(Sigma = vcov(object = fitLR1),
b = fitLR1$coefficients,
Terms = 4:6)
## Wald test:
## ----------
##
## Chi-squared test:
## X2 = 20.9, df = 3, P(> X2) = 0.00011
Wald 검정 결과, 유의확률(p-value)이 0.05보다 작으므로 더미변수 간 유의한 차이가 있음을 확인할 수 있습니다. 그럼 더미변수 간 회귀계수가 서로 같은지 아니면 다른지 확인은 어떻게 할 수 있을까요? 방금 사용한 wald.test() 함수에서 Terms 인자 대신에 L 인자를 사용하면 가능합니다. L 인자에는 비교하려는 회귀계수의 위치에 하나는 +1, 다른 하나는 -1, 나머지는 0으로 입력한 행벡터를 할당합니다. 함수를 실행하면, L과 b에 할당된 벡터의 행렬곱으로 검증하고자 하는 두 회귀계수의 차이를 통계량으로 하는 카이제곱 검정을 실시하게 됩니다.
# rank2와 rank3 간 회귀계수의 유의성 검정을 실시합니다.
wald.test(Sigma = vcov(object = fitLR1),
b = fitLR1$coefficients,
L = cbind(0, 0, 0, 1, -1, 0))
## Wald test:
## ----------
##
## Chi-squared test:
## X2 = 5.5, df = 1, P(> X2) = 0.019
이상으로 다양한 유의성 검증 방법에 대해서 소개해드렸습니다. 지금은 혼란스러울 수도 있겠지만, 여러 방법 중에서 가장 마음에 드는 걸 하나씩 골라서 사용하면 됩니다. 물론 모든 방법을 다 아는 것이 가장 좋겠습니다.
분류모형을 만들었으니 이제 모형의 분류 성능에 대해서 확인하도록 하겠습니다. 이항 로지스틱 회귀분석은 목표변수의 확률을 추정값으로 제공한다고 했습니다만, 그 확률을 가지고 실패냐 성공이냐로 Labeling 하는 기준점(cut-off)를 설정해야 합니다. 일반적으로 기준점을 0.5로 설정한다고 말씀드린 바 있습니다.
# 0.5를 cut-off로 하여 로지스틱 회귀모형의 추정값을 0과 1로 분류하고
# 범주형으로 변환합니다.
pred <- ifelse(test = fitLR1$fitted.values >= 0.5,
yes = 1,
no = 0) %>%
as.factor()
혼동행렬과 F1 점수로 분류 성능지표를 확인해보겠습니다.
# 필요 패키지를 불러옵니다.
library(caret)
# 혼동행렬을 확인합니다.
# positive 인자에 레벨을 지정할 수 있습니다.
confusionMatrix(data = pred,
reference = univ$admit,
positive = '1')
## Confusion Matrix and Statistics
##
## Reference
## Prediction 0 1
## 0 254 97
## 1 19 30
##
## Accuracy : 0.71
## 95% CI : (0.6628, 0.754)
## No Information Rate : 0.6825
## P-Value [Acc > NIR] : 0.1293
##
## Kappa : 0.1994
## Mcnemar's Test P-Value : 0.0000000000008724
##
## Sensitivity : 0.2362
## Specificity : 0.9304
## Pos Pred Value : 0.6122
## Neg Pred Value : 0.7236
## Prevalence : 0.3175
## Detection Rate : 0.0750
## Detection Prevalence : 0.1225
## Balanced Accuracy : 0.5833
##
## 'Positive' Class : 1
##
Positive가 1인 것을 확인하고 나서 차례로 민감도와 특이도 및 정밀도를 확인해보니 0.2362, 0.9304, 0.6122로 분류 성능이 상당히 나쁘게 나왔습니다. F1 점수도 마저 확인하겠습니다.
# 필요 패키지를 불러옵니다.
library(MLmetrics)
##
## Attaching package: 'MLmetrics'
## The following objects are masked from 'package:caret':
##
## MAE, RMSE
## The following object is masked from 'package:base':
##
## Recall
# F1 점수를 확인합니다.
F1_Score(y_true = univ$admit,
y_pred = pred,
positive = '1')
## [1] 0.3409091
F1 점수도 0.3409091로 상당히 낮습니다. 이런 일이 발생하는 이유는 분석하려는 데이터의 목표변수가 한 쪽으로 치우친 불균형 데이터이기 때문입니다. 확률값을 오름차순으로 정렬하여 산점도를 그려보면 육안으로 확인하기 쉬울 것입니다.
# 한글 폰트를 설정합니다.
par(family = 'NanumGothic')
# 로지스틱 회귀모형의 추정값(확률)을 오름차순으로 정렬한 뒤 산점도를 그립니다.
plot(x = fitLR1$fitted.values %>% sort(),
ylab = '추정확률 (fitted.value)',
main = '로지스틱 회귀모형의 추정값(확률)')
# 산점도 위에 기준점(cut-off)을 빨간 점선으로 추가합니다.
abline(h = 0.5, col = 'red', lty = 2)
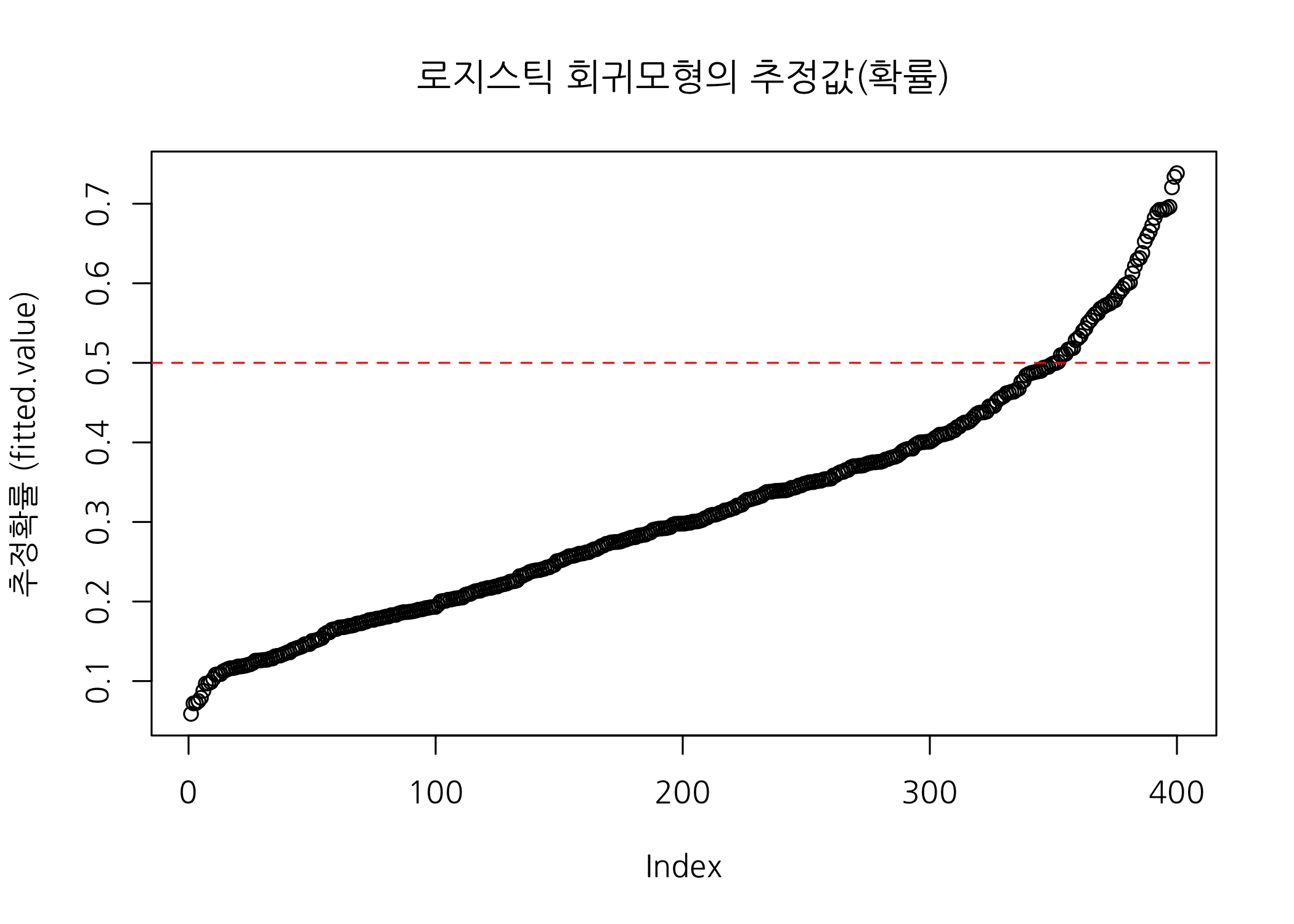
위 그림에서 알 수 있듯이, 목표변수에 0이 훨씬 많기 때문에 대부분의 추정값이 0.5보다 작게 산출되었고, 그렇다 보니 실제로 1인 학생들의 대부분이 0으로 분류되었습니다. 이 문제를 해결하려면 분류 기준점(cut-off)을 아래로 내려야 합니다.
그렇다면 기준점을 어느 수준까지 내리면 될까요? 비교적 손쉬운 방법을 먼저 해보겠습니다. 원래 데이터에서 목표변수의 범주별 비중을 확인하고, 합격한 학생의 비중으로 기준점을 낮춰서 예측 Labeling을 한 후 혼동행렬과 F1 점수를 확인하는 방법입니다.
# 목표변수의 범주별 비중을 확인합니다.
univ$admit %>% table() %>% prop.table()
## .
## 0 1
## 0.6825 0.3175
합격한 학생의 비중이 0.3175이므로 기준점을 이 값으로 변경합니다.
# cut-off를 변경하여 로지스틱 회귀모형의 추정값을 0과 1로 분류하고
# 범주형으로 변환합니다.
pred <- ifelse(test = fitLR1$fitted.values >= 0.3175,
yes = 1,
no = 0) %>%
as.factor()
그리고 나서 혼동행렬과 F1 점수로 분류 성능지표를 확인해보겠습니다.
# 혼동행렬을 확인합니다.
confusionMatrix(data = pred,
reference = univ$admit,
positive = '1')
## Confusion Matrix and Statistics
##
## Reference
## Prediction 0 1
## 0 174 46
## 1 99 81
##
## Accuracy : 0.6375
## 95% CI : (0.5883, 0.6847)
## No Information Rate : 0.6825
## P-Value [Acc > NIR] : 0.9756
##
## Kappa : 0.2475
## Mcnemar's Test P-Value : 0.00001572
##
## Sensitivity : 0.6378
## Specificity : 0.6374
## Pos Pred Value : 0.4500
## Neg Pred Value : 0.7909
## Prevalence : 0.3175
## Detection Rate : 0.2025
## Detection Prevalence : 0.4500
## Balanced Accuracy : 0.6376
##
## 'Positive' Class : 1
##
# F1 점수를 확인합니다.
F1_Score(y_true = univ$admit,
y_pred = pred,
positive = '1')
## [1] 0.5276873
기준점을 단순하게 0.5로 설정한 것에 비해서는 분류성능이 조금 향상되었습니다.
조금 복잡한 방법은 매튜의 상관계수 (Matthew Correlation Coefficient, MCC)를 사용하는 것입니다. 매튜의 상관계수는 이진 데이터의 분류 성능을 비교하는 척도로 사용되는데요. 일반적인 상관계수처럼 -1~+1의 값을 갖습니다. 실제값과 예측값이 완벽하게 같으면 +1, 서로 상관이 없으면 0, 그리고 완벽하게 다르면 -1이 되는 거죠. 매튜의 상관계수 공식은 아래와 같습니다.
위의 공식을 활용하여 MCC가 최대가 되는 분류 기준점을 탐색하는 방법을 소개하겠습니다. 분류 기준점을 0에서 시작하여 0.01 단위로 변경해가며 1까지 총 101번 실행하여 각 기준점에서의 MCC를 계산한 뒤, MCC가 최대가 되는 기준점을 찾는 방식입니다. 만약 MCC를 최대로 하는 기준점이 여러 개라면 최소값을 반환하도록 합니다. MCC는 mccr 패키지의 mccr() 함수를 사용하면 쉽게 계산할 수 있습니다.
# 기준점에 따라 매튜의 상관계수를 생성하는 함수를 만듭니다.
getMccDf <- function(object) {
# 실제값을 지정한 뒤 범주형으로 변환합니다.
real <- object$y %>% as.factor()
# 기준점을 0에서 1까지 0.01 단위로 증가하도록 설정합니다.
cutoffs <- seq(from = 0, to = 1, by = 0.01)
# 기준점과 매튜의 상관계수를 저장할 빈 객체를 생성합니다.
df <- data.frame()
# 매튜의 상관계수가 최대가 되는 기준점을 찾습니다.
for (cutoff in cutoffs) {
# 회귀모형의 추정값을 산출합니다.
pred <- ifelse(test = object$fitted.values >= cutoff,
yes = '1',
no = '0') %>%
factor(levels = c('0', '1'))
# 매튜의 상관계수를 계산합니다.
mcc <- mccr::mccr(act = real, pred = pred)
# MCC에 행 기준으로 추가합니다.
df <- rbind(df, data.frame(cutoff = cutoff, mcc = mcc))
}
# 최종 결과를 반환합니다.
return(df)
}
사용자 정의 함수를 생성하였으니 매튜의 상관계수 데이터 프레임을 만들고, 산점도를 그려서 매튜의 상관계수가 최대값일 때의 기준점을 확인해보겠습니다.
# 매튜의 상관계수 데이터 프레임을 생성합니다.
MCC <- getMccDf(object = fitLR1)
# 매튜의 상관계수 최대값을 지정합니다.
maxMCC <- max(MCC$mcc)
# 매튜의 상관계수가 최대값일 때 기준점을 지정합니다.
minCutoff <- MCC$cutoff[MCC$mcc == maxMCC]
# 산점도를 그립니다.
plot(x = MCC$cutoff,
y = MCC$mcc,
pch = 19,
col = 'gray30',
xlab = '기준점 (cut-off)',
ylab = '매튜의 상관계수 (mcc)',
main = '최적의 분류 기준점 찾기')
# 매튜의 상관계수 최대값을 기준으로 수평선과 수직선을 추가합니다.
abline(h = maxMCC,
v = minCutoff,
lty = 2,
col = 'red')
# 매튜의 상관계수가 최대값일 때 기준점을 출력합니다.
text(x = minCutoff,
y = min(MCC$mcc),
labels = str_c('cut-off=', minCutoff),
pos = 3)
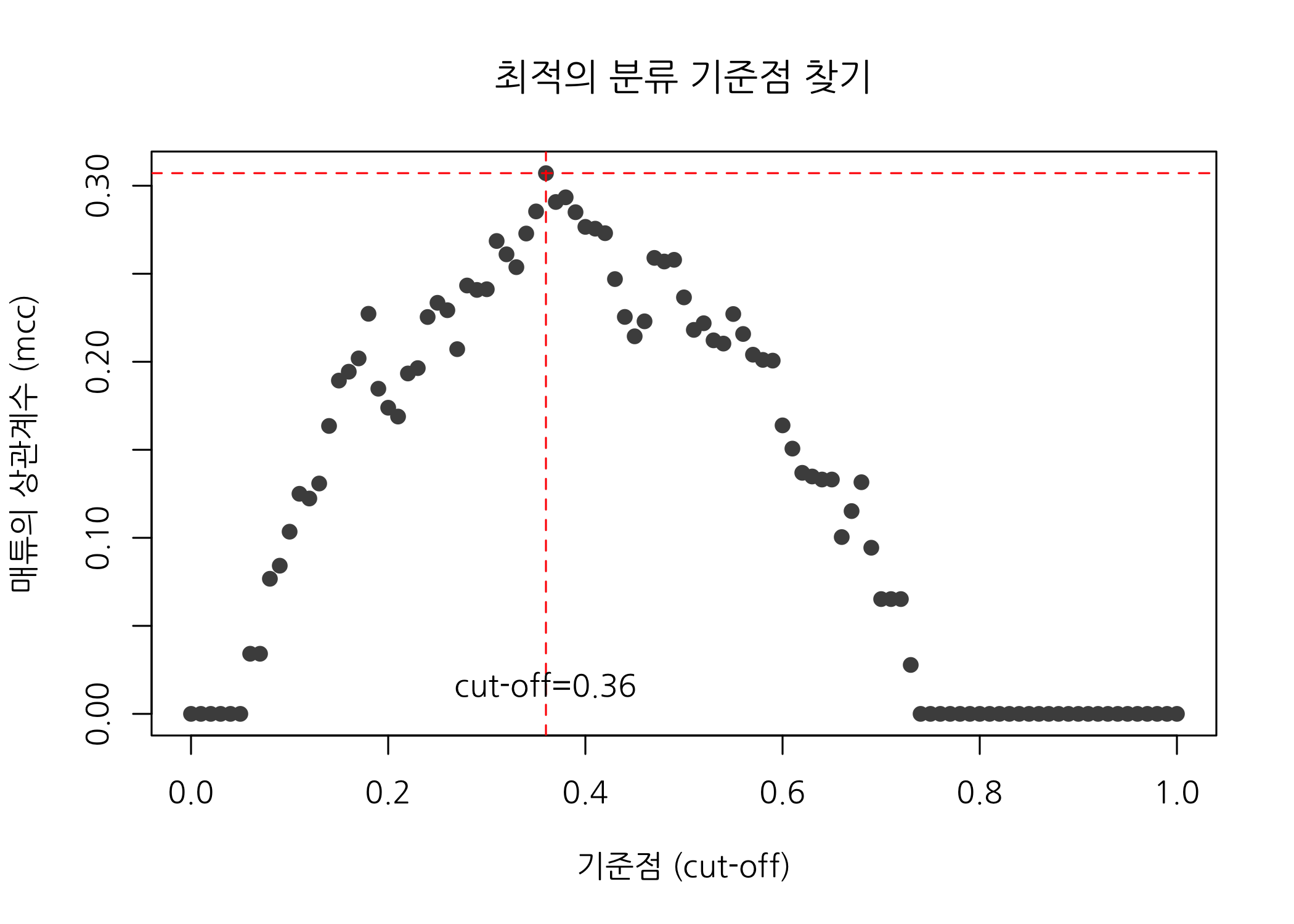
이제 거의 다 왔습니다. 매튜의 상관계수가 최대값일 때 기준점은 0.36입니다. 이 기준점을 기준으로 로지스틱 회귀모형의 예측값을 생성하고 혼동행렬과 F1 점수를 확인해보겠습니다.
# cut-off를 변경하여 로지스틱 회귀모형의 추정값을 0과 1로 분류하고
# 범주형으로 변환합니다.
pred <- ifelse(test = fitLR1$fitted.values >= 0.36,
yes = 1,
no = 0) %>%
as.factor()
# 혼동행렬을 확인합니다.
confusionMatrix(data = pred,
reference = univ$admit,
positive = '1')
## Confusion Matrix and Statistics
##
## Reference
## Prediction 0 1
## 0 206 56
## 1 67 71
##
## Accuracy : 0.6925
## 95% CI : (0.6447, 0.7374)
## No Information Rate : 0.6825
## P-Value [Acc > NIR] : 0.3556
##
## Kappa : 0.3065
## Mcnemar's Test P-Value : 0.3672
##
## Sensitivity : 0.5591
## Specificity : 0.7546
## Pos Pred Value : 0.5145
## Neg Pred Value : 0.7863
## Prevalence : 0.3175
## Detection Rate : 0.1775
## Detection Prevalence : 0.3450
## Balanced Accuracy : 0.6568
##
## 'Positive' Class : 1
##
# F1 점수를 확인합니다.
F1_Score(y_true = univ$admit,
y_pred = pred,
positive = '1')
## [1] 0.5358491
기준점을 0.3175로 설정했을 때보다 민감도는 조금 낮아졌지만(0.6378 -> 0.5591), 특이도(0.6374 -> 0.7546)와 정밀도(0.4500 -> 0.5145)에서 조금씩 향상되었습니다. F1 점수 역시 0.5276873에서 0.5358491로 소폭 증가하였습니다.
마무리는 ROC 커브를 그리고 AUROC를 계산하는 것으로 하겠습니다. 지난 분류모형2 포스팅에서 만들었던 checkROC() 사용자 정의 함수를 checkROC.R 파일로 저장해 두었는데, source() 함수를 이용하여 불러오도록 하겠습니다.[4]
# 사용자 정의 함수 checkROC()를 불러옵니다.
source(file = '../rcodes/checkROC.R')
# 로지스틱 회귀모형의 확률값을 입력하여 ROC 커브를 그리고 AUROC를 출력합니다.
checkROC(prob = fitLR1$fitted.values,
real = univ$admit,
title = 'ROC 커브 - 이항 로지스틱 회귀모형')
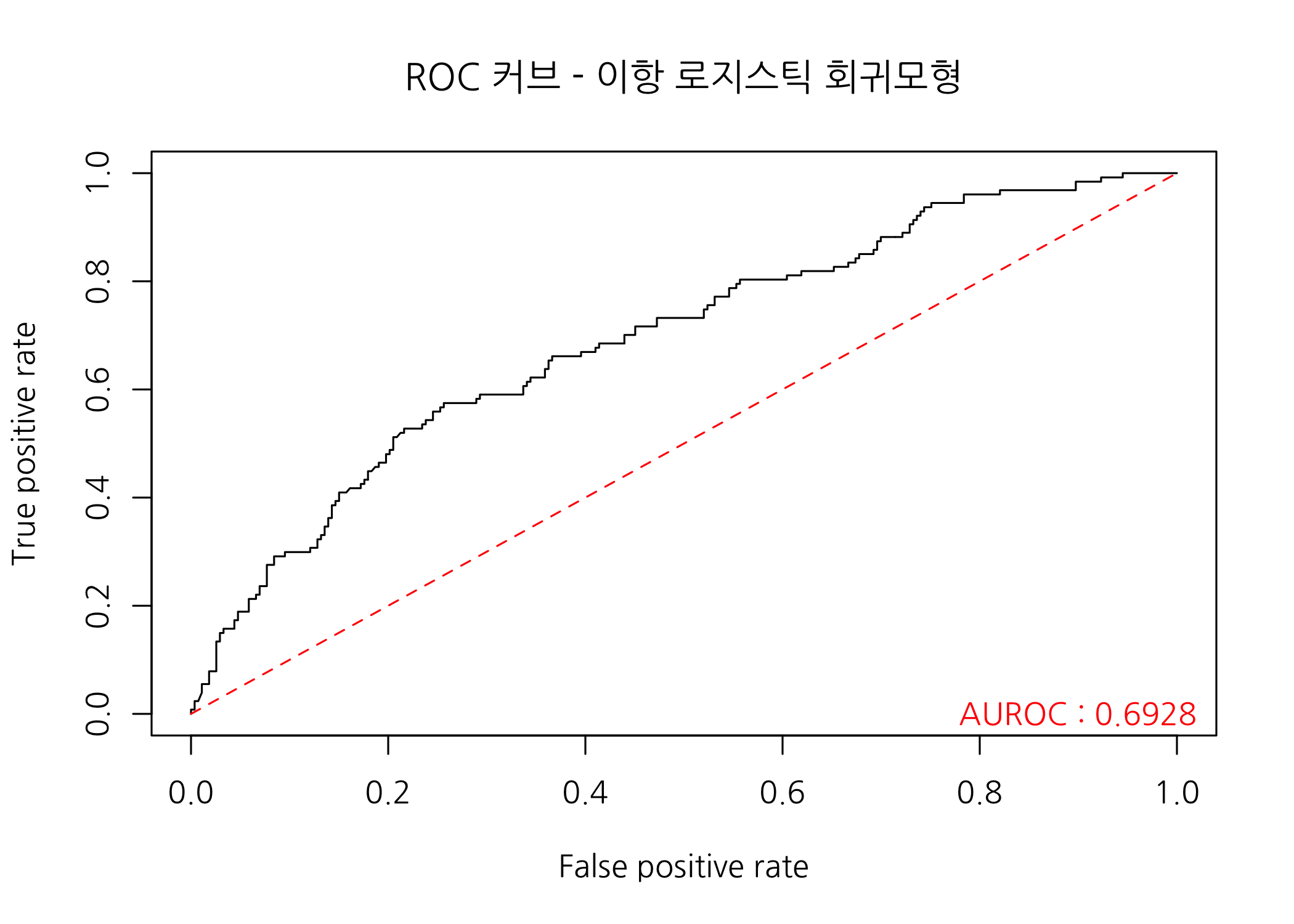
AUROC가 0.6928에 불과합니다. 로지스틱 회귀모형의 분류 성능이 상당히 낮습니다. 데이터의 문제가 되겠지만, 다른 분류 알고리즘을 사용한 모형과 분류 성능을 비교해보면 재미있을 것 같습니다. 도전해보시죠!
[1] 목표변수의 범주별 비중이 크게 차이나는 불균형(Imbalanced) 데이터셋에 대해서 cut-off를 0.5로 지정하는 것은 적당하지 않을 수 있습니다.
[2] 출처 : https://www.graphpad.com/support/faqid/1465/
[3] 사실 회귀계수의 유의성 검정은 따로 하지 않아도 됩니다. 우리가 로지스틱 회귀모형을 적합한 후 summary() 함수로 모형 적합 결과를 확인할 때 Coefficients에서 모든 회귀계수가 유의하다는 것을 이미 확인한 바 있기 때문입니다. 하지만 여러 가지를 배워서 나쁠 건 없겠죠?
[4] 여러분도 적당한 위치에 R파일로 저장해놓고 필요할 때마다 불러서 사용하기 바랍니다.