기술 통계 간단 정리
이 글은 2018~2019년에 작성한 R 기반 강의 노트를 옮긴 것입니다. 코드 일부는 현재 패키지 버전과 다를 수 있습니다.
R을 활용한 기술통계에 관해 간단하게 살펴보겠습니다.
- [기초 통계량] 최소값, 최대값, 분위수, 중앙값, 평균, 분산, 표준편차 등을 계산합니다.
- [상자수염그림] 기초 통계량을 하나의 그래프로 확인합니다. 상자수염그림을 통해 이상치를 탐지하고 필요 시 제거할 수도 있습니다.
- [도수분포표] 데이터를 일정 구간으로 나누고, 구간별 빈도수와 상대도수 및 누적상대도수를 추가하는 등의 요약 테이블을 생성합니다.
- [히스토그램] 데이터를 일정 구간으로 나눈 빈도수로 분포의 형태를 확인합니다.
- [정규성 검정] 데이터가 정규분포를 따르는지 여부를 확인하는 방법을 알아봅니다.
- [표준화 & 정규화] 척도가 다른 데이터를 같은 척도로 맞추는 방법으로 표준화와 정규화를 실행합니다.
기초 통계량 구하기
- 최소값, 최대값, 범위(최소값, 최대값)
- 중앙값
- 사분위수 : 최소값(0%), 1분위수(25%), 중앙값(50%), 평균, 3분위수(75%), 최대값(100%)
- 사분범위(IQR) : 3분위수와 1분위수 간 차이
- 분산 및 표준편차
기초 통계량 계산 실습을 위해 먼저 임의의 수를 생성하겠습니다. 같은 결과를 재현할 수 있도록 set.seed() 함수를 사용합니다.
# 임의의 수를 생성할 때, 항상 같은 결과를 얻기 위해 set.seed()를 설정합니다.
# 괄호 안 seed에 할당하는 숫자는 분석가가 임의대로 정할 수 있습니다.
set.seed(seed = 123)
# 평균이 0이고, 표준편차가 1인 정규분포를 따르는 임의의 수 1000개를 생성합니다.
x <- rnorm(n = 1000, mean = 0, sd = 1)
이렇게 생성한 객체 x를 이용하여 위에서 언급한 기초 통계량을 하나씩 계산해보겠습니다.
# 최소값은 min() 함수를 이용하여 계산합니다.
cat('최소값 :', x %>% min() %>% round(digits = 3L), '\n')
## 최소값 : -2.81
# 최대값은 max() 함수를 이용하여 계산합니다.
cat('최대값 :', x %>% max() %>% round(digits = 3L), '\n')
## 최대값 : 3.241
# 범위는 최소값과 최대값을 한 번에 출력해줍니다. range() 함수를 이용합니다.
cat('범 위 :', x %>% range() %>% round(digits = 3L), '\n')
## 범 위 : -2.81 3.241
# 중앙값은 전체 자료의 50%에 위치하는 값입니다. median() 함수를 이용합니다.
cat('중앙값 :', x %>% median() %>% round(digits = 3L), '\n')
## 중앙값 : 0.009
# 평균은 mean() 함수를 이용하여 계산합니다.
cat('평 균 :', x %>% mean() %>% round(digits = 3L), '\n')
## 평 균 : 0.016
사분위수는 전체 데이터를 정확하게 4등분하는 지점에 위치한 값입니다. 따라서 1분위수(25%), 중앙값(50%), 3분위수(75%) 등 3가지 값으로 구성되어 있습니다. R에서는 quantile() 함수를 이용하여 쉽게 구할 수 있습니다. quantile() 함수의 probs 인자에는 기본값으로 seq(0, 1, 0.25)이 할당되므로 3개의 4분위수와 함께 최소값, 최대값이 출력되지만, probs 인자에 분석가가 원하는 값을 지정할 수 있습니다.
# 사분위수는 quantile() 함수를 이용하여 계산합니다.
cat('사분위수 :', x %>% quantile() %>% round(digits = 3L), '\n')
## 사분위수 : -2.81 -0.628 0.009 0.665 3.241
앞에서 언급한 바와 같이 quantile() 함수의 probs 인자에 분석가가 0에서 1 사이의 임의의 값을 할당하면 원하는 위치의 값을 얻을 수 있습니다.
# 임의의 자리에 위치한 값을 얻을 수 얻을 수 있습니다.
x %>%
quantile(probs = c(0, 0.05, 0.1, 0.9, 0.95, 1)) %>%
round(digits = 3L) %>%
print()
## 0% 5% 10% 90% 95% 100%
## -2.810 -1.623 -1.267 1.255 1.676 3.241
지금까지 살펴본 기초 통계량을 개별 함수로 구하는 대신 summary() 함수를 이용하면 숫자형 데이터의 요약 통계량들을 한 번에 확인할 수 있습니다. 문자형 데이터는 벡터의 크기(length)와 속성(Class와 Mode)를, 범주형 데이터는 빈도수를 각각 출력합니다.
# 숫자형 데이터의 요약 통계량을 간단하게 확인할 수 있습니다.
summary(object = x)
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## -2.80978 -0.62832 0.00921 0.01613 0.66460 3.24104
이번에는 분산과 표준편차를 구하는 방법을 알아보겠습니다. 분산과 표준편차는 데이터가 얼마나 퍼져 있는지를 알아보기 위해 사용합니다. 모수의 분산은 개별 x값에서 x의 평균을 뺀 값을 제곱하여 모두 더한 후 데이터의 수(n)로 나눠준 값이며, 표준편차는 분산의 양의 제곱근입니다. 한 가지 유의해야 할 점은 표본의 분산은 n이 아닌 n-1로 나눈다는 것입니다. var() 함수는 표본의 본산을 구하는 함수입니다. 물론 n이 커질수록 모분산과 표본분산은 거의 같아지게 됩니다.
# 분산을 계산합니다.
cat('분산 :', x %>% var() %>% round(digits = 4L), '\n')
## 분산 : 0.9835
# 표준편차를 계산합니다.
cat('표준편차 :', x %>% sd() %>% round(digits = 4L), '\n')
## 표준편차 : 0.9917
위에서 열거한 기초 통계량을 한 번에 확인할 수 있도록 사용자 정의 함수로 만들어 보겠습니다. 그리고 임의의 수를 생성하여 사용자 정의 함수에 할당하여 실행해보겠습니다.
# 기초 통계량을 반환하는 사용자 정의 함수를 생성합니다.
myStats <- function(obj) {
cat('최소값 :', obj %>% min() %>% round(digits = 3L), '\n')
cat('1분위수 :', obj %>% quantile() %>% `[`(2) %>% round(digits = 3L), '\n')
cat('중앙값 :', obj %>% median() %>% round(digits = 3L), '\n')
cat('평 균 :', obj %>% mean() %>% round(digits = 3L), '\n')
cat('3분위수 :', obj %>% quantile() %>% `[`(4) %>% round(digits = 3L), '\n')
cat('최대값 :', obj %>% max() %>% round(digits = 3L), '\n')
cat('분 산 :', obj %>% var() %>% round(digits = 4L), '\n')
cat('표준편차 :', obj %>% sd() %>% round(digits = 4L), '\n')
}
# set.seed()를 설정합니다.
set.seed(seed = 123)
# 평균이 10이고, 표준편차가 5인 정규분포를 따르는 임의의 수 100개를 생성합니다.
y <- rnorm(n = 100, mean = 10, sd = 5)
# 사용자 정의 함수에 y를 할당하고 실행합니다.
myStats(y)
## 최소값 : -1.546
## 1분위수 : 7.531
## 중앙값 : 10.309
## 평 균 : 10.452
## 3분위수 : 13.459
## 최대값 : 20.937
## 분 산 : 20.8308
## 표준편차 : 4.5641
다양한 기술 통계량을 한 번에 확인할 수 있는 함수가 있어 소개해드립니다.
# [참고] 숫자형 데이터의 기술(descriptive) 통계량을 한 번에 확인할 수 있습니다.
psych::describe(x = x)
## vars n mean sd median trimmed mad min max range skew kurtosis
## X1 1 1000 0.02 0.99 0.01 0.01 0.96 -2.81 3.24 6.05 0.07 -0.08
## se
## X1 0.03
상자수염그림 (Box plot)
상자수염그림은 숫자형 데이터의 분포를 한 눈에 알아볼 수 있도록 하는 그래프 중 하나입니다. 상자수염그림에는 데이터의 최소값, 1분위수, 중위수, 3분위수, 최대값의 위치를 쉽게 알아볼 수 있도록 표시되어 있으며, 이상치도 함께 확인할 수 있습니다.

# 상자수염그림을 그립니다.
boxplot(x = x)
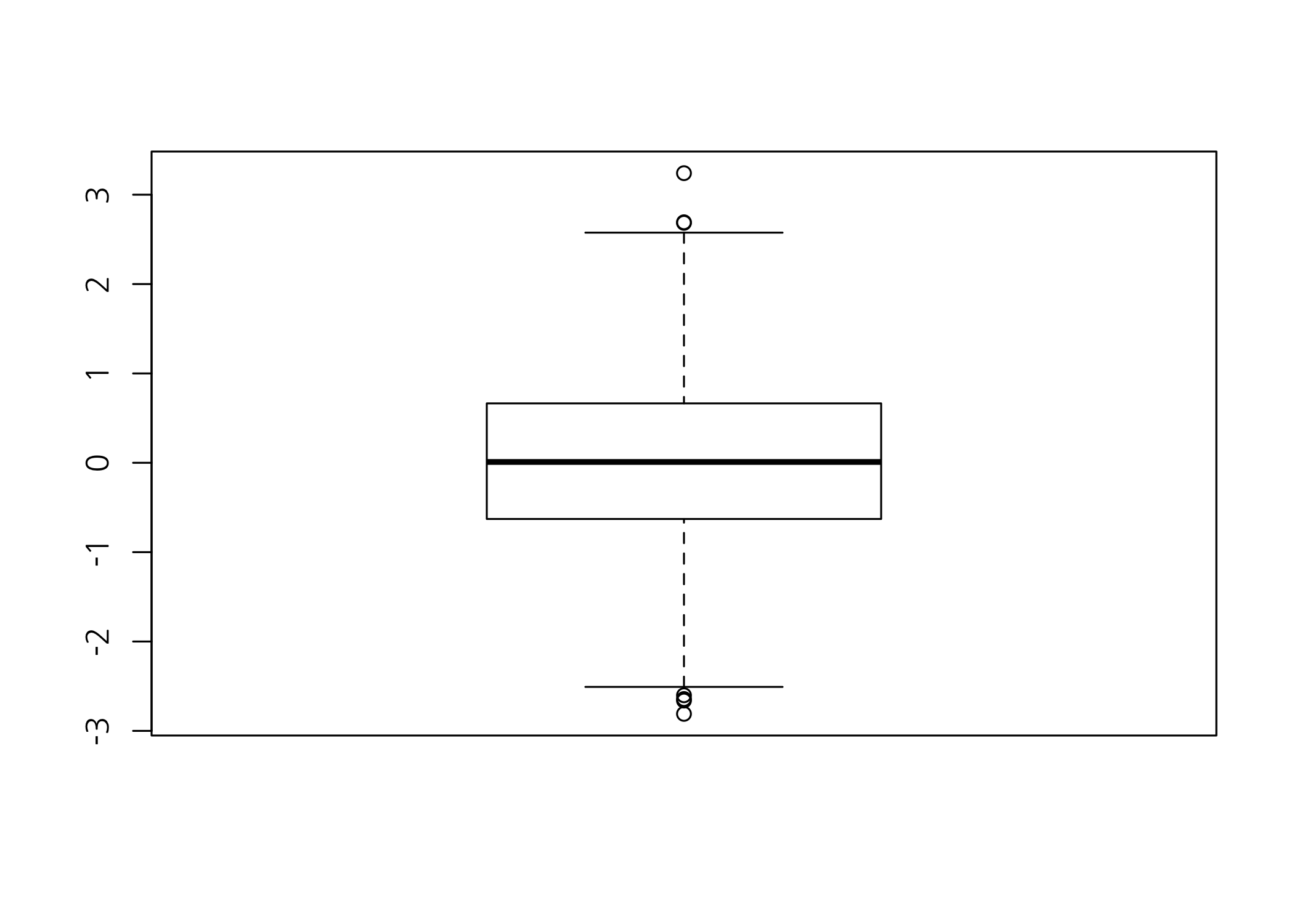
상자수염그림에서 위 아래에 작은 동그라미로 출력된 점들이 몇 개 보입니다. 사분범위수(interquantile range, IQR) 기준에서 볼 때 이상치(outlier)인 경우, 이렇게 작은 동그라미로 출력됩니다. IQR은 1분위수와 3분위수 사이의 범위를 의미합니다. 이상치는 1분위수에서 IQR의 1.5배보다 작은 값과 3분위수에서 IQR의 1.5배보다 큰 값으로 정할 수 있습니다.
# 사분범위수(IQR)를 계산합니다.
iqr <- IQR(x = x)
print(iqr)
## [1] 1.292926
# 사분위수를 계산합니다.
qunt <- quantile(x = x)
print(qunt)
## 0% 25% 50% 75% 100%
## -2.809774679 -0.628324243 0.009209639 0.664601867 3.241039935
# 1분위수에서 IQR의 1.5배 낮은 값과 3분위수에서 IQR의 1.5배 높은 값을 각각 구합니다.
lowerLimit <- qunt[2] - iqr * 1.5
upperLimit <- qunt[4] + iqr * 1.5
cat('이상치 기준점 1 :', lowerLimit, '\n')
## 이상치 기준점 1 : -2.567713
cat('이상치 기준점 2 :', upperLimit, '\n')
## 이상치 기준점 2 : 2.603991
# 이상치로 판정된 값을 출력합니다.
# 데이터에 속한 개별값이 아래 조건식을 만족하면 값들을 출력됩니다.
x[x < lowerLimit | x > upperLimit]
## [1] 3.241040 -2.643149 -2.660923 -2.809775 -2.601700 2.691714 2.684859
# 데이터에서 이상치로 판정된 값들의 위치를 출력합니다.
loc <- which(x < lowerLimit | x > upperLimit)
print(loc)
## [1] 164 416 456 591 616 747 842
# 데이터에서 이상치로 판정된 값들을 모두 NA로 변경합니다.
x[loc] <- NA
제대로 변경되었는지 여부는 print(x)를 실행하여 직접 육안으로 확인해보시기 바랍니다.
이제 데이터에 있는 이상치를 삭제하겠습니다. 데이터에 속한 NA를 제거해주는 방법을 2가지 소개하겠습니다. complete.cases() 함수와 is.na() 함수를 사용하는 방법이 있습니다. 편의에 따라 사용하시면 됩니다.
# complete.cases()를 이용하여 NA를 제거하고 길이를 확인합니다.
x1 <- x[complete.cases(x)]
length(x1)
## [1] 993
# is.na()를 사용하여 NA를 제거하고 길이를 확인합니다.
x2 <- x[is.na(x) == FALSE]
length(x2)
## [1] 993
# 두 객체의 교집합의 길이를 확인합니다.
identical(x = x1, y = x2)
## [1] TRUE
# 만약 두 객체가 정확하게 겹친다면 교집합의 길이는 x1 또는 x2와 같게 됩니다.
intersect(x = x1, y = x2) %>% length()
## [1] 993
이상치를 탐지하는 더 쉬운 방법은 boxplot.stats() 함수를 이용하는 것입니다.
# x 벡터를 재생성합니다.
set.seed(seed = 123)
x <- rnorm(n = 1000, mean = 0, sd = 1)
# boxplot.stats() 함수는 리스트 객체를 반환하며 'out'에 이상치 값을 할당합니다.
boxplot.stats(x = x)
## $stats
## [1] -2.507917802 -0.628742409 0.009209639 0.664787870 2.575449764
##
## $n
## [1] 1000
##
## $conf
## [1] -0.05542029 0.07383957
##
## $out
## [1] 3.241040 -2.643149 -2.660923 -2.809775 -2.601700 2.691714 2.684859
# 이상치를 NA로 변경한 후 삭제합니다.
x[x %in% boxplot.stats(x)$out] <- NA
x <- x[complete.cases(x)]
length(x = x)
## [1] 993
상자수염그림에서 이상치를 탐지하는 것과 관련하여 주의해야 할 사항으로는, 이 방법이 이상치를 판단하는 일반적인 방법이 아니며 이상치라고 해서 분석하기 전에 모두 제거해야 하는 것도 아닙니다. 아울러 데이터의 특성에 따라 이상치를 판별하는 기준이 서로 다를 수 있다는 것입니다.
도수분포표 만들기
숫자형 데이터를 요약하여 정보를 추출하는 방법으로 도수분포표를 만들어볼 수 있습니다. 도수분포표를 만드는 순서는 다음과 같습니다.
- 데이터의 범위(최소값과 최대값)를 확인합니다.
- 전체 데이터를 몇 개의 구간(계급)으로 나눌지 정합니다. 계급의 크기에 따라 간격을 정할 수 있으며, 반대로 하는 경우도 있습니다.
- 각 구간에 속하는 데이터의 개수(빈도수)를 구합니다.
- 빈도수 데이터로 상대도수와 누적상대도수를 계산하여 추가합니다.
- 빈도수와 상대도수, 누적상대도수의 합계를 계산하여 추가합니다.
# 가상의 몸무게 데이터를 만듭니다.
set.seed(seed = 123)
weights <- rnorm(n = 100, mean = 70, sd = 10) %>% round(digits = 1L)
# 새로 생성한 데이터의 기초 통계량을 확인합니다.
myStats(weights)
## 최소값 : 46.9
## 1분위수 : 65.075
## 중앙값 : 70.6
## 평 균 : 70.901
## 3분위수 : 76.925
## 최대값 : 91.9
## 분 산 : 83.4858
## 표준편차 : 9.1371
# 5kg 단위로 설정된 구간을 할당합니다.
# 이때, 최소값과 최대값을 포함하도록 합니다.
# Hmisc::cut2() 함수의 minmax 인자로 최소값 또는 최대값을 포함할지 여부를 지정합니다.
cuts <- Hmisc::cut2(x = weights,
cuts = seq(from = 45, to = 95, by = 5),
minmax = TRUE)
# 빈도수를 구합니다.
freq <- table(cuts)
print(freq)
## cuts
## [45,50) [50,55) [55,60) [60,65) [65,70) [70,75) [75,80) [80,85) [85,90)
## 1 3 10 10 24 21 14 9 5
## [90,95]
## 3
# 각 구간별 상대도수를 구한 후, 도수분포표에 추가합니다.
relFreq <- prop.table(x = freq)
freq <- rbind(freq, relFreq)
print(freq)
## [45,50) [50,55) [55,60) [60,65) [65,70) [70,75) [75,80) [80,85)
## freq 1.00 3.00 10.0 10.0 24.00 21.00 14.00 9.00
## relFreq 0.01 0.03 0.1 0.1 0.24 0.21 0.14 0.09
## [85,90) [90,95]
## freq 5.00 3.00
## relFreq 0.05 0.03
# 각 구간별 누적상대도수를 구한 후, 도수분포표에 추가합니다.
cumFreq <- cumsum(x = relFreq)
freq <- rbind(freq, cumFreq)
print(freq)
## [45,50) [50,55) [55,60) [60,65) [65,70) [70,75) [75,80) [80,85)
## freq 1.00 3.00 10.00 10.00 24.00 21.00 14.00 9.00
## relFreq 0.01 0.03 0.10 0.10 0.24 0.21 0.14 0.09
## cumFreq 0.01 0.04 0.14 0.24 0.48 0.69 0.83 0.92
## [85,90) [90,95]
## freq 5.00 3.00
## relFreq 0.05 0.03
## cumFreq 0.97 1.00
# 행별 합계를 구한 후, 도수분포표에 추가합니다.
# margin = 1이면 열 기준으로 FUN에 할당된 함수를 적용합니다.
freq <- addmargins(A = freq, margin = 2, FUN = sum)
print(freq)
## [45,50) [50,55) [55,60) [60,65) [65,70) [70,75) [75,80) [80,85)
## freq 1.00 3.00 10.00 10.00 24.00 21.00 14.00 9.00
## relFreq 0.01 0.03 0.10 0.10 0.24 0.21 0.14 0.09
## cumFreq 0.01 0.04 0.14 0.24 0.48 0.69 0.83 0.92
## [85,90) [90,95] sum
## freq 5.00 3.00 100.00
## relFreq 0.05 0.03 1.00
## cumFreq 0.97 1.00 5.32
# 행과 열의 이름을 변경합니다.
rownames(freq) <- c('빈도수(명)', '상대도수(%)', '누적상대도수(%)')
colnames(freq) <- c('45~50kg', '50~55kg', '55~60kg', '60~65kg', '65~70kg',
'70~75kg', '75~80kg', '80~85kg', '85~90kg', '90kg이상', '합계')
print(freq)
## 45~50kg 50~55kg 55~60kg 60~65kg 65~70kg 70~75kg 75~80kg
## 빈도수(명) 1.00 3.00 10.00 10.00 24.00 21.00 14.00
## 상대도수(%) 0.01 0.03 0.10 0.10 0.24 0.21 0.14
## 누적상대도수(%) 0.01 0.04 0.14 0.24 0.48 0.69 0.83
## 80~85kg 85~90kg 90kg이상 합계
## 빈도수(명) 9.00 5.00 3.00 100.00
## 상대도수(%) 0.09 0.05 0.03 1.00
## 누적상대도수(%) 0.92 0.97 1.00 5.32
히스토그램 그리기 (Histogram)
히스토그램은 데이터를 일정구간으로 나눈 후 얻은 빈도수를 그래프로 그린 것입니다. 따라서 히스토그램을 그려보면 분석하려는 데이터가 어떤 분포를 갖는지 시각적으로 확인할 수 있습니다. hist() 함수를 사용하면 쉽게 히스토그램을 그릴 수 있습니다. hist() 함수의 인자들을 사용하여 분석가가 원하는 히스토그램을 그리는 방법을 알아보겠습니다.
# R studio에서 한글이 깨지지 않도록 R에 등록된 한글폰트를 지정합니다.
# R에 한글폰트를 등록하는 방법은 아래 링크를 참조하시기 바랍니다.
# [참조] 'https://youngbin90.blogspot.kr/2016/03/r-plot.html'
par(family = 'NanumGothic')
# 그래프 출력 화면을 2행 * 2열로 나눕니다.
par(mfrow = c(2, 2))
# 먼저 기본형 히스토그램을 그립니다.
hist(x = x)
# y축에 빈도수 대신 상대도수로 바꿉니다. (freq = FALSE)
# 막대의 개수를 30개로 늘립니다. (breaks = 30)
# 막대 채우기 색을 회색으로 변경합니다. (col = 'gray50')
# 막대 테두리 색을 흰색으로 변경합니다. (border = 'white')
hist(x = x,
freq = FALSE,
breaks = 30,
col = 'gray50',
border = 'white')
# 빈도수를 출력합니다. (labels = TRUE)
# y축의 범위를 변경합니다. (ylim = c(0, 0.45))
hist(x = x,
freq = FALSE,
breaks = 30,
col = 'gray50',
border = 'white',
labels = TRUE,
ylim = c(0, 0.45))
# x축과 y축 이름을 변경합니다. (xlab = '데이터', ylab = '상대도수')
# 제목을 추가합니다. (main = '히스토그램 그리기')
# 한글 폰트를 지정합니다. (family = 'NanumGothic')
hist(x = x,
freq = FALSE,
breaks = 30,
col = 'gray50',
border = 'white',
labels = TRUE,
ylim = c(0, 0.45),
xlab = '데이터',
ylab = '상대도수',
main = '히스토그램 그리기',
family = 'NanumGothic')
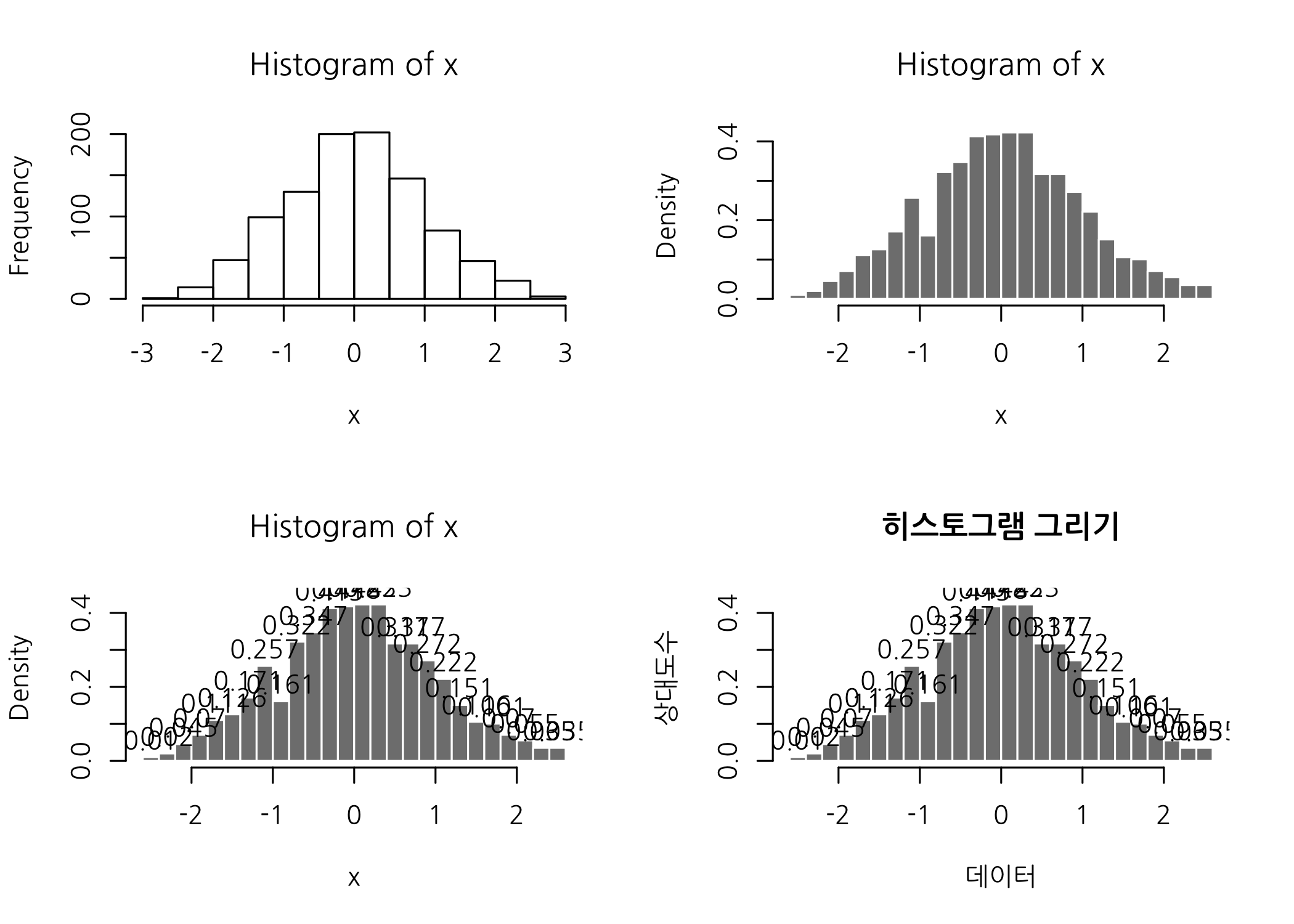
# 그래프 출력 화면을 1행 * 1열로 돌려놓습니다.
par(mfrow = c(1, 1))
정규성 테스트
회귀분석 같은 알고리즘의 경우, 종속변수나 오차에 대해 정규분포를 가정하고 있으므로 분석 모델링을 하기에 앞서 데이터의 분포를 확인할 필요가 있습니다. 데이터의 정규성을 그래프로 확인하는 방법과 통계적 유의성을 검정하는 방법을 차례로 소개합니다.
그래프로 확인하는 방법
자료의 정규성을 그래프로 확인하는 방법은 방금 살펴본 히스토그램 외에 Normal QQ-Plot 등을 그려보는 방법이 있습니다. 먼저 히스토그램에 확률밀도함수를 추가하는 방법을 소개하겠습니다.
# 히스토그램을 그려 x의 분포를 확인합니다.
hist(x = x,
breaks = 10,
probability = TRUE,
main = '히스토그램 예제',
family = 'NanumGothic')
# 히스트그램 위에 x의 확률밀도함수를 추가합니다.
lines(x = density(x), col = 'red')
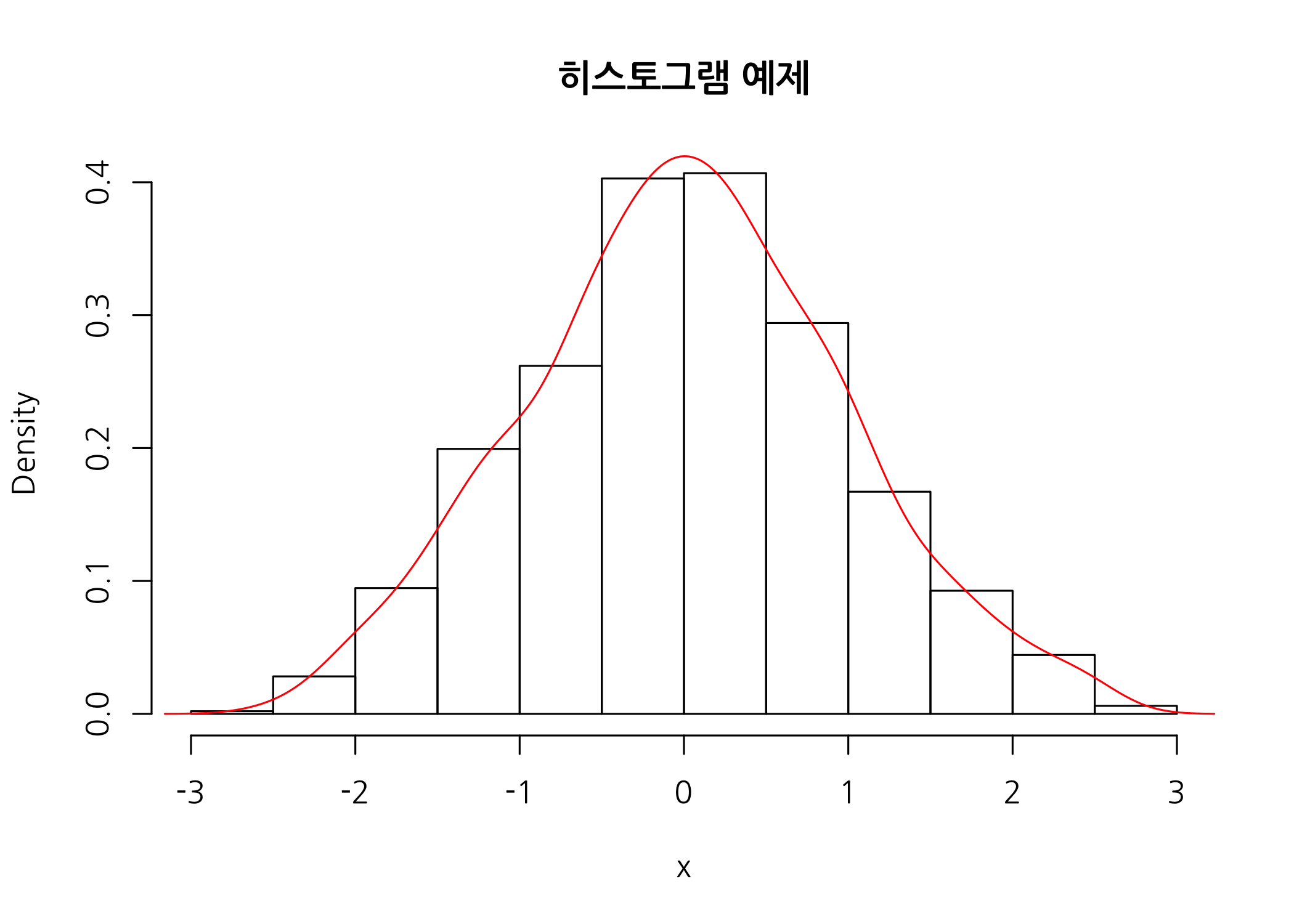
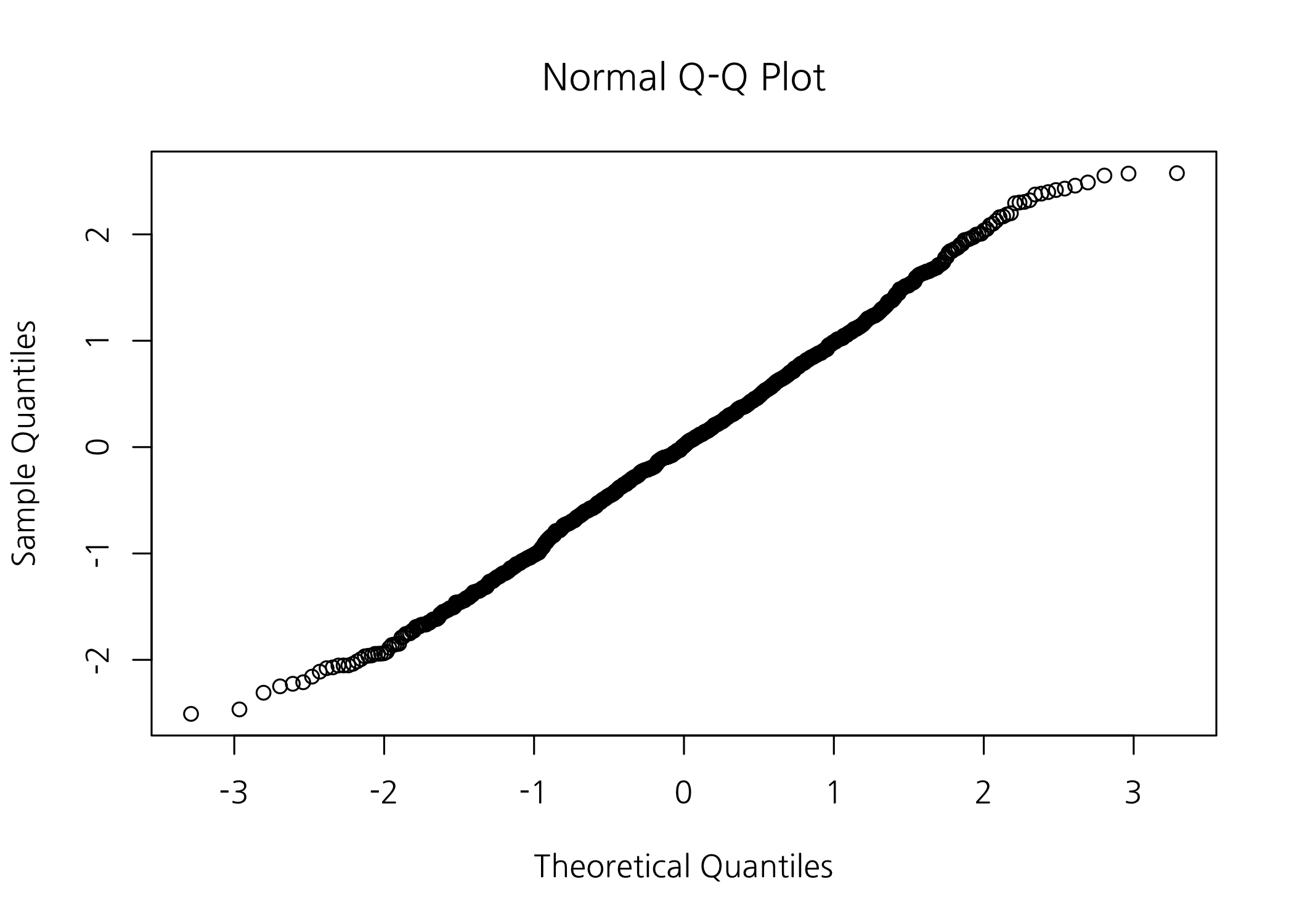
이번에는 Normal QQ-plot을 그려보겠습니다. QQ-plot의 Q는 ‘qauntiles’에서 온 것입니다. 숫자형 데이터를 최소값부터 최대값까지 오름차순으로 정렬한 후, 일정한 간격에 위치한 값들을 2차원 평면에 그린 것입니다. 만약 두 개의 숫자형 데이터(확률분포)가 같은 분포를 갖는다면, 각각의 quantiles 값들을 구해 2차원 평면에 그렸을 때 직선으로 그려집니다. 하나의 숫자형 데이터로 QQ-plot을 그려도 마찬가지입니다.
# QQ-plot이 직선인 경우, 정규분포를 가정할 수 있습니다.
qqnorm(y = x)
통계적 유의성 검정 방법
이번에는 통계적 유의성 검정 방법인 Shapiro-Wilk 테스트와 Anderson-Darling 테스트를 통해 데이터의 정규성을 확인하는 방법을 알아보겠습니다. 유의해야 할 점은, 이 두 가지 검정의 귀무가설은 데이터가 정규분포한다입니다. 따라서 p-value가 0.05보다 작으면 95% 유의수준 하에서 귀무가설을 기각할 수 있으며, 데이터가 정규분포한다고 할 수 없다가 됩니다. 즉, 데이터가 정규분포한다고 가정하려면 p-value가 0.05보다 커야 합니다.
# Shapiro-Wilk 검정을 실시합니다.
library(stats)
shapiro.test(x = x)
##
## Shapiro-Wilk normality test
##
## data: x
## W = 0.99675, p-value = 0.03922
# Anderson-Darling 검정을 실시합니다.
library(nortest)
ad.test(x = x)
##
## Anderson-Darling normality test
##
## data: x
## A = 0.319, p-value = 0.5344
이번 예제를 위해 임의로 생성한 x 데이터로 두 가지 검증을 실시한 결과, p-value가 모두 0.05보다 크다는 것을 확인할 수 있습니다. 따라서 귀무가설을 기각할 수 없으며 x는 정규분포한다고 가정할 수 있습니다.
첨도(Kurtosis)와 왜도(Skewness) 확인
데이터가 정규분포를 따르면 확률밀도함수는 종모양으로 그려집니다. 이 때, 중심이 뾰족한 정도는 첨도이며, 꼬리가 한 쪽으로 치우친 비대칭 정도는 왜도가 됩니다. 아래에 제시한 함수로 첨도와 왜도를 계산할 수 있습니다. 첨도와 왜도가 0에 가까울수록 정규분포로 가정할 수 있습니다.
# 첨도와 왜도를 계산하기 위해 필요 패키지를 불러옵니다.
library(e1071)
# 첨도를 계산합니다.
# 첨도는 0보다 작으면 완만하고, 0보다 크면 뾰족한 모양을 갖습니다.
kurtosis(x = x)
## [1] -0.2410042
# 왜도를 계산합니다.
# 왜도는 0보다 작으면 왼쪽 꼬리가 길고, 0보다 크면 오른쪽 꼬리가 긴 모양을 갖습니다.
skewness(x = x)
## [1] 0.07135012
표준화 vs 정규화
표준화(Standardization)와 정규화(Normalization)는 숫자형 데이터가 일정한 분포를 갖도록 변환하는 것을 의미합니다. 척도가 서로 다른 2개 이상의 숫자형 데이터를 그대로 사용하면 분석 모형이 각각의 척도에 영향을 받게 됩니다. 또한 인공신경망의 경우 입력값이 0~1 사이의 값으로 요구하는 경우에는 반드시 정규화를 해주어야 합니다. 표준화는 평균과 표준편차를 이용하여 변환하며, 표준화된 데이터(Z)는 -Inf과 Inf 사이의 값을 가집니다. 아래는 표준화된 데이터(Z)를 계산하는 공식입니다. 정규분포의 표준화와 같습니다. x는 원본 데이터, μ는 x의 평균이며, σ는 x의 표준편차입니다.
\(Z = \\frac {x - \\mu} \\sigma\)
정규화는 모든 데이터가 0과 1 사이의 값을 갖도록 조정하는 것을 의미하며, 다양한 방법이 있으나 주로 최소값과 최대값을 이용하여 변환합니다. 정규화 공식은 아래와 같습니다. x는 원본 데이터, min은 x의 최소값이며, max는 x의 최대값입니다.
\(x\_{new} = \\frac {x - min} {max - min}\)
R에서 표준화와 정규화를 할 때, scale() 함수를 사용하면 손쉽게 해결할 수 있습니다.
# set.seed()를 지정합니다.
set.seed(seed = 123)
# 1부터 1000의 값을 가지는 숫자형 벡터를 만들고,
# 그 중 500개를 임의로 선택하여 a 객체에 할당합니다.
a <- sample(x = 1:1000, size = 500, replace = FALSE)
myStats(a)
## 최소값 : 1
## 1분위수 : 228.75
## 중앙값 : 476
## 평 균 : 486.138
## 3분위수 : 728.5
## 최대값 : 998
## 분 산 : 84491.97
## 표준편차 : 290.675
# 평균이 0이고, 표준편차가 1인 데이터로 표준화합니다.
scaled1 <- scale(x = a, center = mean(a), scale = sd(a))
myStats(scaled1)
## 최소값 : -1.669
## 1분위수 : -0.885
## 중앙값 : -0.035
## 평 균 : 0
## 3분위수 : 0.834
## 최대값 : 1.761
## 분 산 : 1
## 표준편차 : 1
# 최소값이 0, 최대값이 1인 데이터로 정규화합니다.
scaled2 <- scale(x = a, center = min(a), scale = (max(a) - min(a)))
myStats(scaled2)
## 최소값 : 0
## 1분위수 : 0.228
## 중앙값 : 0.476
## 평 균 : 0.487
## 3분위수 : 0.73
## 최대값 : 1
## 분 산 : 0.085
## 표준편차 : 0.2915
[1] 참조 : http://analyticsstory.com/72