탐색적 데이터 분석 (EDA)
이 글은 2018~2019년에 작성한 R 기반 강의 노트를 옮긴 것입니다. 코드 일부는 현재 패키지 버전과 다를 수 있습니다.
일반적으로 데이터 분석 모델링에 앞서 탐색적 데이터 분석(Explorative Data Analysis)을 수행합니다. 이 과정에서 분석하려는 데이터를 다각도로 살펴봄으로써 데이터와 좀 더 친해질 수 있습니다. 아울러 간단한 인사이트도 얻을 수 있습니다.
EDA에는 정해진 과정이 없다고 합니다만, 저는 주로 관심 있는 데이터에 대해 그래프를 그려봄으로써 데이터가 어떤 형태를 띄고 있는지 살펴봅니다. 이번에는 2017년도 프로야구 타자 스탯을 가지고 간단하고 재미있는 EDA를 소개해드리고자 합니다.[1]
맨 처음 해야 할 일은 분석할 xlsx 데이터를 read_excel() 함수로 읽은 후 hitters 객체에 저장하는 것입니다. 이전 포스팅에서 설명드린 바와 같이 read_excel() 함수를 실행하면 티블 타입의 객체를 반환합니다. 티블은 데이터프레임의 단점을 보완하기 위해 최근에 도입된 객체 타입인데요. 티블이 가진 몇 가지 장점 중 하나는 print(object) 함수를 실행했을 때, 전체 데이터를 보여주는 대신 head(x = object, n = 10L) 함수를 실행한 것처럼 처음 10 행만 보여줍니다. 이러한 점이 편리하기도 하지만 저로서는 전체 데이터를 보는 것이 더 익숙해서 그런지 생각보다 불편했습니다. 이를 보완하려면 아래와 같이 옵션을 추가해주면 됩니다.
# 티블 객체를 출력할 때 보여주는 행의 개수를 설정할 수 있습니다.
# 전체 행을 다 보고 싶으면 아래와 같이 설정합니다.
options(tibble.print_max = Inf)
# 최소 20 행, 최대 50행까지 출력하기를 원하면 아래와 같이 설정합니다.
options(tibble.print_max = 50, tibble.print_min = 20)
# 필요 패키지를 불러옵니다.
library(readxl)
# xlsx 파일을 읽어, dataXls에 할당합니다.
hitters <- read_excel(path = './data/2017_Baseball_hitter_stat.xlsx', sheet = NULL)
프로야구 타자 스탯을 활용한 EDA
이제 일련의 과정을 거쳐 hitters 데이터를 다각도로 살펴봄으로써 이 데이터가 담고 있는 인사이트를 확인해보도록 하겠습니다.
- 전체 데이터의 구조와 각 열(컬럼)별 형태 및 요약 통계량을 살펴봅니다.
- 필요한 경우, stringr 패키지의 함수들을 이용하여 텍스트 데이터를 수정합니다.
- 분석가가 원하는 파생변수도 생성합니다.
- 산점도, 상자수염그림, 히스토그램 등 다양한 그래프를 그려봅니다.
데이터 구조 파악하기
데이터의 구조를 파악하는데 필요한 함수 몇 가지를 소개해드립니다.
- str() : 객체의 구조를 출력합니다. 데이터프레임의 경우, 컬럼명과 속성 등을 출력합니다.
- head() :
n인자에 숫자를 할당하면, 데이터의 처음 n줄을 출력합니다. - tail() :
n인자에 숫자를 할당하면, 데이터의 마지막 n줄을 출력합니다. - dim() : 객체의 차원을 출력합니다. 데이터프레임의 경우, 행과 열의 수를 각각 출력합니다.
- nrow() : 데이터프레임의 행의 수를 출력합니다.
- ncol() : 데이터프레임의 열의 수를 출력합니다.
# 데이터프레임의 전체적인 구조(structure)를 확인합니다.
str(object = hitters)
## Classes 'tbl_df', 'tbl' and 'data.frame': 292 obs. of 20 variables:
## $ 순위 : num 1 2 3 4 5 6 7 8 9 10 ...
## $ 선수명: chr "최정" "김재환*" "최형우" "박건우" ...
## $ 팀명 : chr "SK" "두산" "KIA" "두산" ...
## $ 경기 : num 130 144 142 131 119 125 144 137 139 106 ...
## $ 타석 : num 527 636 629 543 510 561 667 529 621 452 ...
## $ 타수 : num 430 544 514 483 445 498 576 476 557 388 ...
## $ 안타 : num 136 185 176 177 151 173 193 176 178 141 ...
## $ 홈런 : num 46 35 26 20 37 24 20 5 27 3 ...
## $ 득점 : num 89 110 98 91 100 103 113 84 118 84 ...
## $ 타점 : num 113 115 120 78 111 99 80 64 111 47 ...
## $ 볼넷 : num 70 81 96 41 50 48 83 39 41 46 ...
## $ 삼진 : num 107 123 82 64 61 116 96 40 112 51 ...
## $ 도루 : num 1 4 0 20 10 17 25 4 32 11 ...
## $ BABIP : num 0.316 0.385 0.362 0.39 0.324 0.413 0.374 0.393 0.354 0.408 ...
## $ 타율 : num 0.316 0.34 0.342 0.366 0.339 0.347 0.335 0.37 0.32 0.363 ...
## $ 출루율: num 0.427 0.429 0.45 0.424 0.414 0.415 0.42 0.42 0.373 0.441 ...
## $ 장타율: num 0.684 0.603 0.576 0.582 0.661 0.584 0.514 0.477 0.54 0.472 ...
## $ OPS : num 1.11 1.03 1.03 1.01 1.07 ...
## $ wOBA : num 0.442 0.427 0.43 0.424 0.436 0.416 0.398 0.391 0.38 0.404 ...
## $ WAR : num 7.3 7.22 7.2 7.04 5.75 5.64 5.6 5.19 5.01 4.92 ...
# 처음 5줄을 확인합니다.
head(x = hitters, n = 5L)
## # A tibble: 5 x 20
## 순위 선수명 팀명 경기 타석 타수 안타 홈런 득점 타점 볼넷 삼진
## <dbl> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1. 최정 SK 130. 527. 430. 136. 46. 89. 113. 70. 107.
## 2 2. 김재환*… 두산 144. 636. 544. 185. 35. 110. 115. 81. 123.
## 3 3. 최형우 KIA 142. 629. 514. 176. 26. 98. 120. 96. 82.
## 4 4. 박건우 두산 131. 543. 483. 177. 20. 91. 78. 41. 64.
## 5 5. 로사리오… 한화 119. 510. 445. 151. 37. 100. 111. 50. 61.
## # ... with 8 more variables: 도루 <dbl>, BABIP <dbl>, 타율 <dbl>,
## # 출루율 <dbl>, 장타율 <dbl>, OPS <dbl>, wOBA <dbl>, WAR <dbl>
# 마지막 5줄을 확인합니다.
tail(x = hitters, n = 5L)
## # A tibble: 5 x 20
## 순위 선수명 팀명 경기 타석 타수 안타 홈런 득점 타점 볼넷 삼진
## <dbl> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 288. 홍재호 KIA 2. 0. 0. 0. 0. 0. 0. 0. 0.
## 2 289. 황경태 두산 2. 0. 0. 0. 0. 0. 0. 0. 0.
## 3 290. 김찬형 NC 2. 0. 0. 0. 0. 0. 0. 0. 0.
## 4 291. 강동관 롯데 1. 0. 0. 0. 0. 0. 0. 0. 0.
## 5 292. 이동현(타… LG 1. 0. 0. 0. 0. 0. 0. 0. 0.
## # ... with 8 more variables: 도루 <dbl>, BABIP <dbl>, 타율 <dbl>,
## # 출루율 <dbl>, 장타율 <dbl>, OPS <dbl>, wOBA <dbl>, WAR <dbl>
# 행과 열의 수를 확인합니다.
dim(x = hitters)
## [1] 292 20
# 행의 수를 확인합니다.
nrow(x = hitters)
## [1] 292
# 열의 수를 확인합니다.
ncol(x = hitters)
## [1] 20
이번에는 행 이름과 열 이름을 확인하고 변경하는 방법을 소개하겠습니다. 역시 관련 함수를 먼저 정리해보았습니다.
- rownames() : 행 이름을 벡터 형태로 출력합니다. 할당 연산자(
<-) 우측에 행과 같은 길이를 갖는 벡터를 지정하면 해당 벡터로 행 이름을 변경할 수 있습니다. - colnames() : 열 이름을 벡터 형태로 출력합니다. 할당 연산자(
<-) 우측에 열과 같은 길이를 갖는 벡터를 지정하면 해당 벡터로 열 이름을 변경할 수 있습니다. - dimnames() : 행과 열 이름을 리스트 형태로 출력합니다. 할당 연산자(
<-) 우측에 행과 열 이름 벡터를 순서대로 리스트 형태로 지정하면 행과 열 이름을 한 번에 변경할 수 있습니다.
이번 포스팅에서는 행과 열 이름을 각각 확인하는 것만 소개하도록 하겠습니다.
# 행 이름을 확인합니다.
rownames(x = hitters)
## [1] "1" "2" "3" "4" "5" "6" "7" "8" "9" "10" "11"
## [12] "12" "13" "14" "15" "16" "17" "18" "19" "20" "21" "22"
## [23] "23" "24" "25" "26" "27" "28" "29" "30" "31" "32" "33"
## [34] "34" "35" "36" "37" "38" "39" "40" "41" "42" "43" "44"
## [45] "45" "46" "47" "48" "49" "50" "51" "52" "53" "54" "55"
## [56] "56" "57" "58" "59" "60" "61" "62" "63" "64" "65" "66"
## [67] "67" "68" "69" "70" "71" "72" "73" "74" "75" "76" "77"
## [78] "78" "79" "80" "81" "82" "83" "84" "85" "86" "87" "88"
## [89] "89" "90" "91" "92" "93" "94" "95" "96" "97" "98" "99"
## [100] "100" "101" "102" "103" "104" "105" "106" "107" "108" "109" "110"
## [111] "111" "112" "113" "114" "115" "116" "117" "118" "119" "120" "121"
## [122] "122" "123" "124" "125" "126" "127" "128" "129" "130" "131" "132"
## [133] "133" "134" "135" "136" "137" "138" "139" "140" "141" "142" "143"
## [144] "144" "145" "146" "147" "148" "149" "150" "151" "152" "153" "154"
## [155] "155" "156" "157" "158" "159" "160" "161" "162" "163" "164" "165"
## [166] "166" "167" "168" "169" "170" "171" "172" "173" "174" "175" "176"
## [177] "177" "178" "179" "180" "181" "182" "183" "184" "185" "186" "187"
## [188] "188" "189" "190" "191" "192" "193" "194" "195" "196" "197" "198"
## [199] "199" "200" "201" "202" "203" "204" "205" "206" "207" "208" "209"
## [210] "210" "211" "212" "213" "214" "215" "216" "217" "218" "219" "220"
## [221] "221" "222" "223" "224" "225" "226" "227" "228" "229" "230" "231"
## [232] "232" "233" "234" "235" "236" "237" "238" "239" "240" "241" "242"
## [243] "243" "244" "245" "246" "247" "248" "249" "250" "251" "252" "253"
## [254] "254" "255" "256" "257" "258" "259" "260" "261" "262" "263" "264"
## [265] "265" "266" "267" "268" "269" "270" "271" "272" "273" "274" "275"
## [276] "276" "277" "278" "279" "280" "281" "282" "283" "284" "285" "286"
## [287] "287" "288" "289" "290" "291" "292"
# 열 이름을 확인합니다.
colnames(x = hitters)
## [1] "순위" "선수명" "팀명" "경기" "타석" "타수" "안타"
## [8] "홈런" "득점" "타점" "볼넷" "삼진" "도루" "BABIP"
## [15] "타율" "출루율" "장타율" "OPS" "wOBA" "WAR"
# 행과 열 이름을 순서대로 확인합니다.
dimnames(x = hitters)
## [[1]]
## [1] "1" "2" "3" "4" "5" "6" "7" "8" "9" "10" "11"
## [12] "12" "13" "14" "15" "16" "17" "18" "19" "20" "21" "22"
## [23] "23" "24" "25" "26" "27" "28" "29" "30" "31" "32" "33"
## [34] "34" "35" "36" "37" "38" "39" "40" "41" "42" "43" "44"
## [45] "45" "46" "47" "48" "49" "50" "51" "52" "53" "54" "55"
## [56] "56" "57" "58" "59" "60" "61" "62" "63" "64" "65" "66"
## [67] "67" "68" "69" "70" "71" "72" "73" "74" "75" "76" "77"
## [78] "78" "79" "80" "81" "82" "83" "84" "85" "86" "87" "88"
## [89] "89" "90" "91" "92" "93" "94" "95" "96" "97" "98" "99"
## [100] "100" "101" "102" "103" "104" "105" "106" "107" "108" "109" "110"
## [111] "111" "112" "113" "114" "115" "116" "117" "118" "119" "120" "121"
## [122] "122" "123" "124" "125" "126" "127" "128" "129" "130" "131" "132"
## [133] "133" "134" "135" "136" "137" "138" "139" "140" "141" "142" "143"
## [144] "144" "145" "146" "147" "148" "149" "150" "151" "152" "153" "154"
## [155] "155" "156" "157" "158" "159" "160" "161" "162" "163" "164" "165"
## [166] "166" "167" "168" "169" "170" "171" "172" "173" "174" "175" "176"
## [177] "177" "178" "179" "180" "181" "182" "183" "184" "185" "186" "187"
## [188] "188" "189" "190" "191" "192" "193" "194" "195" "196" "197" "198"
## [199] "199" "200" "201" "202" "203" "204" "205" "206" "207" "208" "209"
## [210] "210" "211" "212" "213" "214" "215" "216" "217" "218" "219" "220"
## [221] "221" "222" "223" "224" "225" "226" "227" "228" "229" "230" "231"
## [232] "232" "233" "234" "235" "236" "237" "238" "239" "240" "241" "242"
## [243] "243" "244" "245" "246" "247" "248" "249" "250" "251" "252" "253"
## [254] "254" "255" "256" "257" "258" "259" "260" "261" "262" "263" "264"
## [265] "265" "266" "267" "268" "269" "270" "271" "272" "273" "274" "275"
## [276] "276" "277" "278" "279" "280" "281" "282" "283" "284" "285" "286"
## [287] "287" "288" "289" "290" "291" "292"
##
## [[2]]
## [1] "순위" "선수명" "팀명" "경기" "타석" "타수" "안타"
## [8] "홈런" "득점" "타점" "볼넷" "삼진" "도루" "BABIP"
## [15] "타율" "출루율" "장타율" "OPS" "wOBA" "WAR"
이제 각 열(컬럼) 벡터의 속성과 기초 통계량을 확인해보겠습니다. 지난 포스팅에서 summary() 함수를 소개했는데요. 이 함수를 이용하면 숫자형 벡터는 최소값, 1분위수, 중앙값, 평균, 3분위수, 최대값을 출력해주고, 문자형 벡터는 전체 길이와 속성(Class, Mode)를 출력합니다. 아울러 범주형 벡터는 빈도수 높은 레벨을 내림차순 정렬하여 상위 6개만 출력합니다.
# 불필요한 열(순위)을 삭제합니다.
hitters <- hitters[, -1]
# 팀명을 범주형 벡터로 변환합니다.
hitters$팀명 <- as.factor(hitters$팀명)
# 각 열별 요약 통계량을 출력합니다.
summary(object = hitters)
## 선수명 팀명 경기 타석
## Length:292 한화 : 34 Min. : 1.0 Min. : 0.00
## Class :character LG : 32 1st Qu.: 14.0 1st Qu.: 19.75
## Mode :character KIA : 31 Median : 59.5 Median :117.00
## NC : 31 Mean : 62.9 Mean :194.80
## 삼성 : 31 3rd Qu.:110.2 3rd Qu.:366.00
## 넥센 : 29 Max. :144.0 Max. :667.00
## (Other):104
## 타수 안타 홈런 득점
## Min. : 0.0 Min. : 0.00 Min. : 0.000 Min. : 0.00
## 1st Qu.: 17.0 1st Qu.: 3.00 1st Qu.: 0.000 1st Qu.: 2.00
## Median :105.0 Median : 25.50 Median : 1.000 Median : 15.50
## Mean :172.4 Mean : 49.30 Mean : 5.298 Mean : 26.31
## 3rd Qu.:320.2 3rd Qu.: 86.25 3rd Qu.: 7.000 3rd Qu.: 43.00
## Max. :576.0 Max. :193.00 Max. :46.000 Max. :118.00
##
## 타점 볼넷 삼진 도루
## Min. : 0.0 Min. : 0.00 Min. : 0.00 Min. : 0.000
## 1st Qu.: 1.0 1st Qu.: 1.00 1st Qu.: 6.00 1st Qu.: 0.000
## Median : 11.0 Median : 8.00 Median : 23.50 Median : 1.000
## Mean : 24.9 Mean :15.49 Mean : 34.27 Mean : 2.658
## 3rd Qu.: 40.5 3rd Qu.:23.00 3rd Qu.: 57.00 3rd Qu.: 3.000
## Max. :124.0 Max. :96.00 Max. :138.00 Max. :40.000
##
## BABIP 타율 출루율 장타율
## Min. :0.0000 Min. :0.0000 Min. :0.0000 Min. :0.0000
## 1st Qu.:0.2640 1st Qu.:0.1975 1st Qu.:0.2500 1st Qu.:0.2615
## Median :0.3140 Median :0.2590 Median :0.3280 Median :0.3660
## Mean :0.2951 Mean :0.2372 Mean :0.2976 Mean :0.3421
## 3rd Qu.:0.3510 3rd Qu.:0.2995 3rd Qu.:0.3650 3rd Qu.:0.4450
## Max. :1.0000 Max. :1.0000 Max. :1.0000 Max. :1.0000
## NA's :11 NA's :5 NA's :5 NA's :5
## OPS wOBA WAR
## Min. :0.0000 Min. :0.0000 Min. :-1.3200
## 1st Qu.:0.5200 1st Qu.:0.2345 1st Qu.:-0.1900
## Median :0.6860 Median :0.3050 Median : 0.0000
## Mean :0.6398 Mean :0.2815 Mean : 0.6235
## 3rd Qu.:0.8020 3rd Qu.:0.3490 3rd Qu.: 0.8500
## Max. :2.0000 Max. :0.8980 Max. : 7.3000
## NA's :5 NA's :5 NA's :5
선수명은 문자형 벡터라 전체 길이(292)와 Class 및 Mode를 출력하였습니다. 팀명은 범주형 벡터라 빈도수가 높은 팀을 내림차순하여 상위 6개 팀만 출력하였습니다. 나머지 열은 모두 숫자형 벡터라 6가지 요약 통계량을 각각 출력하였습니다.
텍스트 처리하기[2]
선수명에 공백이 있는지 확인하고, 공백이 있으면 제거하겠습니다.
# 선수명에 공백이 있는지 확인합니다.
hitters$선수명 %>% str_subset(pattern = ' ')
## character(0)
선수명에 공백이 없음을 확인하였습니다. 만약 선수명에 공백이 있었다면 아래 코드로 공백을 제거할 수 있습니다.
# 선수명에 공백을 제거합니다.
hitters$선수명 <- hitters$선수명 %>%
str_replace_all(pattern = ' ', replacement = '')
새로운 열(컬럼) 추가하기
이번에는 특정 팀의 선수들 명단을 확인해보도록 하겠습니다. 자신이 응원하는 팀으로 지정해보기 바랍니다.
# 특정 팀에 속한 선수명을 출력합니다.
hitters[hitters$팀명 == 'KIA', '선수명']
## # A tibble: 31 x 1
## 선수명
## <chr>
## 1 최형우
## 2 김선빈
## 3 버나디나
## 4 안치홍
## 5 나지완
## 6 이범호
## 7 김주찬
## 8 이명기
## 9 최원준
## 10 서동욱
## 11 김호령
## 12 이홍구
## 13 노관현
## 14 이진영
## 15 유재신
## 16 최정민
## 17 이정훈
## 18 김지성
## 19 박진태(타)
## 20 최병연
## 21 오준혁
## 22 노수광
## 23 이인행
## 24 백용환
## 25 이호신
## 26 한승택
## 27 고장혁
## 28 신종길
## 29 김민식
## 30 김주형
## 31 홍재호
이 중에서 관심 있는 선수들만 골라서 관심선수라는 새로운 열(컬럼)을 생성합니다.
# 관심선수 명단을 벡터에 할당합니다.
관심선수 <- c('이명기', '김주찬', '버나디나', '최형우', '나지완', '안치홍', '이범호', '김민식', '김선빈')
# 관심선수인 경우 '1', 아니면 '0'을 갖는 새로운 열(컬럼)을 생성합니다.
hitters$관심선수 <- ifelse(test = hitters$선수명 %in% 관심선수, yes = '1', no = '0')
# 관심선수의 스탯만 출력합니다.
hitters[hitters$관심선수 == '1', ]
## # A tibble: 10 x 20
## 선수명 팀명 경기 타석 타수 안타 홈런 득점 타점 볼넷 삼진
## <chr> <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 최형우 KIA 142. 629. 514. 176. 26. 98. 120. 96. 82.
## 2 김선빈 KIA 137. 529. 476. 176. 5. 84. 64. 39. 40.
## 3 버나디나 KIA 139. 621. 557. 178. 27. 118. 111. 41. 112.
## 4 안치홍 KIA 132. 545. 487. 154. 21. 95. 93. 43. 70.
## 5 나지완 KIA 137. 551. 459. 138. 27. 85. 94. 62. 105.
## 6 이범호 KIA 115. 447. 382. 104. 25. 57. 89. 52. 81.
## 7 김주찬 KIA 122. 478. 440. 136. 12. 78. 70. 31. 59.
## 8 이명기 KIA 115. 512. 464. 154. 9. 79. 63. 28. 57.
## 9 김민식 SK 2. 1. 1. 0. 0. 0. 0. 0. 0.
## 10 김민식 KIA 135. 391. 351. 78. 4. 39. 40. 26. 55.
## # ... with 9 more variables: 도루 <dbl>, BABIP <dbl>, 타율 <dbl>,
## # 출루율 <dbl>, 장타율 <dbl>, OPS <dbl>, wOBA <dbl>, WAR <dbl>,
## # 관심선수 <chr>
산점도 그려보기
어느 정도 데이터 전처리가 마무리 되었으니 이제 산점도를 그려보겠습니다. 산점도를 활용하면 분석 대상인 데이터의 컬럼의 수가 p인 즉, p차원 데이터에서 2개를 선별하여 2차원 평면에 그려봄으로써 데이터가 어떻게 분포하는지 확인할 수 있습니다.
# 한글이 깨지지 않도록 설정합니다.
par(family = 'NanumGothic')
# 타수와 타율을 기준으로 산점도를 그려봅니다.
plot(x = hitters$타수,
y = hitters$타율,
main = '타수와 타율 간 관계',
xlab = '타수',
ylab = '타율',
family = 'NanumGothic')
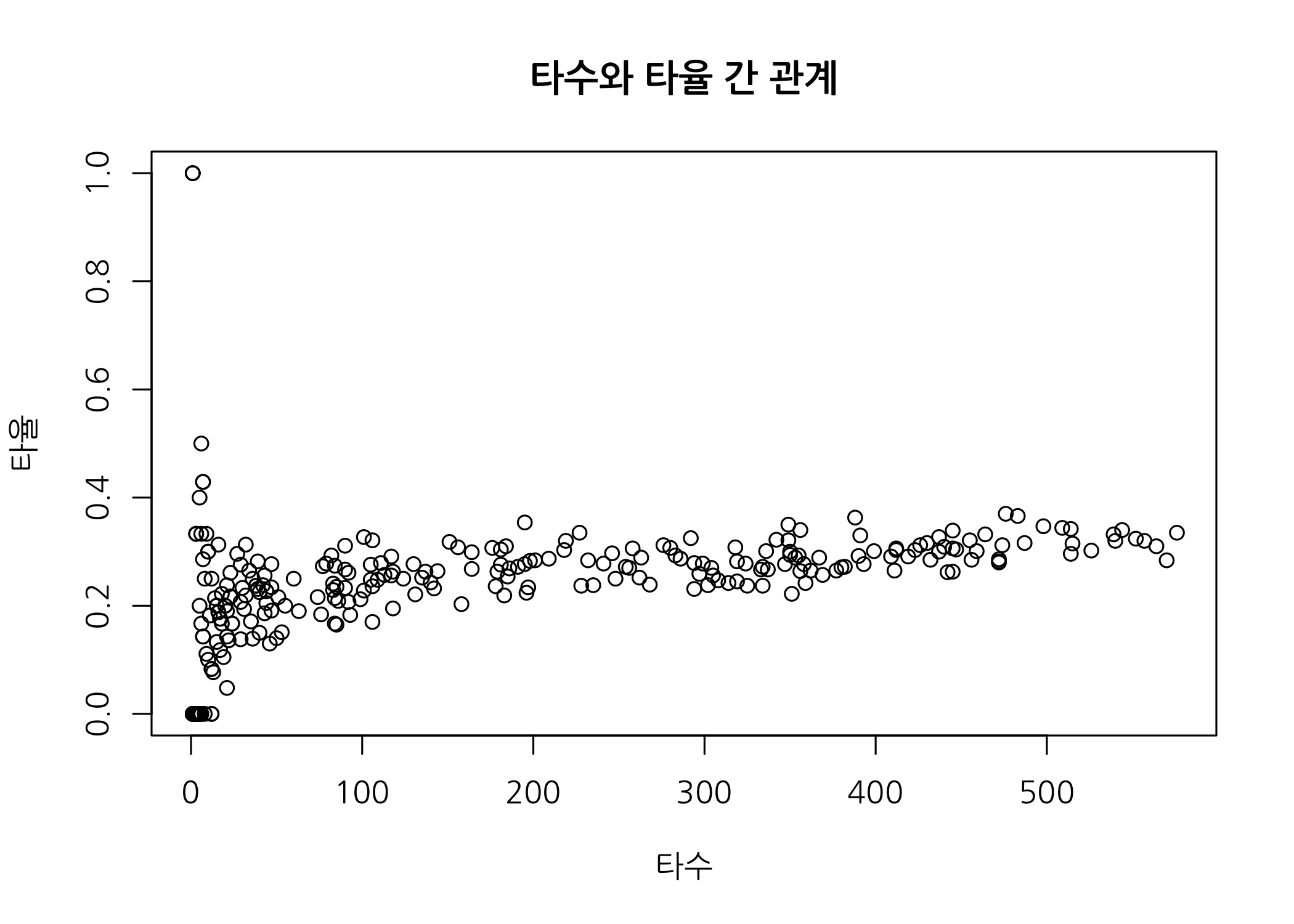
타수가 적은 선수들 중 일부가 비정상적으로 높은 타율을 보이므로 분석 대상에서 제외하는 것이 좋습니다. 타수로 도수분포표를 만든 후 일부 데이터를 삭제하도록 하겠습니다.
# 타수의 빈도를 확인합니다.
table(hitters$타수)
##
## 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
## 5 10 9 4 9 3 5 5 2 2 3 1 5 1 1 3 3 3
## 18 19 20 21 22 23 24 27 29 30 31 32 34 35 36 38 39 40
## 2 1 2 4 1 3 2 1 3 1 1 2 1 1 2 2 2 2
## 42 43 44 46 47 50 51 53 55 60 63 74 76 77 79 82 83 84
## 1 2 3 1 3 1 1 1 1 1 1 1 1 1 1 1 2 3
## 85 86 90 92 93 99 101 105 106 109 111 113 117 118 124 130 131 135
## 2 1 3 2 1 1 2 2 3 1 1 1 2 2 1 1 1 1
## 137 140 142 144 151 156 158 164 176 178 179 181 183 184 185 186 191 195
## 1 1 1 1 1 1 1 2 1 1 1 2 1 1 1 1 1 2
## 196 197 198 201 209 218 219 227 228 232 235 241 246 248 254 256 258 262
## 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
## 263 268 276 280 283 286 292 294 297 299 302 304 305 308 314 318 319 324
## 1 1 1 1 1 1 1 2 1 1 1 1 1 1 1 1 2 1
## 325 333 334 336 337 342 347 349 350 351 353 355 356 358 359 362 367 369
## 1 1 2 1 1 1 1 2 2 1 1 1 2 1 1 1 1 1
## 377 380 382 388 390 391 393 399 409 411 412 419 423 426 430 432 437 440
## 1 1 1 1 1 1 1 1 1 1 2 1 1 1 1 1 2 1
## 442 445 447 455 456 459 464 472 474 476 483 487 498 509 514 515 526 539
## 1 3 1 1 1 1 1 3 1 1 1 1 1 1 2 1 1 1
## 540 544 552 557 564 570 576
## 1 1 1 1 1 1 1
# 타수 빈도의 최소값과 최대값을 확인합니다.
range(hitters$타수)
## [1] 0 576
# 타수의 계급폭을 50으로 지정합니다.
breaks <- seq(from = min(hitters$타수),
to = max(hitters$타수),
by = 50)
# 계급을 확인합니다.
cat('breaks :', breaks, '\n')
## breaks : 0 50 100 150 200 250 300 350 400 450 500 550
# 도수분포표를 만듭니다.
cut4ab1 <- cut(x = hitters$타수,
breaks = breaks,
include.lowest = TRUE,
right = FALSE)
# 각 계급별의 빈도수를 확인합니다.
table(cut4ab1)
## cut4ab1
## [0,50) [50,100) [100,150) [150,200) [200,250) [250,300) [300,350)
## 117 26 22 20 11 15 19
## [350,400) [400,450) [450,500) [500,550]
## 20 17 12 8
cut() 함수를 사용하여 도수분포표를 만들 때, 이번 예제의 경우 550을 초과하는 데이터를 포함하지 않는 단점이 있습니다. 그 이유는 seq() 함수를 이용하여 breaks를 만들 때 최대값을 넘는 값을 만들지 못하기 때문입니다. 이러한 문제점을 보완하려면 Hmics 패키지의 cut2() 함수를 이용하면 됩니다.
# cut2() 함수를 사용하여 550을 초과하는 데이터도 포함시킵니다.
cut4ab2 <- Hmisc::cut2(x = hitters$타수,
cuts = breaks,
minmax = TRUE)
# 빈도수를 확인합니다.
table(cut4ab2)
## cut4ab2
## [ 0, 50) [ 50,100) [100,150) [150,200) [200,250) [250,300) [300,350)
## 117 26 22 20 11 15 19
## [350,400) [400,450) [450,500) [500,550) [550,576]
## 20 17 12 8 5
# prop.table() 함수를 이용하여 상대도수를 확인합니다.
table(cut4ab2) %>% prop.table() %>% round(digits = 2L)
## cut4ab2
## [ 0, 50) [ 50,100) [100,150) [150,200) [200,250) [250,300) [300,350)
## 0.40 0.09 0.08 0.07 0.04 0.05 0.07
## [350,400) [400,450) [450,500) [500,550) [550,576]
## 0.07 0.06 0.04 0.03 0.02
# cumsum() 함수를 추가하여 누적상대도수를 확인합니다.
table(cut4ab2) %>% prop.table() %>% round(digits = 2L) %>% cumsum()
## [ 0, 50) [ 50,100) [100,150) [150,200) [200,250) [250,300) [300,350)
## 0.40 0.49 0.57 0.64 0.68 0.73 0.80
## [350,400) [400,450) [450,500) [500,550) [550,576]
## 0.87 0.93 0.97 1.00 1.02
50타수 미만인 타자가 117명으로 전체 타자 중에서 약 40%의 비중을 차지하는 것을 알 수 있습니다. 산점도에서도 50타수 이하는 타율의 변동폭이 매우 크므로 50타수 이상인 타자들만 따로 선별하여 추가 분석을 진행하도록 하겠습니다.
# 50 타수 이상인 타자만 추출하여 hitters50 객체에 할당합니다.
hitters50 <- hitters[hitters$타수 >= 50, ]
# 새로운 데이터프레임의 차원을 확인합니다.
dim(x = hitters50)
## [1] 175 20
전체 행(선수)가 175명으로 줄어들었습니다. 이제 이 데이터로 다시 산점도를 그려보겠습니다. 그리고 타수와 타율 간 선형관계를 확인하고자 단순선형회귀선을 추가해보겠습니다.
# 타수와 타율을 기준으로 산점도를 그려봅니다.
plot(x = hitters50$타수,
y = hitters50$타율,
main = '타수와 타율 간 관계 (50타수 이상 타자)',
xlab = '타수',
ylab = '타율',
family = 'NanumGothic')
# 타수와 타율 간 선형관계를 확인하고자 단순선형회귀선을 추가합니다.
abline(reg = lm(formula = 타율 ~ 타수, data = hitters50),
col = 'red',
lty = 2)
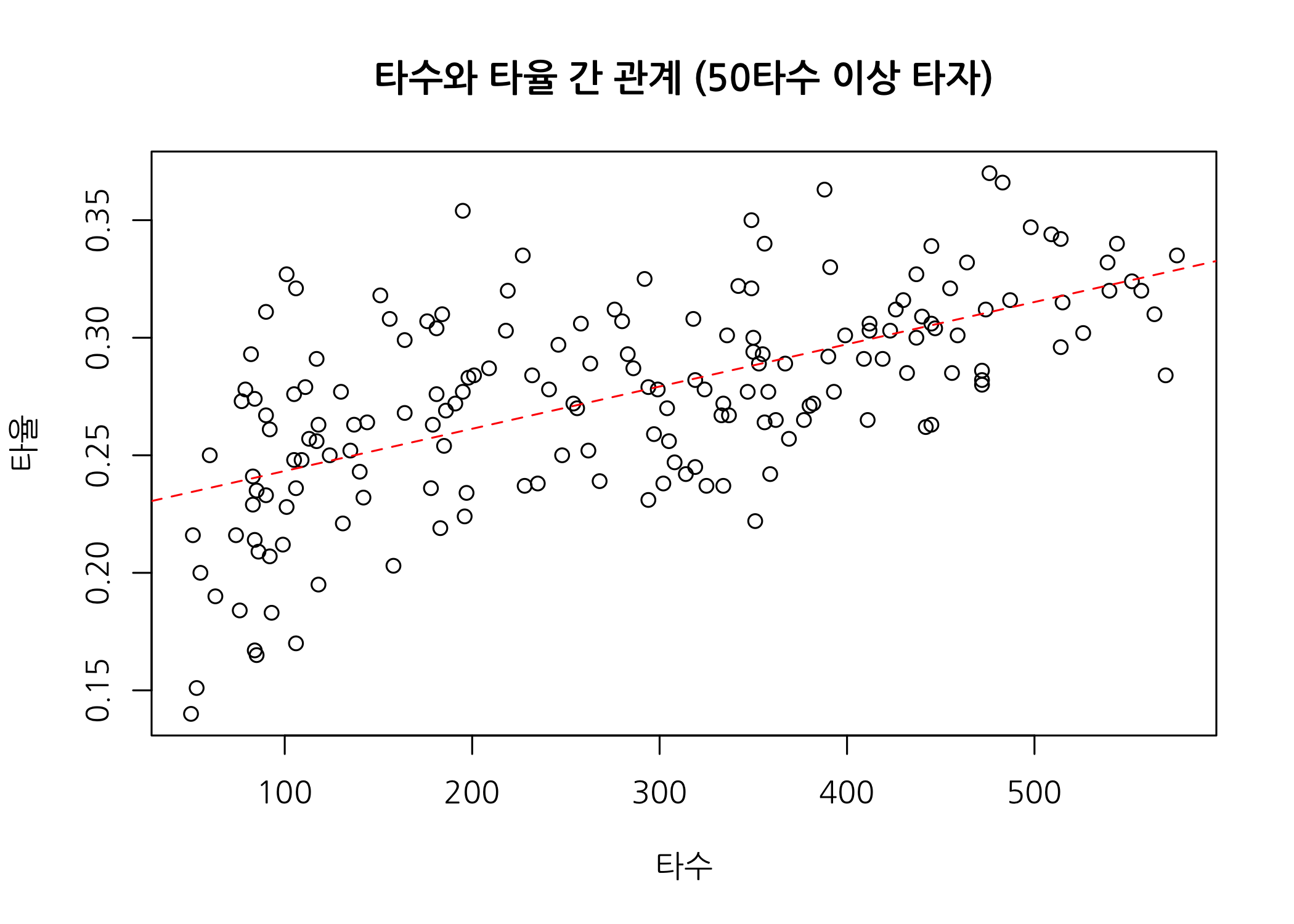
빨간색 회귀선 위, 아래로 점들이 고르게 퍼져 있는 것을 알 수 있습니다. 나중에 선형회귀를 다룰 때 자세하게 정리할 예정이지만, 독립변수가 1개인 선형회귀식의 결정계수(R-squared)는 두 변수 간 상관계수의 제곱으로 간단하게 구할 수 있습니다.
# 두 변수 간 상관계수를 구합니다.
cor.test(x = hitters50$타수, y = hitters50$타율)
##
## Pearson's product-moment correlation
##
## data: hitters50$타수 and hitters50$타율
## t = 10.231, df = 173, p-value < 2.2e-16
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## 0.5122940 0.6986851
## sample estimates:
## cor
## 0.6139777
# 상관계수의 제곱을 출력합니다.
cor(x = hitters50$타수, y = hitters50$타율) %>% .^2
## [1] 0.3769686
두 변수 간 피어슨 상관계수를 계산해보니 약 0.614이며, 이 때 p-value는 0이라 할 수 있으므로 두 변수 간 강한 양의 상관관계가 있다고 추정할 수 있습니다. 상관계수를 제곱하면 이 선형회귀식의 결정계수(R-squared)는 약 0.377이 됩니다.
위와 같이 두 변수를 할당하면 산점도를 그리고 상관계수와 상관계수의 제곱을 출력하는 사용자 정의 함수를 생성해보겠습니다.
# 사용자 정의 함수: 두 데이터 간 상관계수를 구하고, 산점도를 그려봅니다.
checkCorPlot <- function(var1, var2) {
# var1과 var2를 문자열로 변환하여 각각의 이름에 할당합니다.
var1name <- substitute(expr = var1) %>%
deparse() %>%
str_split(pattern = '\\$') %>%
`[[`(1) %>%
`[`(2)
var2name <- substitute(expr = var2) %>%
deparse() %>%
str_split(pattern = '\\$') %>%
`[[`(1) %>%
`[`(2)
# 산점도를 그립니다.
plot(x = var1,
y = var2,
main = paste0(var1name, ' & ', var2name, ' 간 관계'),
xlab = var1name,
ylab = var2name,
family = 'NanumGothic')
# 상관계수를 계산합니다.
# cor.test()를 실행하면, 결과 객체로 리스트를 반환합니다.
# 상관계수는 estimate 원소로 저장되므로 `$` 함수를 사용하여 추출합니다.
cor <- cor.test(x = var1, y = var2) %>%
`$`(estimate) %>%
round(digits = 3L) %>%
str_pad(width = 5, side = 'right', pad = '0')
rsq <- cor %>% as.numeric() %>% .^2 %>% round(digits = 3L)
# 산점도에서 상관계수를 출력할 위치를 잡습니다.
locX <- max(var1, na.rm = TRUE) * 0.85
locY <- max(var2, na.rm = TRUE) * 0.40
# 한글이 제대로 보이도록 한글폰트를 지정합니다.
par(family = 'NanumGothic')
# 산점도 우측 하단에 상관계수를 출력합니다.
text(x = locX,
y = locY,
labels = str_c('상관계수 : ', cor),
font = 2)
# 산점도에 선형회귀선을 추가합니다.
reg <- lm(formula = var2 ~ var1)
abline(reg = reg, col = 'red', lty = 2)
}
# 화면을 2행 * 2열로 분할합니다.
par(mfrow = c(2, 2))
# 입력변수를 바꿔가면서 산점도를 그려봅니다.
checkCorPlot(var1 = hitters50$홈런, var2 = hitters50$타율)
checkCorPlot(var1 = hitters50$삼진, var2 = hitters50$타율)
checkCorPlot(var1 = hitters50$타점, var2 = hitters50$타율)
checkCorPlot(var1 = hitters50$득점, var2 = hitters50$타율)
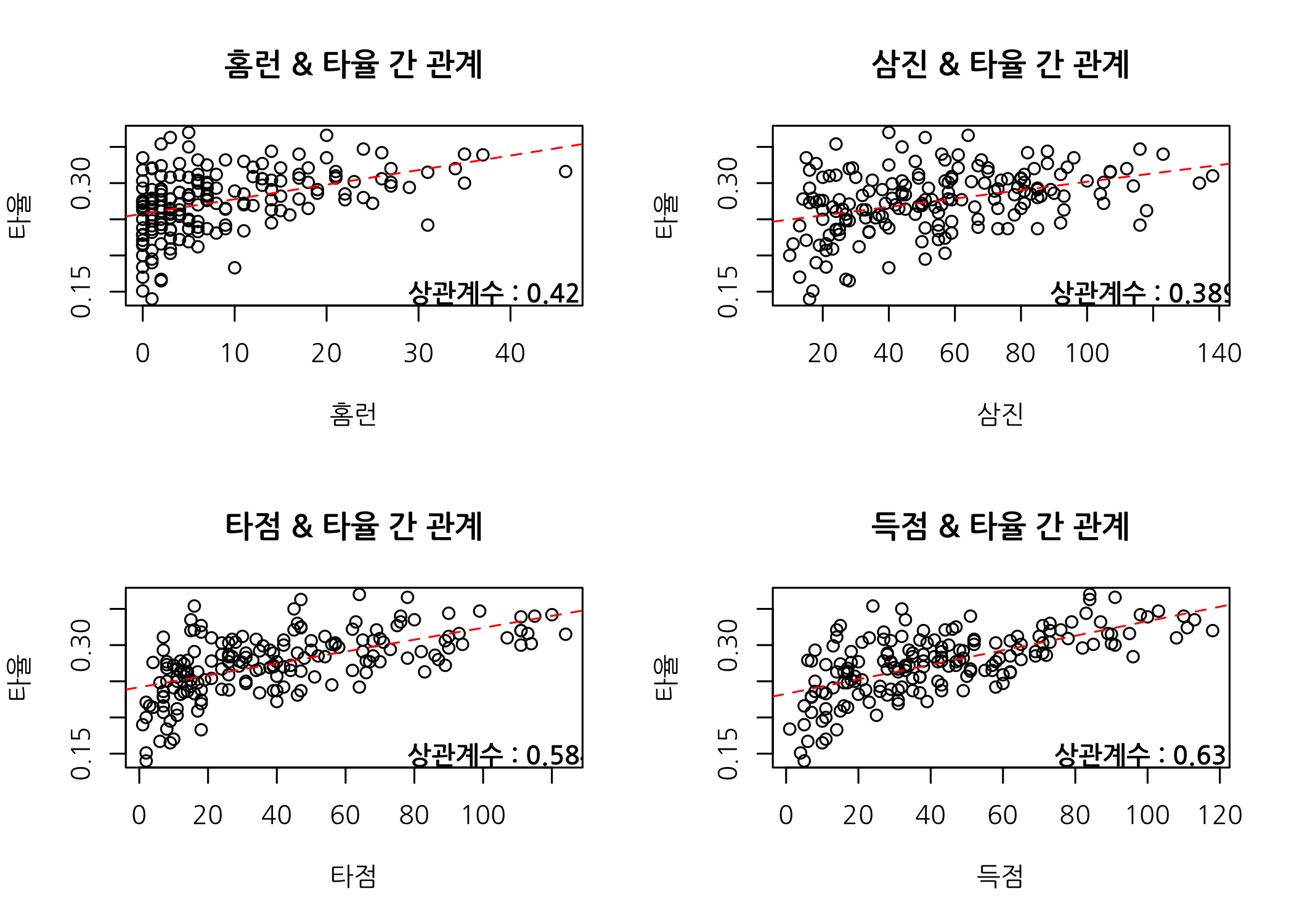
# 분할된 화면을 원래대로 (1행 * 1열) 되돌려 놓습니다.
par(mfrow = c(1, 1))
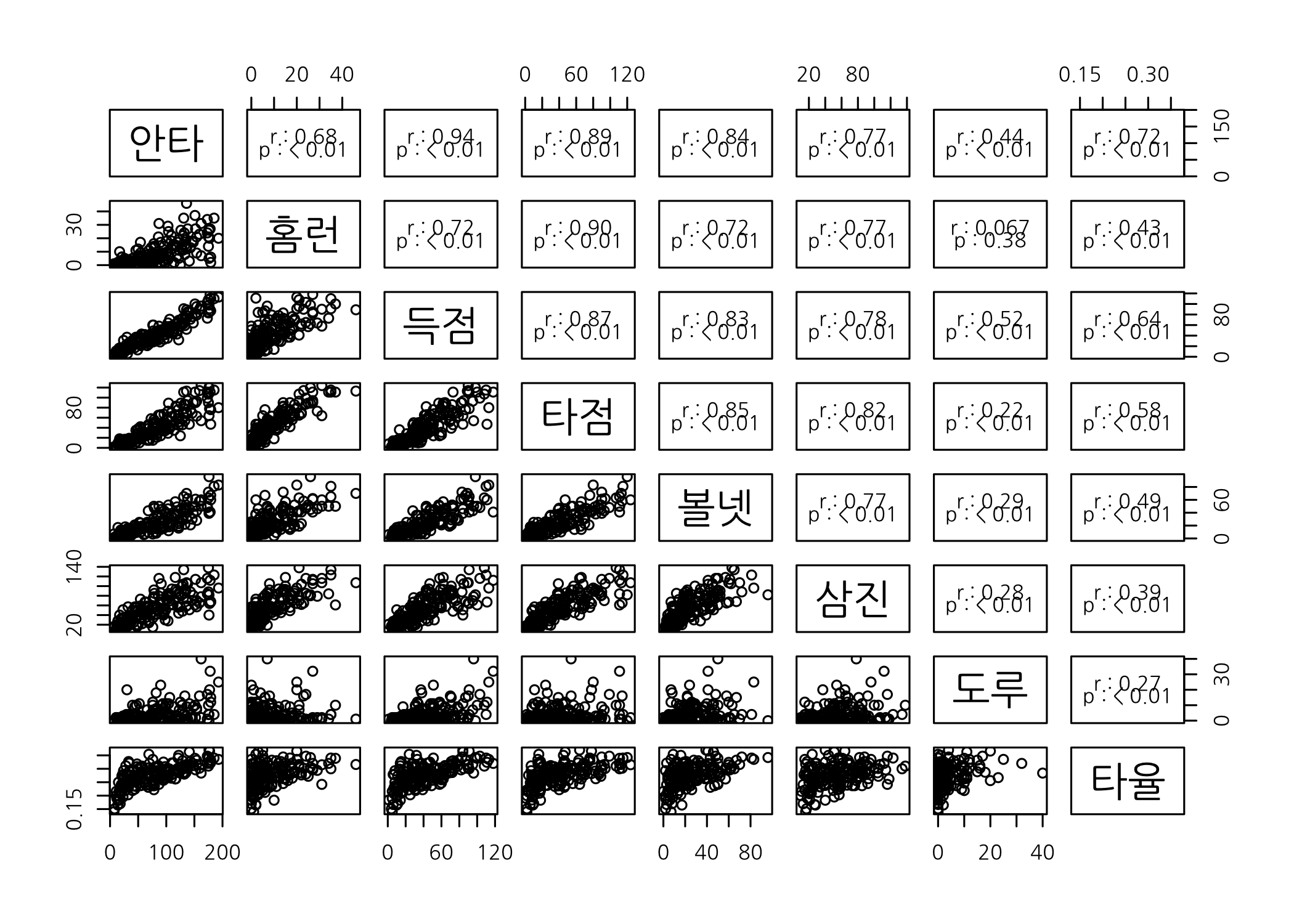
위와 같은 방법으로는 분석가가 관심 있는 열을 하나씩 지정해주기 전에는 다른 변수들 간 관계를 알아보기 어렵습니다. 이런 문제는 pairs() 함수를 사용하여 쉽게 해결할 수 있습니다. 이 함수에 데이터프레임을 할당하면 모든 숫자형 벡터들을 2개씩 골라 산점도를 그려줍니다.
# 여러 숫자형 벡터 간 산점도를 한꺼번에 출력합니다.
pairs(x = hitters50[, c(6:12, 14)])
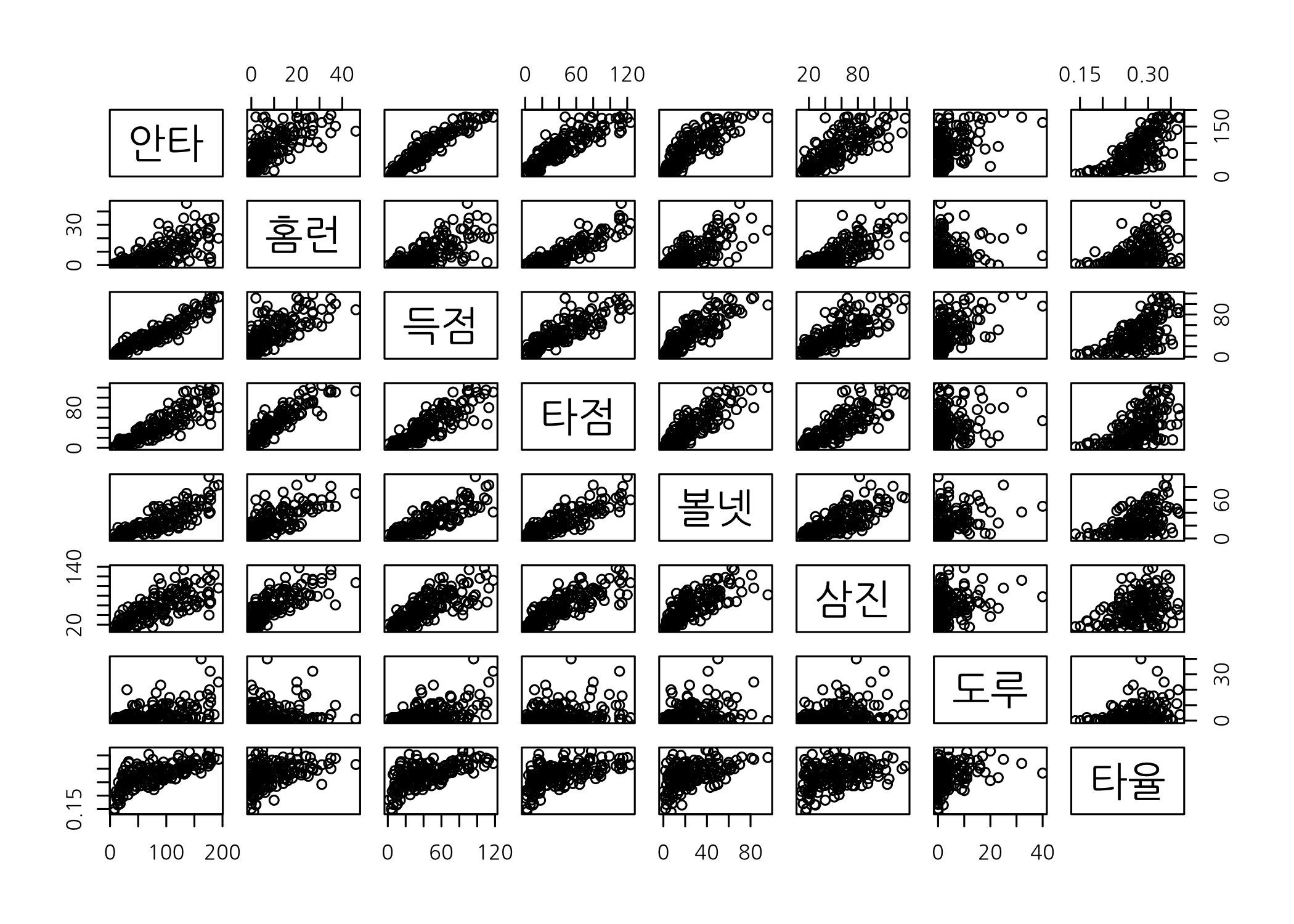
두 숫자형 벡터 간 공분산과 상관계수 행렬를 구하면 관계의 정도를 숫자로 확인할 수 있습니다. 공분산은 두 개의 변수가 변화하는 정도는 알 수 있으나 서로 비교하기 어려우므로, 공분산을 각각의 표준편차로 나누어 표준화한 상관계수 행렬을 구하면 상관관계의 정도를 서로 비교할 수 있습니다.
# 공분산 행렬을 출력합니다.
cov(x = hitters50[, c(6:12, 14)])
## 안타 홈런 득점 타점 볼넷
## 안타 2418.242496 310.171166 1274.7263711 1341.1653530 774.3650246
## 홈런 310.171166 84.787061 181.1066995 255.0075534 125.6870279
## 득점 1274.726371 181.106700 753.8895238 734.5203612 432.0978654
## 타점 1341.165353 255.007553 734.5203612 947.4072250 492.5665025
## 볼넷 774.365025 125.687028 432.0978654 492.5665025 355.2512315
## 삼진 1104.352512 205.190870 619.4578982 737.5372742 420.2681445
## 도루 130.056716 3.708079 86.8318227 40.6422003 32.9013136
## 타율 1.522114 0.170486 0.7563604 0.7782775 0.4028268
## 삼진 도루 타율
## 안타 1104.352512 130.05671593 1.522114122
## 홈런 205.190870 3.70807882 0.170486043
## 득점 619.457898 86.83182266 0.756360427
## 타점 737.537274 40.64220033 0.778277504
## 볼넷 420.268144 32.90131363 0.402826765
## 삼진 843.999475 48.32272578 0.489422003
## 도루 48.322726 36.55848933 0.071693760
## 타율 0.489422 0.07169376 0.001871997
# 상관계수 행렬을 출력합니다.
cor(x = hitters50[, c(6:12, 14)])
## 안타 홈런 득점 타점 볼넷 삼진
## 안타 1.0000000 0.68499391 0.9440896 0.8860619 0.8354645 0.7730128
## 홈런 0.6849939 1.00000000 0.7163345 0.8997460 0.7241989 0.7670473
## 득점 0.9440896 0.71633451 1.0000000 0.8691238 0.8349500 0.7765812
## 타점 0.8860619 0.89974597 0.8691238 1.0000000 0.8490411 0.8247922
## 볼넷 0.8354645 0.72419892 0.8349500 0.8490411 1.0000000 0.7675163
## 삼진 0.7730128 0.76704732 0.7765812 0.8247922 0.7675163 1.0000000
## 도루 0.4374100 0.06660243 0.5230352 0.2183809 0.2887030 0.2750972
## 타율 0.7153931 0.42792878 0.6366818 0.5844046 0.4939671 0.3893676
## 도루 타율
## 안타 0.43741003 0.7153931
## 홈런 0.06660243 0.4279288
## 득점 0.52303523 0.6366818
## 타점 0.21838095 0.5844046
## 볼넷 0.28870302 0.4939671
## 삼진 0.27509723 0.3893676
## 도루 1.00000000 0.2740531
## 타율 0.27405309 1.0000000
pairs() 함수의 패널을 분석가가 임의로 정할 수 있습니다. 대각원소의 오른쪽 위를 상삼각행렬이라고 하고, 왼쪽 아래를 하삼각행렬이라고 하는데, 이번 예제에서는 상삼각행렬을 산점도 대신 상관계수와 p-value를 출력하도록 변경해보겠습니다.[3]
# 삼각행렬의 패널에 분석가가 원하는 출력 방식을 지정합니다.
panel.cor <- function(x, y, digits = 2, cex.cor, ...) {
# 그래프를 출력할 범위를 지정합니다.
usr <- par('usr')
on.exit(expr = par(usr))
par(usr = c(0, 1, 0, 1))
# 상관계수를 계산합니다.
r <- cor(x = x, y = y)
txt1 <- format(x = c(r, 0.123456789), digits = digits)[1]
txt1 <- paste('r : ', txt1, sep = '')
text(x = 0.5, y = 0.6, labels = txt1, cex = 1.0)
# p-value를 계산합니다.
p <- cor.test(x = x, y = y)$p.value
txt2 <- format(x = c(p, 0.123456789), digits = digits)[1]
txt2 <- paste('p : ', txt2, sep = '')
if(p < 0.01) txt2 <- paste('p : ', '< 0.01', sep = '')
text(x = 0.5, y = 0.4, labels = txt2, cex = 1.0)
}
# 위에서 생성한 사용자 정의 함수를 활용하여 산점도 행렬을 그려봅니다.
pairs(x = hitters50[, c(6:12, 14)], upper.panel = panel.cor)
파생변수 만들기
탐색적 데이터 분석을 하다보면 (혹은 데이터 전처리를 할 때) 기존 데이터를 변형하여 새로운 파생변수들을 생성해야 하는 경우가 상당히 많습니다. 아래에는 제가 임의대로 만든 몇 가지 비율 변수들입니다. 아마도 많이 생소하실 거예요.
# 숫자형 벡터의 절대 규모를 그대로 쓰는 대신 타수로 나눈 비율값으로
# 구성된 새로운 데이터프레임을 생성합니다.
hitters51 <- data.frame(타율 = hitters50$타율,
홈런율 = hitters50$홈런 / hitters50$타수,
득점률 = hitters50$득점 / hitters50$타수,
타점률 = hitters50$타점 / hitters50$타수,
볼넷률 = hitters50$볼넷 / hitters50$타수,
삼진율 = hitters50$삼진 / hitters50$타수,
도루율 = hitters50$도루 / hitters50$타수)
# 산점도 행렬을 그립니다.
pairs(x = hitters51, upper.panel = panel.cor)
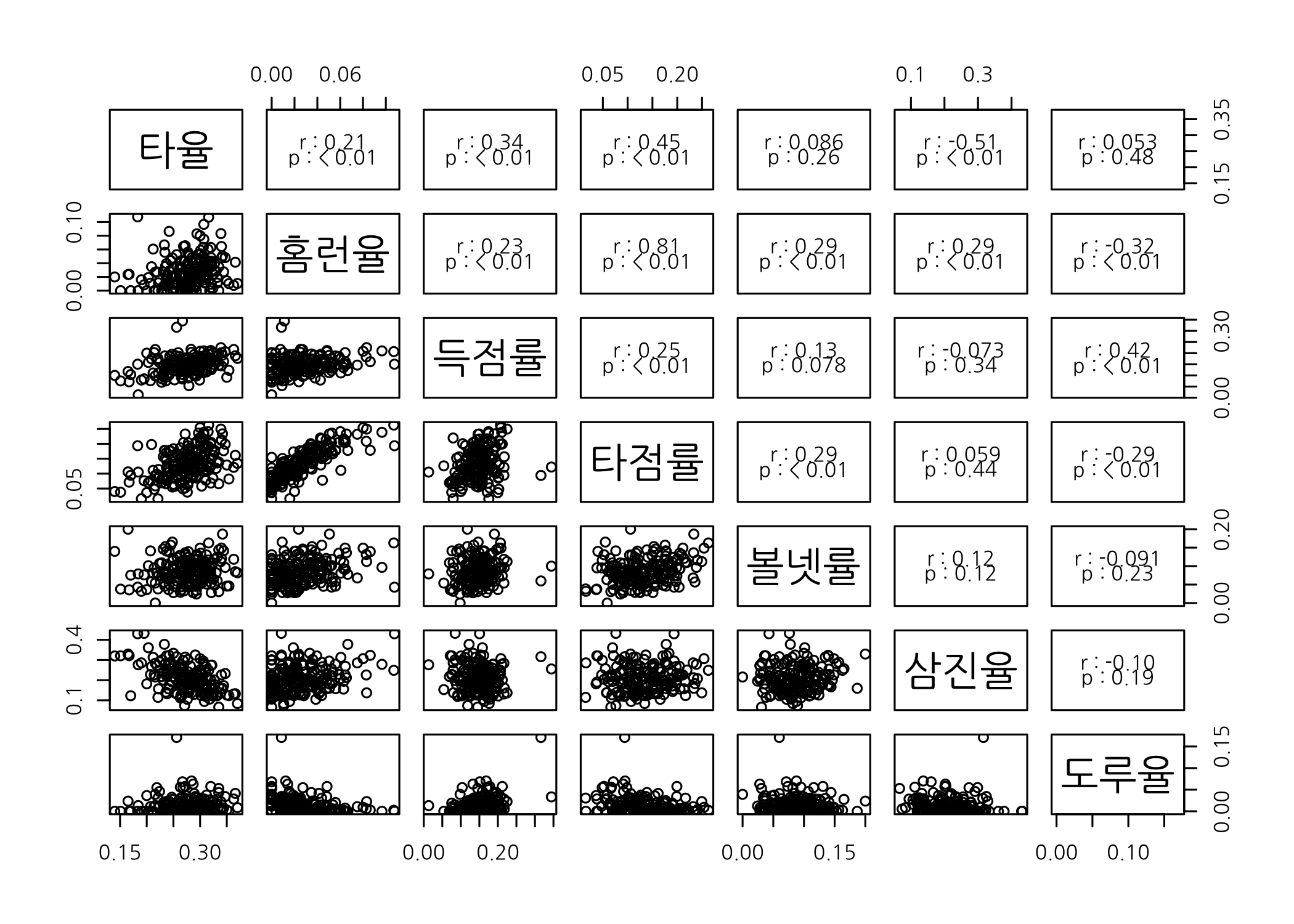
새로 만든 파생변수들로 산점도 행렬을 그려보니 원래 열(컬럼)로 한 것이 훨씬 낫습니다. 이번에는 쓸데없는 걸 한 것 같습니다.
숫자형 벡터 정렬하기
숫자형 벡터를 오름차순 또는 내림차순으로 정렬한 후, 해당 벡터만으로 산점도를 그려봄으로써 새로운 사실과 마주하기도 합니다. 이번 예제에서는 타율을 오름차순으로 정렬한 후 산점도를 그려보겠습니다.
# 올림차순, 내림차순으로 정렬하여 산점도를 그려봅니다.
plot(x = sort(hitters50$타율), family = 'NanumGothic')
# quantile() 함수를 이용하여 기준선을 몇 개 추가합니다.
baseline <- quantile(x = hitters50$타율,
probs = c(0.90, 0.75, 0.50, 0.25),
na.rm = TRUE) %>%
round(digits = 3L)
# 기준선을 그립니다.
for (i in 1:length(baseline)) {
# 빨간색 점선으로 기준선을 그립니다.
abline(h = baseline[i], col = 'red', lty = 3)
# 기준선 위에 기준값을 추가합니다.
text(x = 20,
y = baseline[i],
labels = str_c(names(baseline)[i], ' : ', baseline[i]),
pos = 3,
cex = 0.8,
font = 2)
}
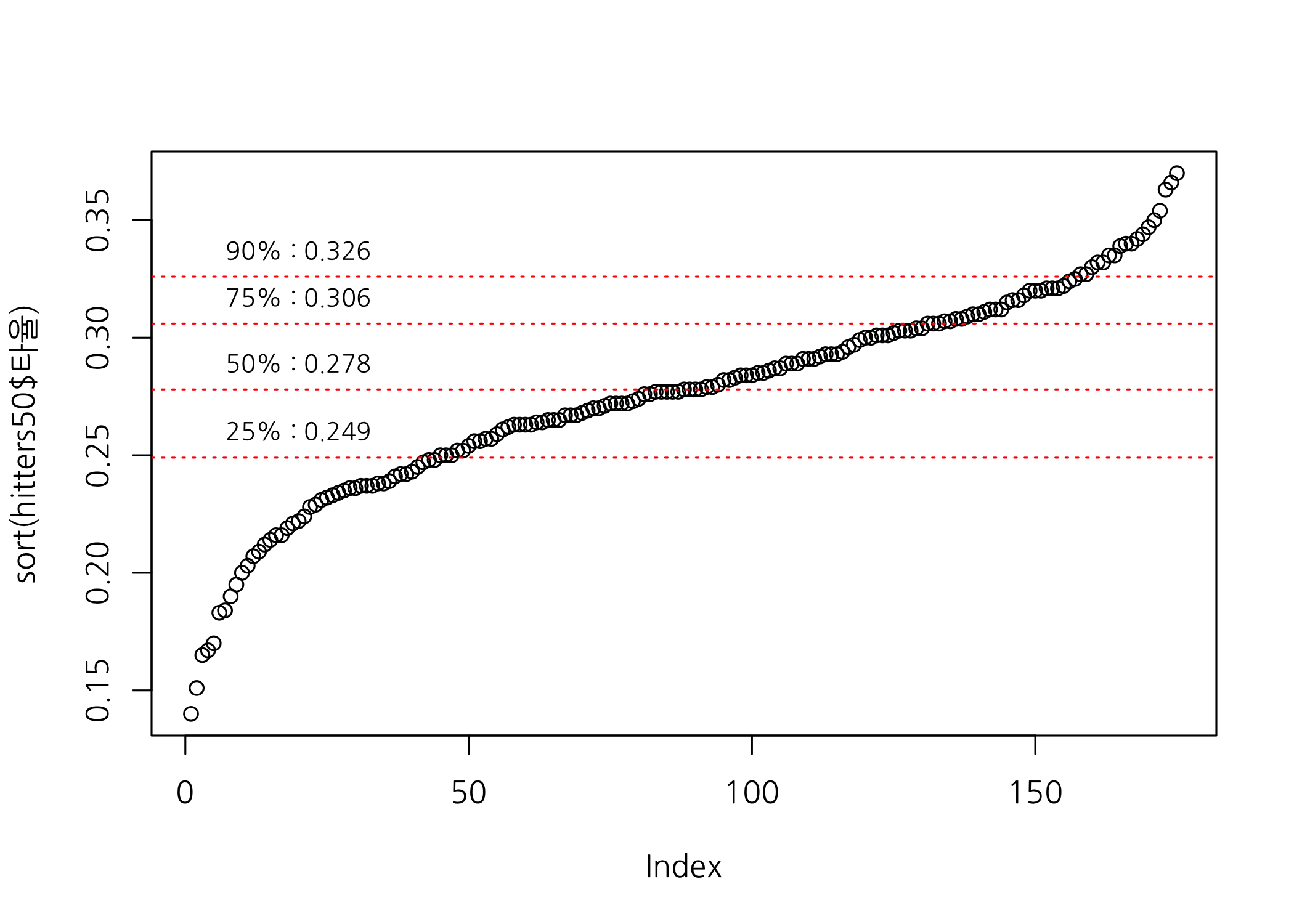
타율 기준으로 오름차순 정렬하여 산점도를 그려보니 전체적인 그림은 S형 곡선으로 보이지만 25%에서 90% 사이는 거의 직선으로 형태를 띄고 있음을 알 수 있습니다. 최상위에 위치하는 소수의 타자들은 정말 뛰어난 결과를 거두는 것으로 확인할 수 있습니다. 궁금하신 분들은 홈런, 삼진 이런 스탯들을 가지고 그래프를 그려보세요.
산점도에 몇 가지 정보 추가하기
단순히 산점도만 그리면 재미도 없고 눈에 확 띄는 인사이트를 발견하기도 쉽지 않죠. 그래서 산점도에 몇 가지 정보를 추가하면 재미있는 사실을 발견할 수 있습니다.
# 타율과 홈런 데이터로 산점도를 그립니다.
plot(x = hitters50$타율,
y = hitters50$홈런,
main = '타율과 홈런 간의 관계',
xlab = '타율',
ylab = '홈런',
family = 'NanumGothic')
# 각각의 평균으로 수직선과 수평선을 그려서 2행 * 2열 매트릭스로 표현합니다.
abline(v = mean(hitters50$타율),
h = mean(hitters50$홈런),
lty = 2,
col = 'red')
# 관심선수만 추출합니다.
hittersFP <- hitters[hitters$관심선수 == '1', ]
# 관심선수만 산점도 위에 빨간점으로 추가합니다.
points(x = hittersFP$타율,
y = hittersFP$홈런,
col = 'red',
pch = 16,
lwd = 2)
# 관심선수만 점 왼쪽에 파란색으로 이름을 출력합니다.
text(x = hittersFP$타율,
y = hittersFP$홈런,
labels = hittersFP$선수명,
col = 'blue',
pos = 2,
cex = 0.8,
font = 2,
family = 'NanumGothic')
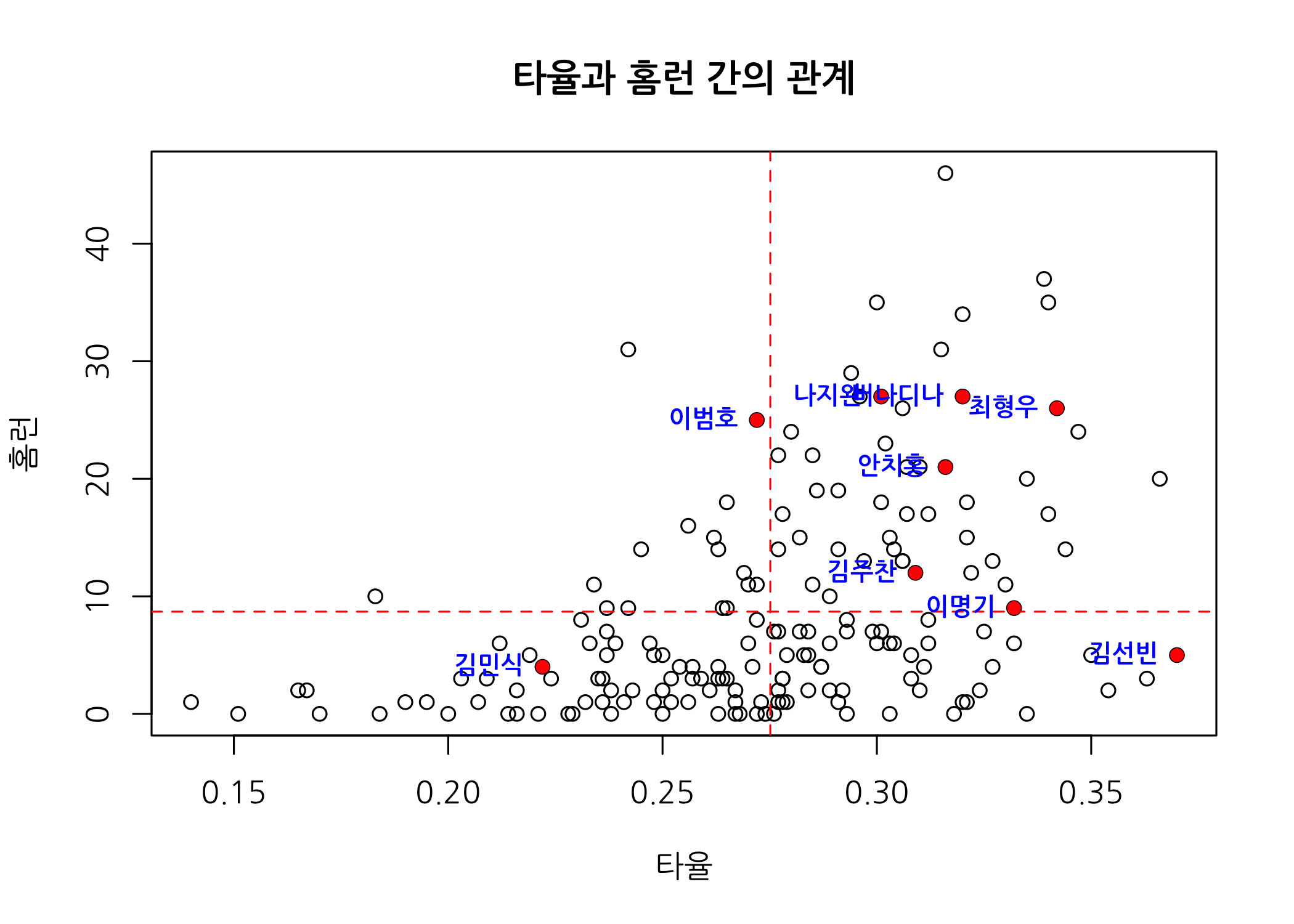
작년 우승팀답게 KIA 타이거즈의 주전선수 9명 중에서 상위 50% 타자들의 평균 타율보다 낮은 선수는 딱 2명입니다. 이범호 선수는 거의 평균이라고 보면, 안방마님으로 중요한 역할을 수행한 김민식 선수만 타율이 낮다고 볼 수 있습니다. 우연의 일치인지 상위 50% 타자들의 평균 홈런 개수보다 낮은 선수도 2명인데요. 그 중 한 명은 타격왕 김선빈 선수이니 홈런 개수 적은 게 문제될 일은 없고, 나머지 한 명은 안방마님이니 공격 스탯이 좀 낮아도 전혀 문제가 없겠죠.
이번에는 팀명을 기준으로 다른 팀 선수들도 살펴보도록 하겠습니다.
# 산점도와 가로/세로 기준선을 새로 그립니다.
plot(x = hitters50$타율,
y = hitters50$홈런,
family = 'NanumGothic')
abline(v = mean(hitters50$타율),
h = mean(hitters50$홈런),
lty = 2,
col = 'red')
# 이번에는 LG 선수만 빨간점으로 표시하고 이름을 추가해봅니다.
# 지난해 1군에 등록된 선수가 많으니 288 타석 이상인 선수만 선별합니다.
hittersLG <- hitters50[hitters50$팀명 == 'LG' & hitters50$타석 >= 288, ]
# 산점도를 그립니다.
points(x = hittersLG$타율,
y = hittersLG$홈런,
col = 'red',
pch = 16,
lwd = 2)
# 이번에틑 선수명을 점 위에 출력해보겠습니다.
text(x = hittersLG$타율,
y = hittersLG$홈런,
labels = hittersLG$선수명,
col = 'blue',
pos = 3,
cex = 0.8,
font = 2,
family = 'NanumGothic')
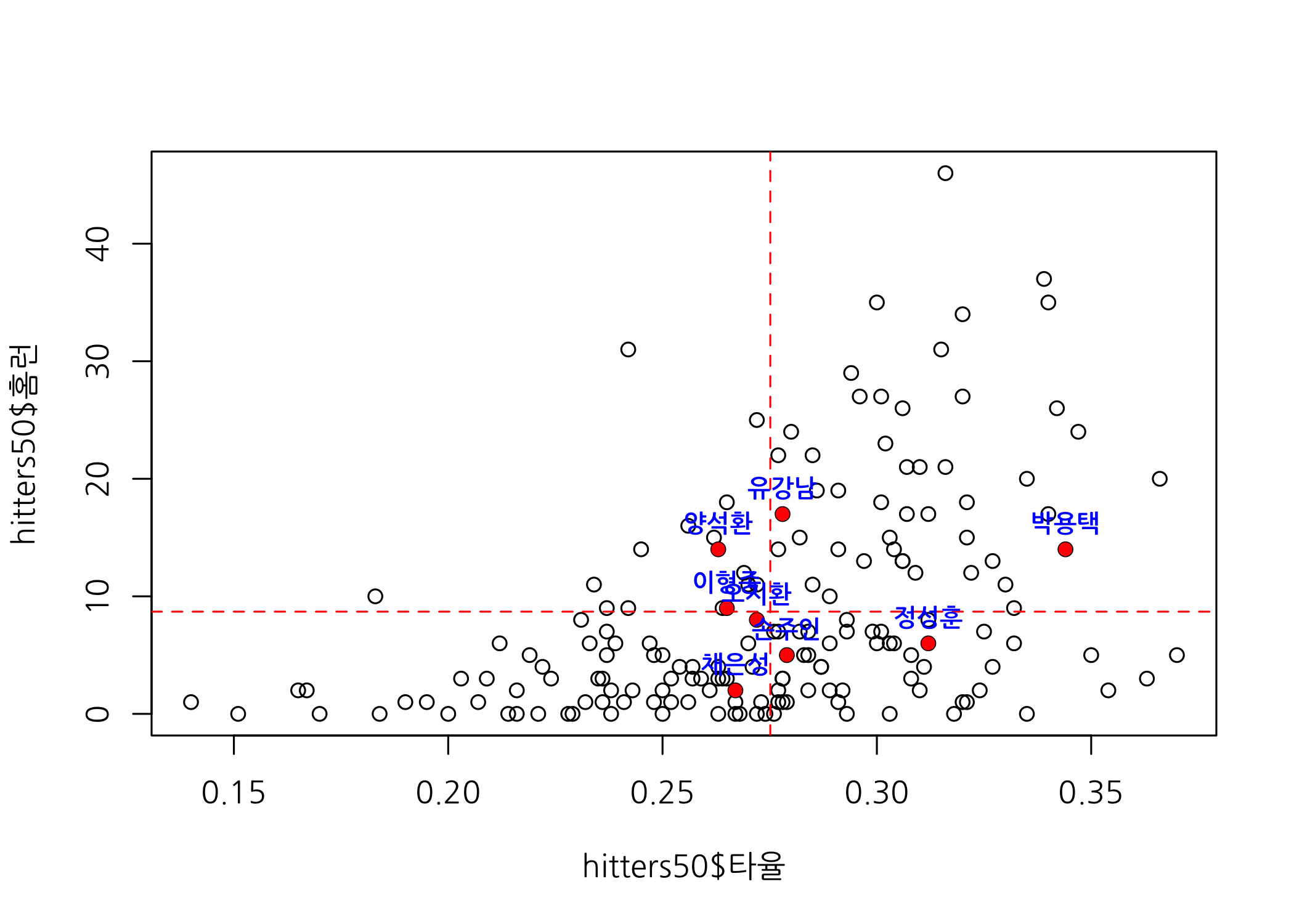
2017년에는 모두 144 경기를 치뤘으니 주전이라면 최소한 경기당 평균 2회 타석에 들어선다고 가정하고 선수를 선별한 결과 모두 8명이 선택되었습니다. 박용택과 정성훈을 제외하고는 대체로 평균 타율 주위에 분포하고 있음을 알 수 있습니다. 그나마 평균을 넘은 선수 4명 중 올해 다른 팀에서 뛰고 있는 선수가 2명이나 되네요. 포수 스탯은 부럽습니다. ㅎㅎ
다음으로는 장타율과 출루율 기준으로 저의 관심선수들이 어떻게 활약(?)했는지 확인해보도록 하겠습니다.
# 장타율과 출루율 기준으로 산점도와 가로/세로 기준선을 그립니다.
plot(x = hitters50$장타율,
y = hitters50$출루율,
family = 'NanumGothic')
abline(v = mean(hitters50$장타율),
h = mean(hitters50$출루율),
col = 'red',
lty = 2)
# 관심선수를 빨간점으로 표시하고 이름을 추가합니다.
points(x = hittersFP$장타율,
y = hittersFP$출루율,
pch = 16,
lwd = 2,
col = 'red')
# 이번에는 선수명을 점 오른쪽에 출력하겠습니다.
text(x = hittersFP$장타율,
y = hittersFP$출루율,
labels = hittersFP$선수명,
col = 'blue',
pos = 4,
cex = 0.8,
font = 2,
family = 'NanumGothic')
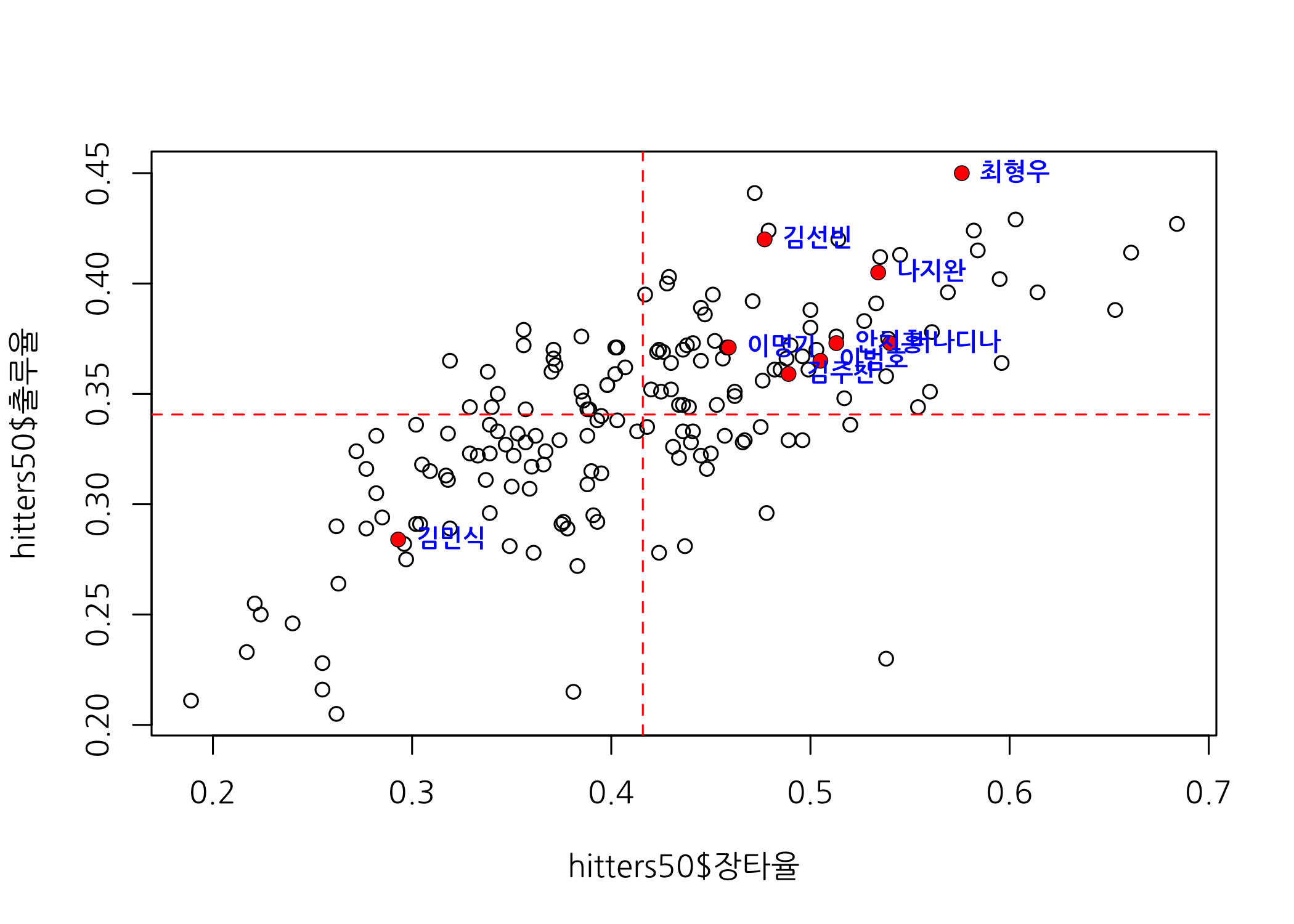
프로야구 타자의 주요 스탯 중 OPS가 있는데요. OPS는 장타율과 출루율의 합계로 산출되는 스탯입니다. OPS가 0.9 이상이면 수위타자라고 평가받습니다. 이번에는 산점도에서 각 점들을 OPS 기준으로 색을 달리할 수 있도록 그라데이션을 추가해보겠습니다.
# 장타율과 출루율 기준으로 산점도와 가로/세로 기준선을 그립니다.
plot(x = hitters50$장타율,
y = hitters50$출루율,
pch = 16,
col = 'gray80',
main = '2017 프로야구 타자 장타율 vs 출루율',
xlab = '장타율',
ylab = '출루율',
family = 'NanumGothic')
abline(v = mean(hitters50$장타율),
h = mean(hitters50$출루율),
col = 'red',
lty = 2)
# OPS 높을수록 채우기 색상을 진하게 표시합니다.
opsLvls <- c(0.8, 0.9, 1.0)
opsCols <- c('gray60', 'gray40', 'gray20')
for (i in 1:length(opsLvls)) {
points(x = hitters50$장타율[hitters50$OPS >= opsLvls[i]],
y = hitters50$출루율[hitters50$OPS >= opsLvls[i]],
pch = 16,
col = opsCols[i])
}
# 관심선수만 이름을 출력합니다.
points(x = hittersFP$장타율,
y = hittersFP$출루율,
col = 'black')
# 선수명을 점 아래에 출력합니다.
text(x = hittersFP$장타율,
y = hittersFP$출루율,
labels = hittersFP$선수명,
col = 'blue',
pos = 1,
cex = 0.8,
font = 2,
family = 'NanumGothic')
# 범례를 추가합니다. 범례의 위치는 산점도를 그려보면서 정하면 됩니다.
legend(x = max(hitters50$장타율) * 0.9,
y = min(hitters50$출루율) * 1.2,
legend = c('OPS < 0.8', 'OPS >= 0.8', 'OPS >= 0.9', 'OPS >= 1.0'),
col = c('gray80', 'gray60', 'gray40', 'gray20'),
pch = 16,
cex = 0.8,
bty = 'n')
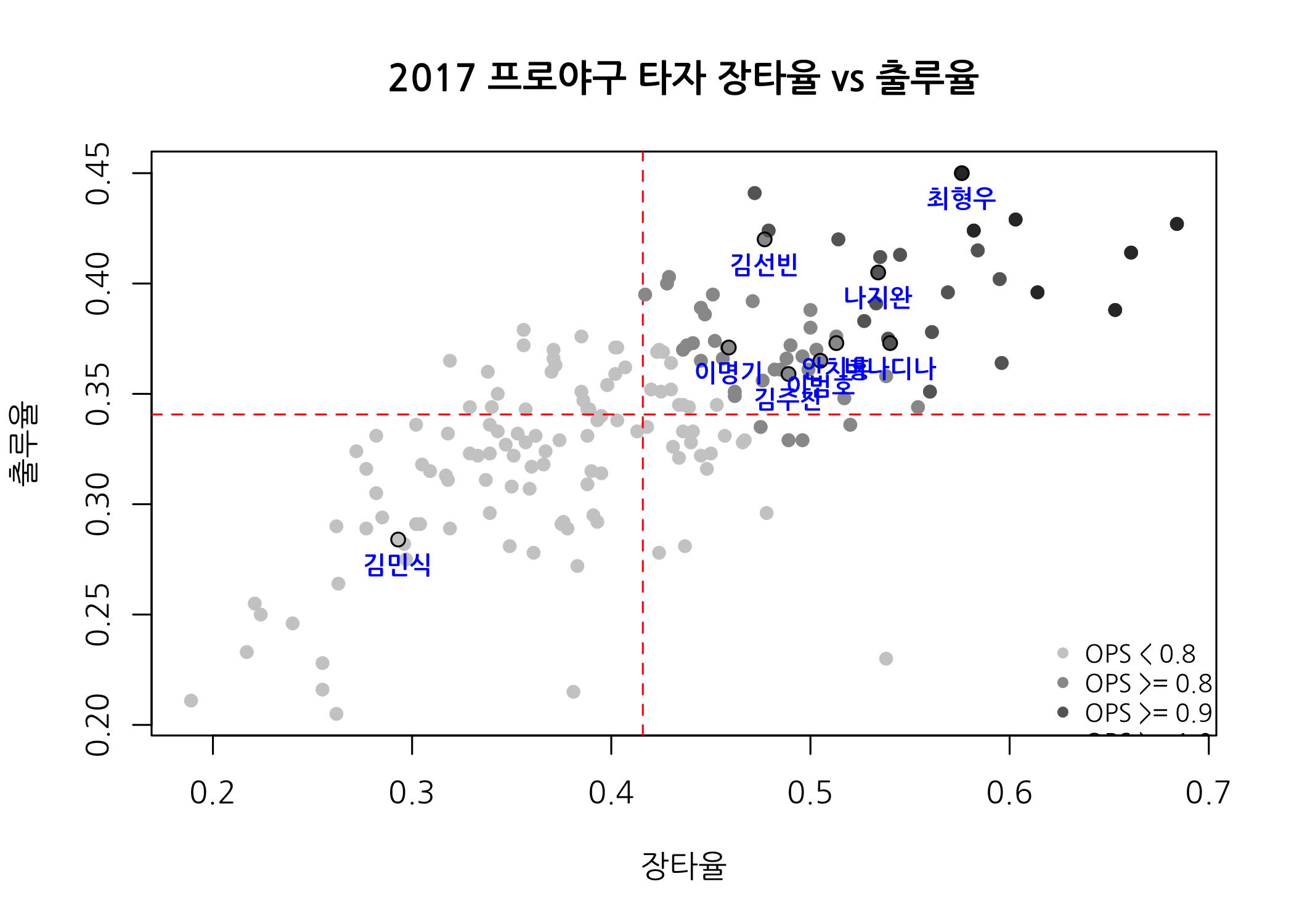
히스토그램으로 분포 확인하기
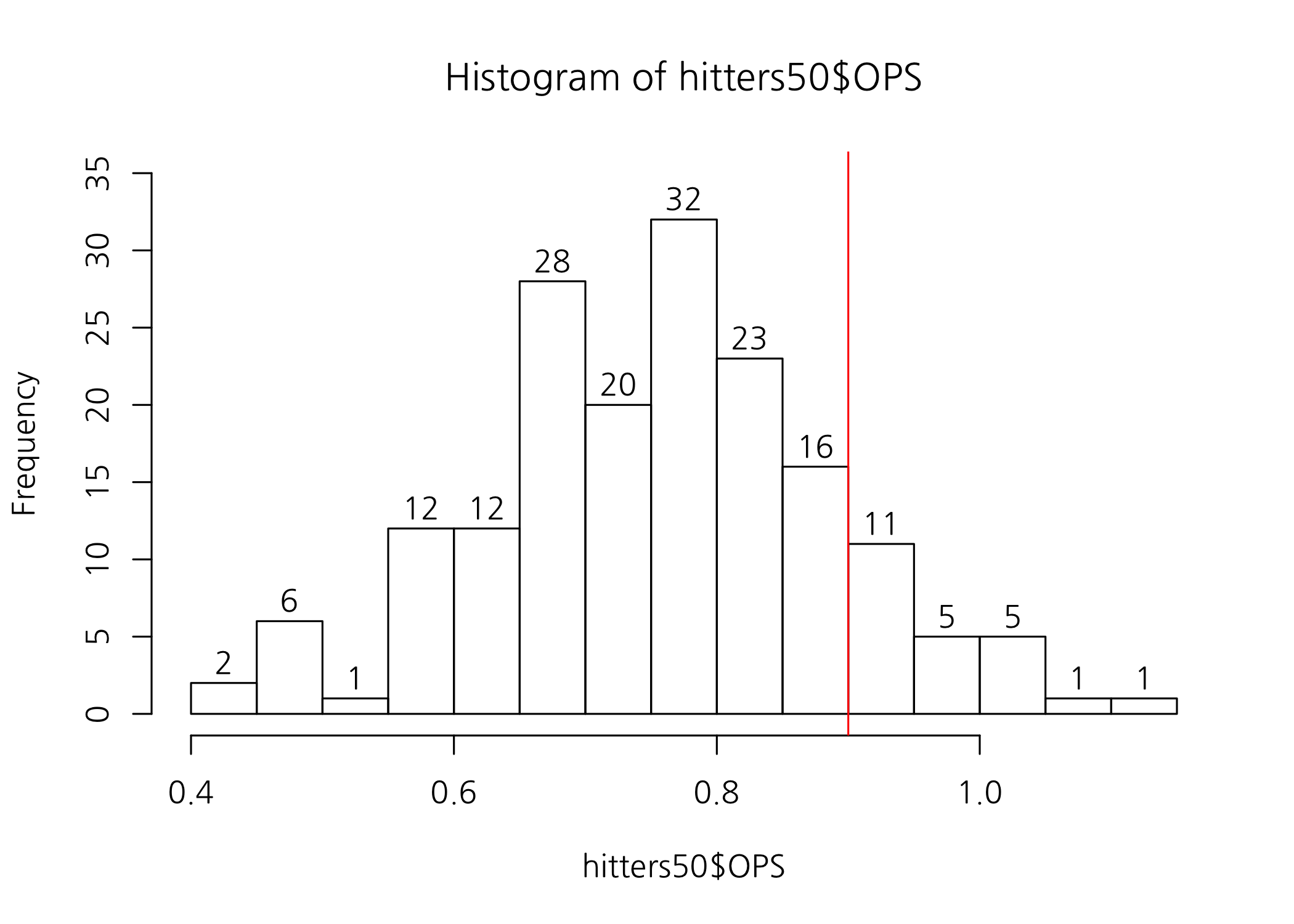
이번 예제에서는 타자 OPS 기준으로 히스토그램을 그리고 전체 분포를 살펴봅니다. 수위타자의 기준이 되는 0.9에 기준선을 빨간색으로 추가하여 시각적으로 표현할 수 있습니다.
# 데이터의 범위를 확인합니다.
range(hitters50$OPS)
## [1] 0.400 1.111
# 최대값과 최소값의 차이를 적당한 개수로 나눠서 게급값을 정합니다.
range(hitters50$OPS) %>% diff() / 15
## [1] 0.0474
# 최대값과 최소값을 이용하여 계급 구분값을 만듭니다.
breaks <- seq(from = min(hitters50$OPS),
to = max(hitters50$OPS),
by = 0.05)
# 이렇게 하는 경우 마지막 구분값을 초과하는 값은 포함되지 않으므로
# 맨 마지막 구분값에 by 만큼의 숫자를 더하여 추가해줍니다.
breaks <- c(breaks, breaks[length(breaks)] + 0.05)
# 히스토그램을 그립니다.
hist(x = hitters50$OPS,
breaks = breaks,
ylim = c(0, 35),
labels = TRUE)
abline(v = 0.9, col = 'red')
두 개의 히스토그램을 겹쳐서 그리면 두 숫자형 벡터의 분포를 비교할 수 있습니다. OPS를 구성하는 장타율과 출루율에 대해서 히스토그램을 겹쳐서 그려보겠습니다. 이 때 주의할 점은 각각의 계급값이 같아야 막대가 예쁘게(?) 그려진다는 것입니다.
# 장타율과 출루율의 범위를 확인합니다.
range(hitters50$장타율)
## [1] 0.189 0.684
range(hitters50$출루율)
## [1] 0.205 0.450
# 두 범위의 최소값과 최대값으로 적당한 계급값을 정합니다.
(max(hitters50$장타율) - min(hitters50$장타율)) / 20
## [1] 0.02475
# 계급 구분값을 만들고 마지막에 숫자를 추가합니다.
breaks <- seq(from = min(hitters50$장타율) %>% round(digits = 1L),
to = max(hitters50$장타율) %>% round(digits = 1L),
by = 0.025)
# 이번 예제에서는 첫 구분값 미만인 값이 포함되지 않으므로
# 맨 처음 구분값에 by 만큼의 숫자를 빼서 추가해줍니다.
breaks <- c(breaks[1] - 0.025, breaks)
# 장타율 데이터로 첫 번째 히스토그램을 그립니다.
hist(x = hitters50$장타율,
breaks = breaks,
col = 'gray60',
xlim = range(breaks),
ylim = c(0, 50),
xlab = '장타율 및 출루율',
ylab = '빈도수',
main = '장타율과 출루율 히스토그램 비교',
family = 'NanumGothic')
# 두 번째 히스토그램에 'add = TRUE'를 추가하면 기존 히스토그램에 겹쳐집니다.
hist(x = hitters50$출루율,
breaks = breaks,
col = 'gray80',
add = TRUE)
# 범례를 추가합니다.
legend(x = 0.6,
y = 50,
legend = c('장타율', '출루율'),
col = c('gray60', 'gray80'),
pch = 15,
cex = 1.0,
bty = 'n')
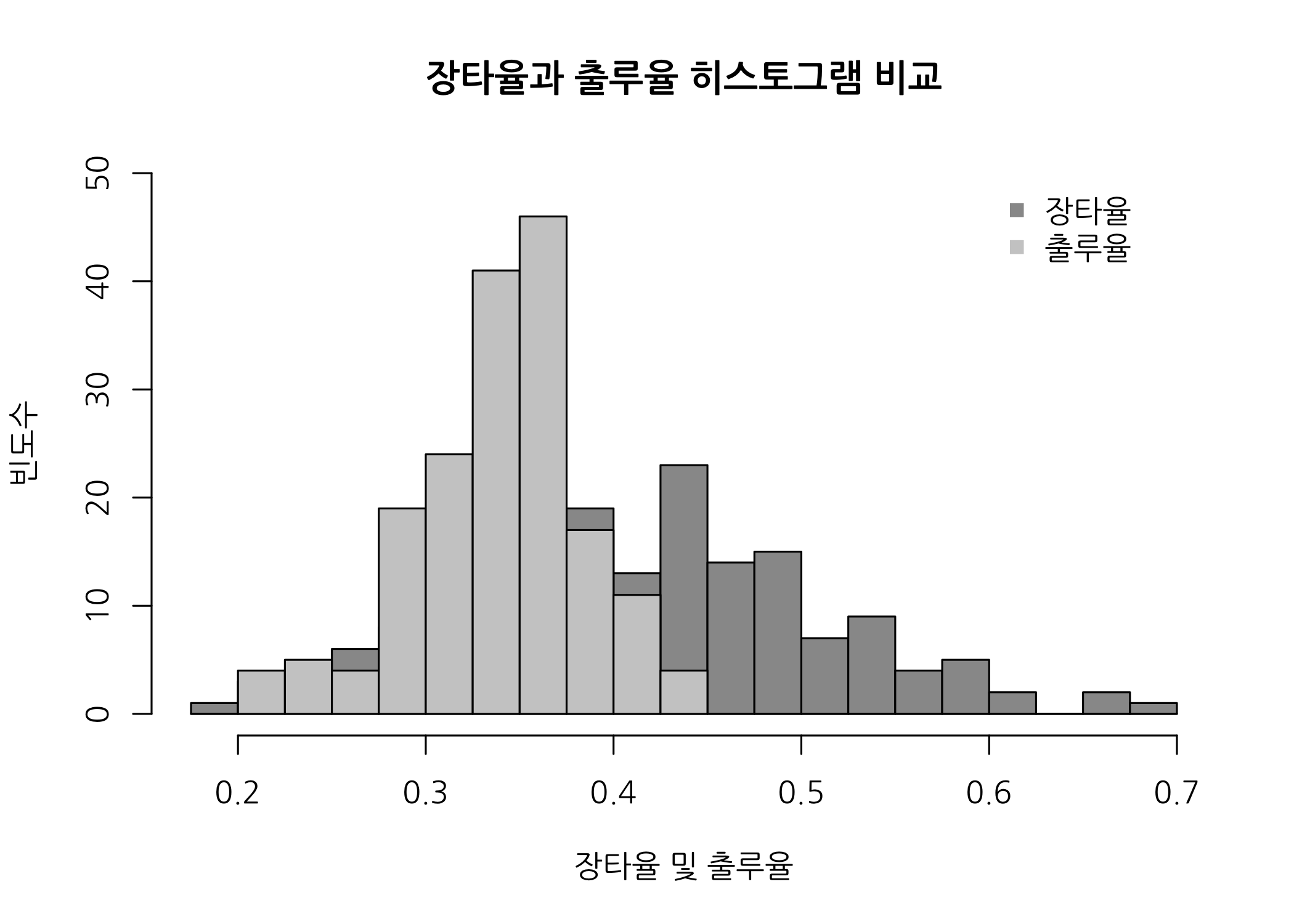
상자수염그림으로 그룹별 분포 확인하기
숫자형 벡터의 전체 분포를 확인해봤으니, 이번에는 상자수염그림을 그려서 그룹별(이번 예제에서는 팀별) 분포를 확인해보겠습니다.
# 팀별 타율 분포를 비교합니다.
boxplot(formula = 타율 ~ 팀명,
data = hitters50,
xlab = '팀명',
ylab = '타율',
main = '팀별 타율 분포 비교')
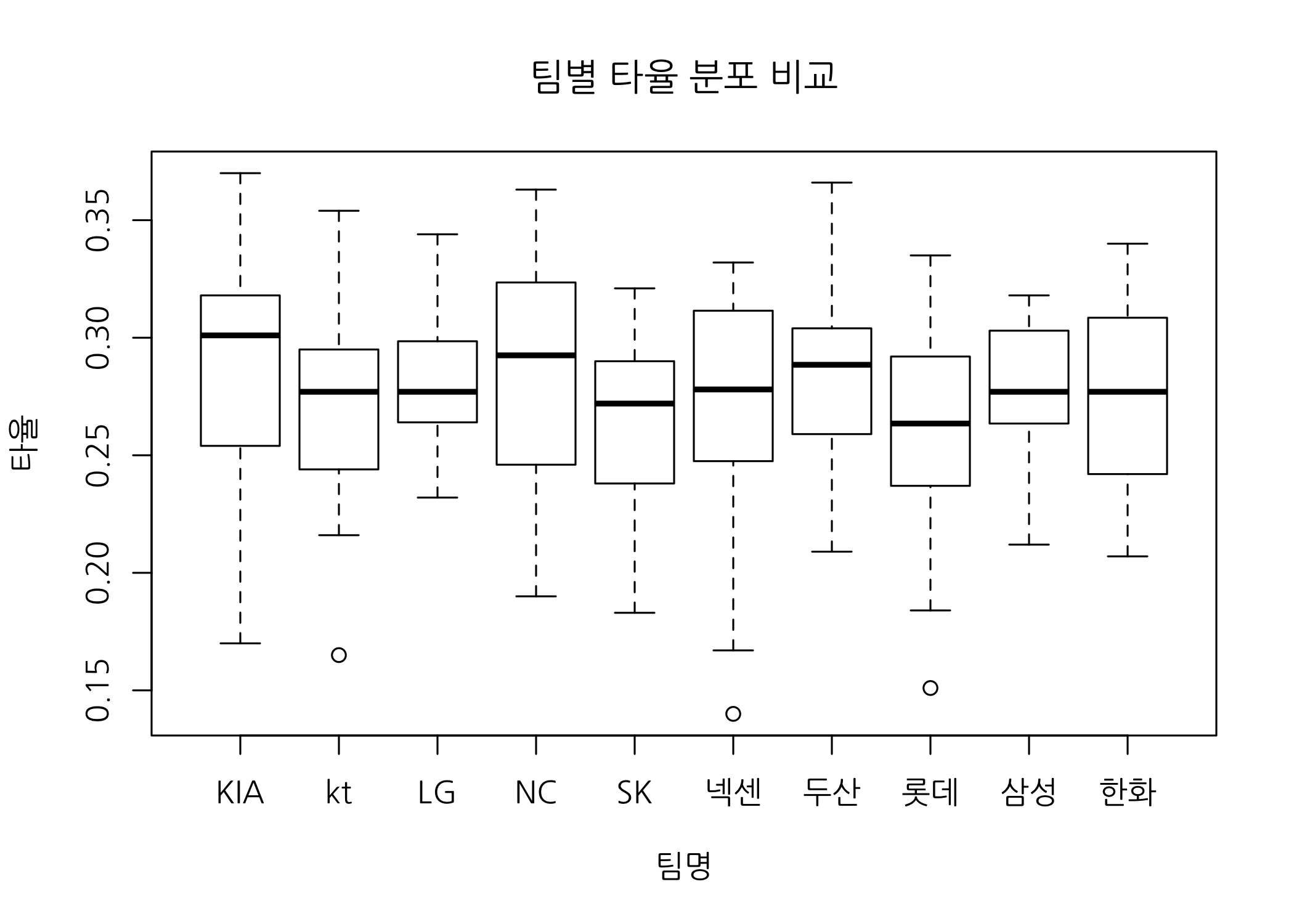
각 팀별로 타율이 아주 뛰어난 (아웃라이어인) 선수는 없는 것으로 보입니다. 그러면 전체에서 가장 타율이 높은 선수가 누구인지 확인해보겠습니다.
# '기아 타이거즈' 선수 중 타율이 가장 높은 선수명을 확인해봅니다.
hitters50 %>%
dplyr::filter(팀명 == 'KIA' & 타율 == max(타율)) %>%
select('선수명')
## # A tibble: 1 x 1
## 선수명
## <chr>
## 1 김선빈
각 팀별 홈런 분포를 확인해보겠습니다. 거포가 즐비한 비룡군단의 분포가 아주 궁금합니다.
# 팀별 홈런 분포를 비교합니다.
boxplot(formula = 홈런 ~ 팀명,
data = hitters50,
xlab = '팀명',
ylab = '홈런',
main = '팀별 홈런 분포 비교')
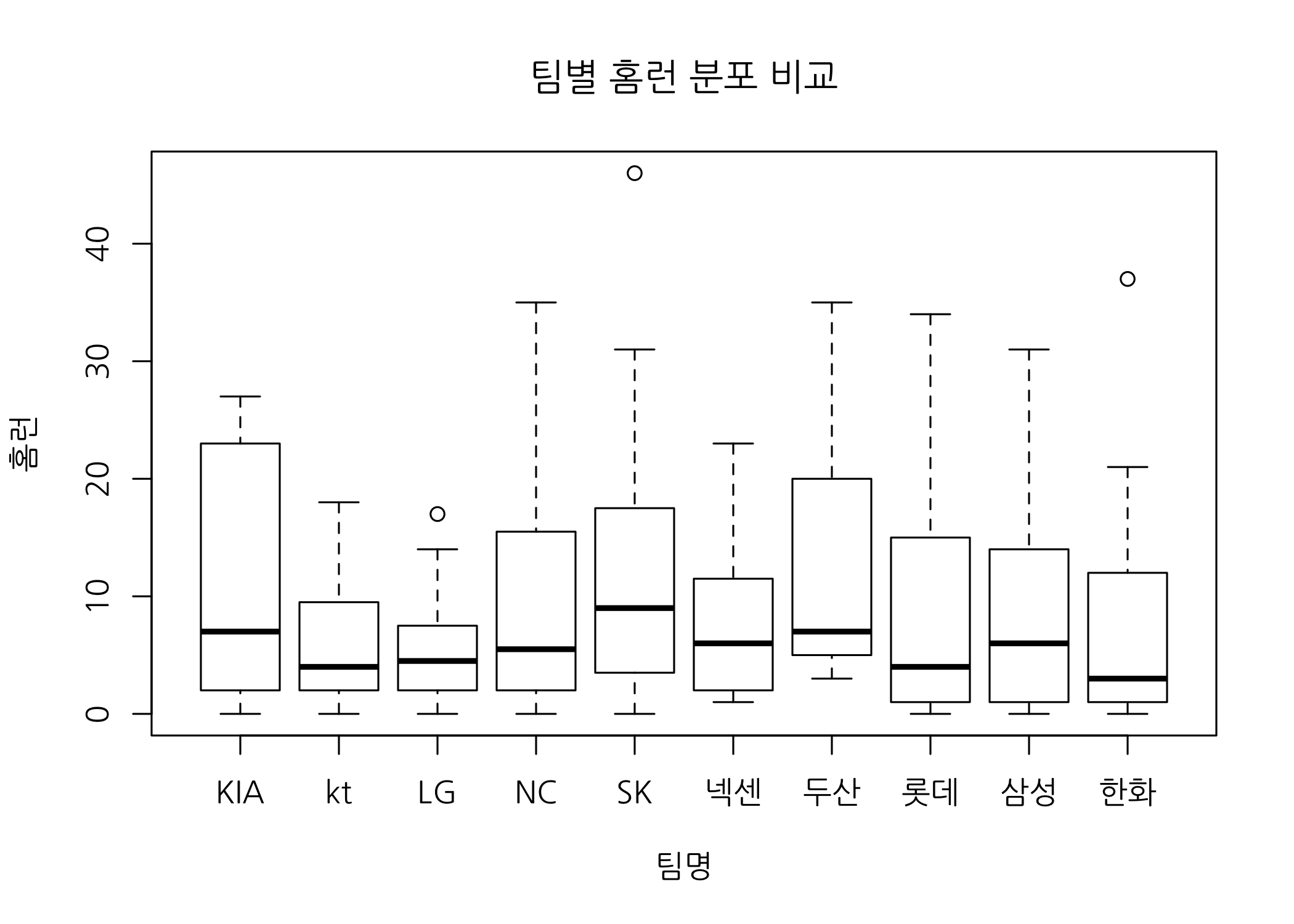
역시 홈런하면 SK 와이번즈입니다. 중위수도 가장 높고 홈런왕도 배출했습니다. 지난해 홈런왕은 누구였을까요?
# 'SK 와이번즈' 선수 중 가장 많은 홈런을 친 선수명을 확인해봅니다.
hitters50 %>%
dplyr::filter(팀명 == 'SK' & 홈런 == max(홈런)) %>%
select('선수명')
## # A tibble: 1 x 1
## 선수명
## <chr>
## 1 최정
안타, 볼넷, 삼진, 도루 등 기본 스탯으로 팀별 분포가 궁금하신 분은 별도로 해보기 바랍니다.
팀별 요약 데이터 만들기
선수 기준으로는 여러 가지로 살펴봤으니 이제는 팀별로 요약 데이터를 만들어서 몇 가지 그래프를 더 그려보도록 하겠습니다. 팀별 요약 데이터를 만드는 데에는 dplyr 패키지의 함수들을 이용하면 편리합니다.
# 관심 있는 선수 스탯을 팀별로 요약하여 새로운 데이터프레임을 만듭니다.
teamStat <- hitters %>%
select(c('팀명', '타석', '타수', '안타', '홈런', '득점', '타점')) %>%
group_by(팀명) %>%
summarize(등록 = n(),
타석 = sum(타석),
타수 = sum(타수),
안타 = sum(안타),
홈런 = sum(홈런),
득점 = sum(득점),
타점 = sum(타점)) %>%
mutate(타율 = round(안타/타수, digits = 3L),
인당안타 = round(안타/등록, digits = 2L),
인당홈런 = round(홈런/등록, digits = 2L),
인당득점 = round(득점/등록, digits = 2L),
인당타점 = round(타점/등록, digits = 2L))
# 데이터의 구조를 파악합니다.
str(object = teamStat)
## Classes 'tbl_df', 'tbl' and 'data.frame': 10 obs. of 13 variables:
## $ 팀명 : Factor w/ 10 levels "KIA","kt","LG",..: 1 2 3 4 5 6 7 8 9 10
## $ 등록 : int 31 28 32 31 25 29 25 26 31 34
## $ 타석 : num 5841 5485 5614 5790 5564 ...
## $ 타수 : num 5142 4937 4944 5079 4925 ...
## $ 안타 : num 1554 1360 1390 1489 1337 ...
## $ 홈런 : num 170 119 110 149 234 141 178 151 145 150
## $ 득점 : num 906 655 699 786 761 789 849 743 757 737
## $ 타점 : num 868 625 663 739 733 748 812 697 703 684
## $ 타율 : num 0.302 0.275 0.281 0.293 0.271 0.29 0.294 0.285 0.279 0.287
## $ 인당안타: num 50.1 48.6 43.4 48 53.5 ...
## $ 인당홈런: num 5.48 4.25 3.44 4.81 9.36 4.86 7.12 5.81 4.68 4.41
## $ 인당득점: num 29.2 23.4 21.8 25.4 30.4 ...
## $ 인당타점: num 28 22.3 20.7 23.8 29.3 ...
새로 만든 팀별 요약 데이터로 몇 가지 그래프를 그려보겠습니다. 먼저 팀타율을 오름차순으로 정렬한 후 산점도를 그려보겠습니다.
# 팀타율을 기준으로 오름차순으로 정렬한 후 재할당합니다.
teamStat <- teamStat[order(teamStat$타율), ]
# 오름차순 산점도를 그려봅니다.
plot(x = teamStat$타율,
ylim = c(0.265, 0.305),
family = 'NanumGothic')
# 팀명을 점 아래에 출력합니다.
text(x = teamStat$타율,
labels = teamStat$팀명,
pos = 1,
family = 'NanumGothic')
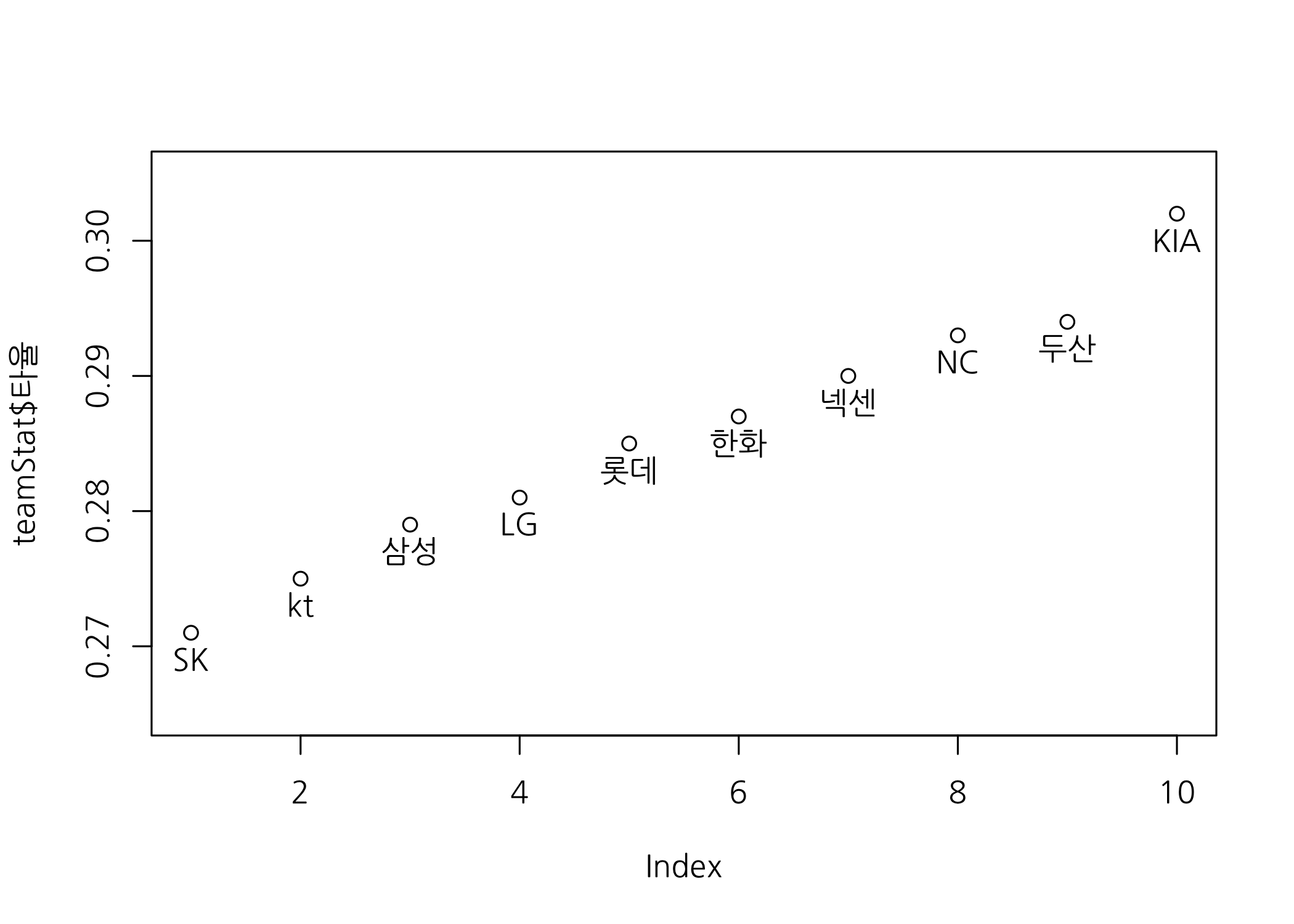
이번에는 팀별 홈련 개수를 막대그래프로 그려서 확인해보겠습니다.
# 팀홈런을 기준으로 오름차순으로 정렬한 후 재할당합니다.
teamStat <- teamStat[order(teamStat$홈런), ]
# 팀홈런 개수로 막대그래프를 그립니다.
# ifelse() 함수를 이용하여 특정 팀의 막대 색상을 바꿀 수 있습니다.
bp <- barplot(height = teamStat$홈런,
names.arg = teamStat$팀명,
border = FALSE,
main = '팀별 홈런 개수 비교',
family = 'NanumGothic',
col = ifelse(test = teamStat$팀명 %in% c('KIA', '두산'),
yes = 'orange',
no = 'gray80'))
# 팀별 홈런 개수를 막대에 출력합니다.
text(x = bp,
y = teamStat$홈런,
labels = teamStat$홈런,
cex = 1,
pos = 1)
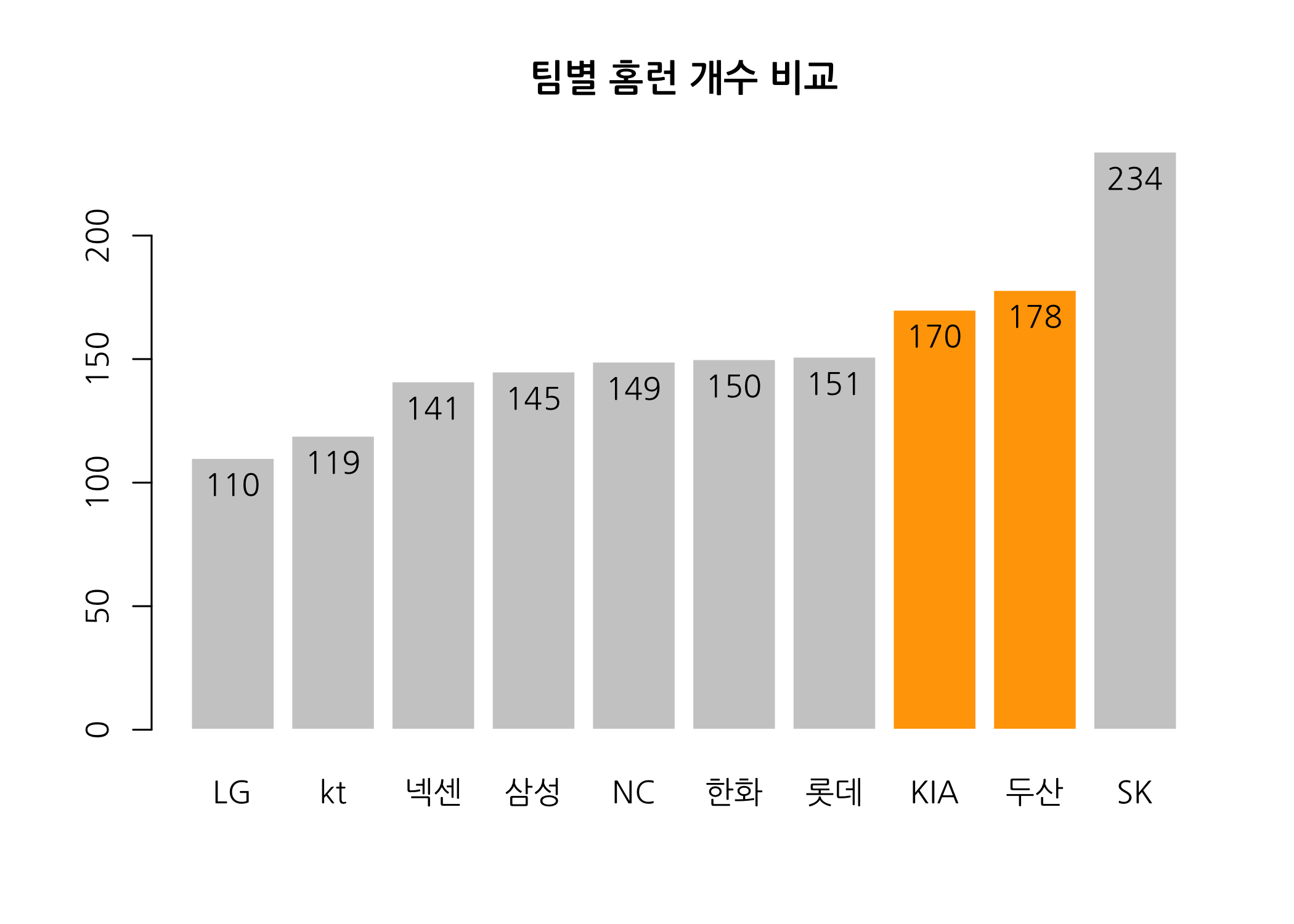
역시 비룡군단입니다. 홈런 개수가 월등히 많네요. 올해도 많은 홈런을 기대해봅니다.
마지막으로 각 팀에 선수 인당 홈런 개수는 얼마나 될까요? 바로 확인해보겠습니다.
# 인당홈런을 기준으로 오름차순으로 정렬한 후 재할당합니다.
teamStat <- teamStat[order(teamStat$인당홈런), ]
# 인당홈런 개수로 막대그래프를 그립니다.
# ifelse() 함수를 이용하여 특정 팀의 막대 색상을 바꿀 수 있습니다.
bp <- barplot(height = teamStat$인당홈런,
names.arg = teamStat$팀명,
border = FALSE,
main = '팀별 인당홈런 개수 비교',
family = 'NanumGothic',
col = ifelse(test = teamStat$팀명 %in% c('KIA', '두산'),
yes = 'orange',
no = 'gray80'))
# 팀별 홈런 개수를 막대에 출력합니다.
text(x = bp, y = teamStat$인당홈런, labels = teamStat$인당홈런, cex = 1, pos = 1)
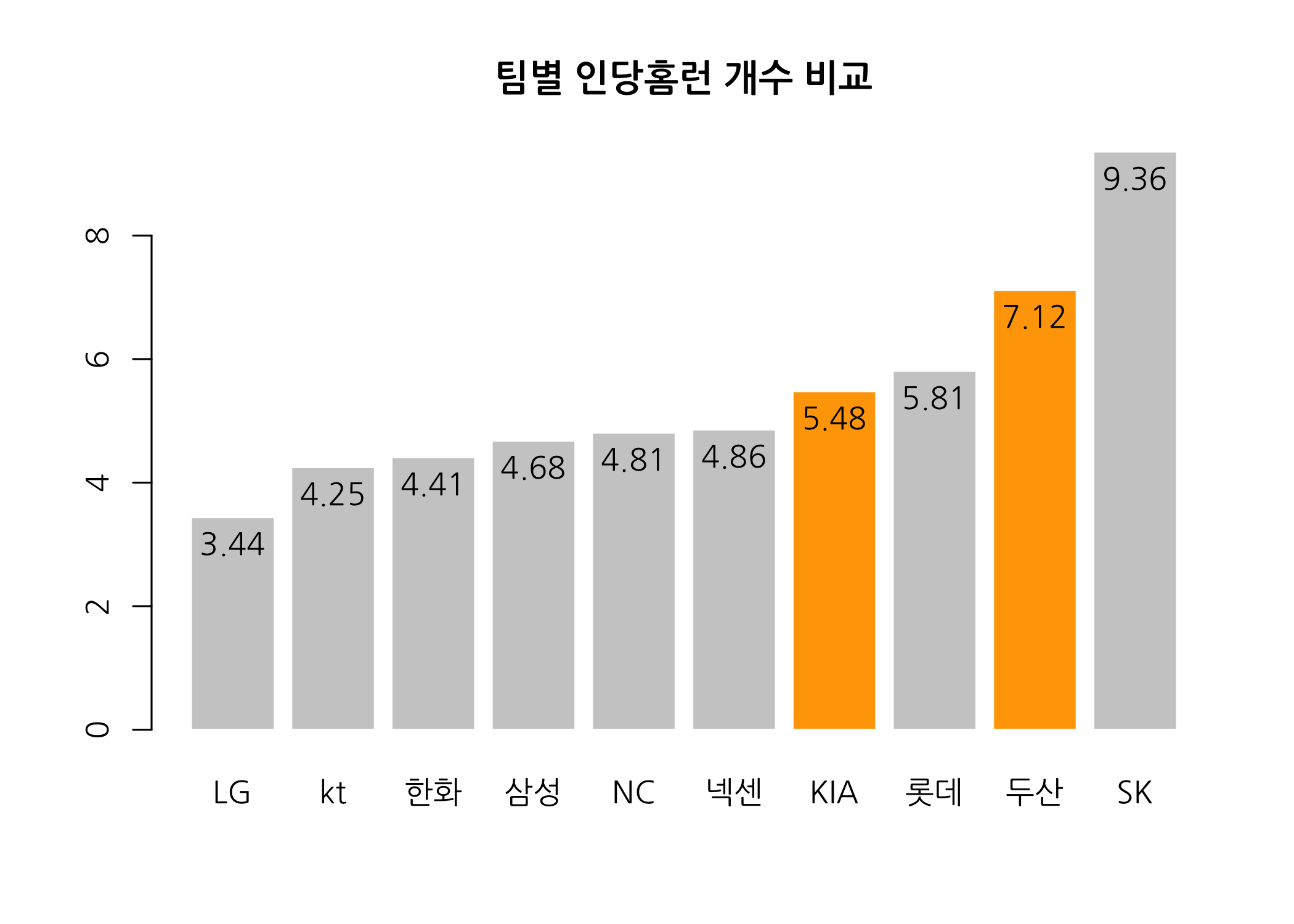
역시 비룡군단입니다. 2위 두산보다 약 2.2개 많고 우승팀 KIA보다는 거의 4개 가까이 많습니다.
이제 길고 긴 이번 포스팅을 여기에서 마무리하도록 하겠습니다. 탐색적 데이터 분석은 정해진 규칙이 따로 없다고 합니다. 데이터 전처리가 어느 정도 완료되면 EDA를 통해 데이터와 친해지는 시간을 갖게 되기도 하구요. 또는 데이터가 제대로 작성되었는지 가늠하는 기회가 되기도 합니다. 다양한 그래프를 그려서 시각화함으로써 텍스트로는 쉽게 발견하지 못했던 인사이트도 얻을 수 있습니다. 데이터 전처리부터 탐색적 데이터 분석까지 지루하고 힘들지만, 이 과정을 즐겨보기 바랍니다.
[1] 이 내용은 리비전컨설팅 전용준 대표님의 탐색적분석R을 사전 승인 받아 재편성한 것이 포함되어 있음을 알려드립니다.
[2] 데이터 전처리를 하다보면 텍스트 데이터를 자유자재로 다루어야 하는 경우가 많습니다. 이와 관련된 내용은 별도의 포스팅에 정리하였으니 관심 있는 분들은 stringr 패키지 주요 함수 소개(추후 별도 포스팅 예정)를 참조하기 바랍니다.
[3] 보다 상세한 내용은 관련 블로그를 참조하기 바랍니다.