기계학습 알고리즘의 종류와 데이터셋 분할
이 글은 2018~2019년에 작성한 R 기반 강의 노트를 옮긴 것입니다. 코드 일부는 현재 패키지 버전과 다를 수 있습니다.
이번 포스팅부터 기계학습 알고리즘을 소개해드리겠습니다. 기계학습 모형은 목표변수(Target Variable)의 유무에 따라서 지도학습(Supervised Learning)과 비지도학습(Unsupervised Learning)으로 나뉩니다. 제가 간략하게 그린 그림을 보여드리겠습니다.
기계학습 알고리즘의 종류
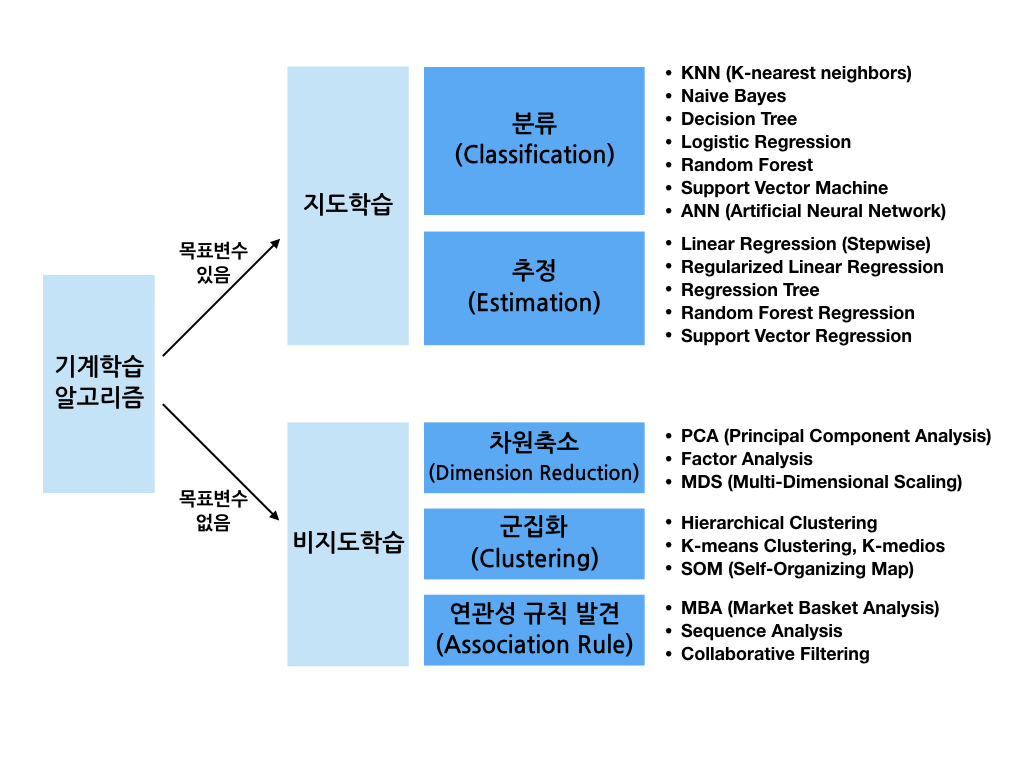
지도학습은 목표변수의 종류에 따라서 분류(Classification)와 추정(Estimation)으로 나뉘는데요. 추정은 회귀(Regression)와 혼용해서 언급되기도 합니다. 분류모형은 목표변수가 범주형일 때 사용되며, 추정(회귀)모형은 목표변수가 연속형일 때 사용됩니다. 그리고 입력변수들과 목표변수가 같은 시점일 때는 추정모형이지만, 목표변수가 입력변수보다 미래시점일 때는 예측(Prediction)모형이 됩니다.
비지도학습은 목표변수가 없다는 특징이 있습니다. 차원축소(Dimension Reduction)는 p개의 (입력)변수를 p보다 작은 m개로 줄여서 다른 알고리즘을 적용할 때 사용하며, 군집화(Clustering)는 전체 데이터를 몇 개의 세부 군집으로 나눌 때 사용합니다. 연관성 규칙(Association Rule)은 장바구니 분석(MBA, Market Basket Analysis)처럼 서로 연관성 높은 규칙을 발견할 때 사용합니다.
우리가 해결하고자 하는 문제와 가지고 있는 데이터의 속성에 따라 어떤 알고리즘을 사용해야 하는지를 정하는 것이 중요합니다. 맨 오른쪽에 보이는 알고리즘들의 대부분을 이 블로그에서 다룰텐데요. 다만 실제 회사에서 다루는 데이터를 사용하기 어려우므로 R 또는 온라인에서 제공되는 데이터 및 크롤링을 통해 수집한 데이터를 사용하여 간략한 원리와 코드로 직접 구현해보는 것으로 만족해야 할 것입니다. 실제로 업무에 기계학습 알고리즘을 적용할 때 여러 가지 어려움과 맞닥뜨릴 것입니다. 그럴 때에는 상황에 맞는 최선의 알고리즘을 직접 찾아 해결하시는 수밖에 없습니다만, 세상에 할 수 없는 일은 없습니다.
기계학습에 사용할 데이터셋의 분할
우리가 기계학습 알고리즘으로 어떤 모형을 적합한다고 할 때, 전체 데이터를 그대로 사용하는 대신 다음과 같은 두 가지 방법을 통해 여러 개의 데이터셋으로 적당히 나누어 상황에 맞게 사용해야 합니다.
자료분할 (Hold-out Validation)
우리가 보유하고 있는 데이터의 양이 많을 때에는 자료분할 (Hold-out Validation)을 주로 사용합니다. 전체 데이터를 훈련용(training) 데이터셋과 검증용(validation) 데이터셋, 그리고 시험용(test) 데이터셋으로 나눕니다. 세 가지 데이터셋으로 나누는 비중은 분석가가 임의로 정할 수 있습니다.
자료분할을 하는 이유는 훈련용(training) 데이터셋으로 만든 모형에 시험용(test) 데이터셋을 적용하여 모형이 과적합되었는지 여부를 판단하기 위함입니다. 하나의 모형에 대해서는 위와 같이 훈련용, 시험용 데이터셋 두 가지만 필요하지만, 만약 여러 개의 모형을 만들고 그 중에서 최적의 모형을 선택하려면 별도의 검증용(validation) 데이터셋이 필요합니다. 그러니까 훈련용 데이터셋으로 각각의 모형을 적합하고, 검증용 데이터셋을 적용하여 성능이 가장 우수한 모형을 선택한 다음 마지막으로 모형을 적합할 때 사용하지 않은(unseen) 시험용 데이터셋으로 최종모형을 사용할 수 있는지 여부를 판단합니다.
분류모형의 성능 평가는 혼동행렬(Confusion Matrix)의 F1 Score 또는 ROC 커브와 AUROC 값을 기준으로 하는 것이 일반적입니다. 그리고 회귀모형의 성능 평가는 MSE(Mean Squared Error), RMSE(Root Mean Squared Error), MAPE(Mean Absolute Percentage Error) 등 여러 가지가 있습니다. 공통적으로 실제값과 추정값과의 차이인 오차(error)를 기준으로 평가합니다. 각 모형의 성능 평가 기준에 대해서는 별도의 포스팅에서 다루도록 하겠습니다.
 [1]
[1]
교차검증 (Cross Validation)
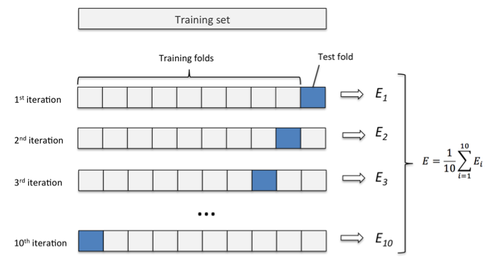
자료분할과 달리 보유하고 있는 데이터의 양이 적을 때 교차검증 (Cross Validation) 방법을 사용합니다. 먼저 전체 데이터를 훈련용(training) 데이터셋과 시험용(test) 데이터셋으로 나눕니다. 그리고나서 훈련용(training) 데이터셋을 k개로 균등하게 다시 나눈 다음, k-1개의 데이터셋으로 모형을 적합하고 나머지 1개의 데이터셋으로 검증합니다. 이 때, 모형 적합에 사용하는 데이터셋을 순차적으로 바꿔가며 k번 반복한다는 특징이 있습니다.
모두 k개의 모형이 만들어지면 검증용 데이터셋으로 목표변수를 추정하고, 그 결과를 합산하여 k로 나눈 평균을 구합니다. 이 평균을 기준으로 해당 모형의 성능을 비교하는 것입니다. 최적의 모형이 선택되면 자료분할과 마찬가지로 시험용 데이터셋으로 최종모형을 사용할 수 있는지 확인합니다. 훈련용 데이터셋을 k개로 균등하게 나눈다는 점에서 K-겹 교차검증 (K-Fold Cross Validation)이라고도 합니다.
 [2]
[2]
이상으로 기계학습 알고리즘의 종류와 데이터셋을 분할하는 방법에 대해 알아보았습니다.
[1] 출처 : http://prog3.com/sbdm/blog/google19890102/article/details/50276693
[2] 출처 : https://sebastianraschka.com/faq/docs/evaluate-a-model.html